多类SVM损失函数(hinge loss)的表达式为:
![]()
公式理解(结合实例):如下图分类为三类 每张图片的多类SVM损失为:不正确的类别评分与正确类别的评分之差加1 (1是安全系数,不重要,因为W的度量是不固定的可能很大)。然后再来与0做比较,取大的值。然后将得到的每张图片的loss求和就得到了多类SVM损失函数
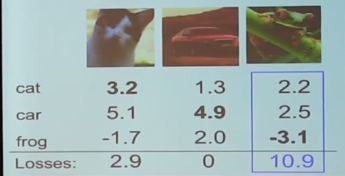
平均的loss:L=(2.9+0+10.9)/3=4.6
理解SVM损失函数为什么有效:当对图片正确分类时,其正确类别评分是最大的,用不正确的类别减去正确类别的评分永远是为负,与0比较大小,得到的loss值为0,就可以理解为正确进行了分类。 反之对图片进行了错误分类时,至少某一个不正确类别评分是最大,用不正确的类别评分减去正确类别的评分再加1,与0比较,得到的损失就为正值,就需要继续训练,减小loss值。
补充:当loss取平均,j=yj(即不仅仅是只计算不正确类-正确类,同时也要用正确类的评分-正确类的评分时。影响是:只是在计算后的最终结果上加上了一个恒定值)对优化的结果都没有什么影响,所以我们不需要求平均loss,也不需要让j=yj。
正则化理解:
对于上面的loss 当loss为0时,我们可以思考此时的权值W是不是唯一的? 显然此时的W不是为1的,例如我们成比例的增加W,此时得到的不正确分类-正确分类的差值+1也只会比原来得到的负值更加的小,与0做比较,得到的结果仍然也为0.最终得到的loss也为0。
所以对于所有能让loss达到最小的W而言,我们希望一部分W是具有优先权的,这一优先权是根据我们想要的W所具有的特点来决定的。由此提出正则化的概念,其实正则化是选择了一个合适的W,为了来权衡我们的训练损失和泛化损失。常见的正则化方式如下:
