《机器学习》笔记---2 模型的损失函数与正则化

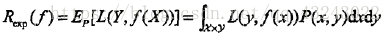
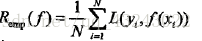
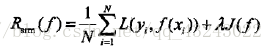
猜你喜欢
转载自blog.csdn.net/qq_43243022/article/details/82956553
今日推荐
周排行