首先学习二元分类问题(binary classification),y只有0,1两个取值。对于分类问题使用线性回归是一个十分糟糕的选择,因为直线会由于数据因素而无法将样本正确地分类。
因为y∈{0,1}y∈{0,1},我们也希望hθ(x)∈{0,1}所以就选择了:

其中g(z)被称作logistic函数或S型函数(logistic function/sigmoid function),图像为:
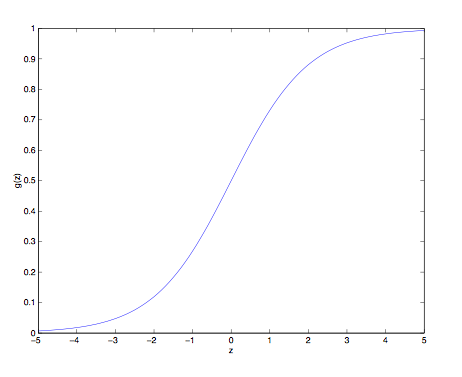
对g(z)求导可得:
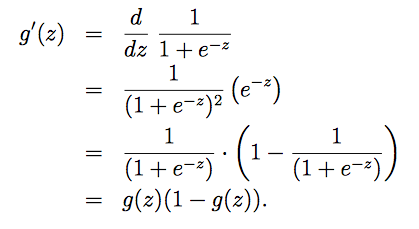
对假设和输出进行概率意义上的解释:

这里使用极大似然估计匹配参数。

我们也可以梯度下降算法来求函数的极值,只不过要将算法中的“-“改为“+“,“下降“改为“上升“,求函数的最大值。
![]()
同样先假设一个训练样本,对函数l(θ)求偏导可得
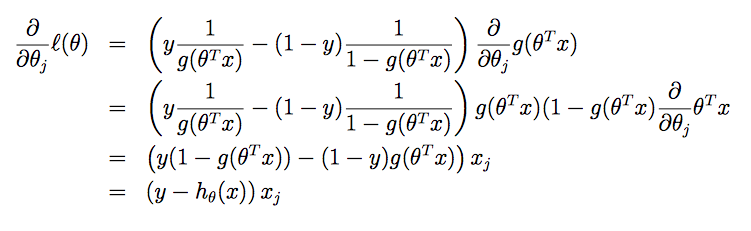
待推导
梯度上升算法的更新原则:

这和上一讲中上一讲的最小二乘法更新规则的表达式一样,但是其中hθ(x)却不同。最小二乘法中的hθ(x)是线性函数,而此表达式中的hθ(x)是logistic函数。