损失函数
定义:
将 W 作为输入,然后查看其得分,之后再定量地估计 W 的好坏,这个函数就是损失函数。
一般将损失函数记为
L_i
最终损失函数 L 是整个数据集中N个样本的损失函数的平均值

作用:
可以定量地衡量任意一个 W 选取对结果的好坏影响,用来帮助我们对 参数W 进行选择。
有一些training data set~训练数据集 x 和 y ,
通常我们说有 N 个样本,其中 x 是算法的输入(图像集中图片每个像素点所构成的数据集),而 y 是希望算法预测出来的东西(标签labels或目标targets)。
则若有10类图像,y的取值可以是(0~9)或者 (1~10)都行。

这就是一个某个W取值的分数结果,
其中对于cat来说并不好,因为分数最高的是car,而非cat。
对于car来说,w选取的还不错,分数最高的就是car。
对于frog来所就很糟糕了,W的选取造成了其中的frog是其中最小的。
SVM~支持向量机
Support Vector Machine
SVM损失函数:
- Hinge Loss ~(铰链损失):主要用于支持向量机(SVM) 中
- Cross Entropy Loss,Softmax Loss ~(互熵损失):用于Logistic 回归与Softmax 分类中
- Square Loss ~(平方损失):主要是最小二乘法(OLS)中
- Exponential Loss ~(指数损失):主要用于Adaboost 集成学习算法中
Hinge Loss

之所以加上1,是因为被证明是一个任意值,因为我们只关心这些分数的相对差值,因为随着W的放大或缩小,之中所有的scores都会相应地方大或缩小。所有选择1并不重要,会在放缩过程中消去。
import numpy as np
def L_i_verctorized(x,y,W):
scores = W.dot(x)
margins = np.maximum(0,scores - score[y] + 1)
loss_i = np.sum(margins)
return loss_i
如上面3个图的例子:

SVM的损失函数只关注正确的分数比比不正确的分数比大1.
改进损失函数
由于我们不关心训练集的表现如何,因为训练集只是用来找到一些分类器,如何用这个分类器引用到测试数据中,而只关心分类器在测试集中的表现。
若参数过多,模型过于复杂,则出现Overfit现象:在训练样本上变相非常好,但在测试样本上却表现很差。应该想办法避免过拟合。

即在尽可能保持拟合程度上对函数进行降幂。 方法有:
- 一种是限制模型,让其边界不要在更高的阶数或模型太过复杂。
- 另一种是加入惩罚项,模型仍然可以逼近复杂模型的效果。即如果想要使用高阶,需要克服这个使用他复杂性的惩罚。
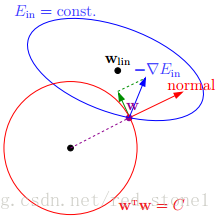
L2的正则化:
过程就是对这个权重向量的欧式范数进行惩罚的过程~
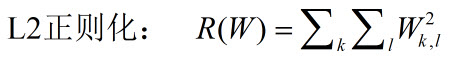
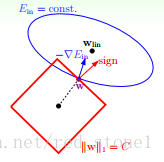
L1的正则化:
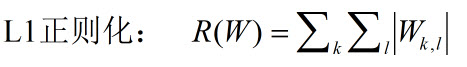
详解见blog
Softmax 分类器
是不同于SVM,将 scores 转换为 离散分布的概率并集中在正确的类上的
scores 被赋予特殊的含义,并用来针对我们的类别去计算概率分布。即用softmax函数经过指数化(以确保为正数),然后由指数化的和再进行归一化。经过这一过程,score 便转换为了 概率分布,于是对于所有的类别都有了相应的概率(介于0和1之间),概率和为1。
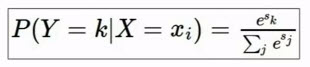
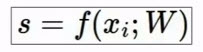
对于某个图像,若我们知道其内容是cat,于是对于目标的概率分布上应该将所有的概率集中在猫上(使得得到猫的概率为1,其他类别的概率为0)。我们要做的就是驱使 Softmax 函数去匹配其所属目标的概率分布,让正确的类别有几乎所有的概率。实现方法有很多,
- 在目标预期的概率分布和计算出来的概率分布之间计算KL散度以比较他们的差异
- 做一个最大似然估计
- 通过取真实类别的概率的对数再取负值来让目标概率尽量接近1.那么针对SVM的损失函数就是 -log P
第三种方法~~则第i个图片的loose:

计算例题:(对于一个属于猫类的图像)
