逻辑回归算法是目前机器学习中比较主流的一种分类算法。通常我们指的分类问题都是一个二分类问题,逻辑回归方法也主要是针对二分类问题的。
但是,在实际应用中也存在很多多分类问题,比如我们预测一场足球比赛的结果,这就有胜负平三种可能,也即是三种分类。多分类问题我们将在文末加以说明。
本文介绍了逻辑回归算法的原理,同时在使用sklearn包的情况下运用逻辑回归方法。
算法步骤
逻辑回归问题其实是将回归的思想用于分类问题
Step 1: 通过自变量利用回归分析的思想得到因变量预测值
Step 2: 通过logistic函数(也称Sigmoid函数)将因变量的预测值
一一映射到
区间内,设为
,
其实是分类为正类的概率
Step 3: 设立一个阈值,当
大于阈值时,将其分为正类;否则将其分为负类
详细说明
在Step 1中,我们只需要将自变量和因变量挑出来,对其进行回归分析,得出因变量的预测值
此时,
的取值是一个在
内的数。
在Step 2中,logistic函数为:
其函数图像如下所示:
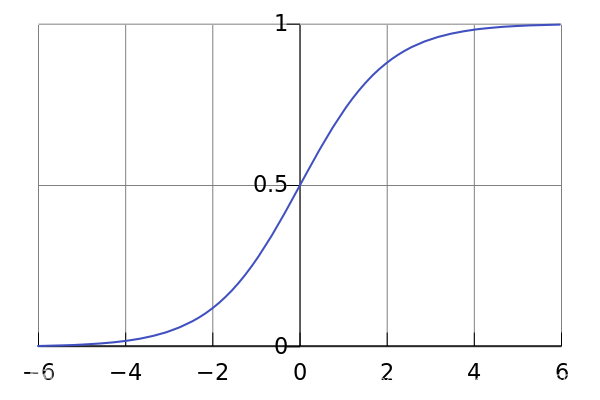
从图像中,我们可以发现这是一个单调递增的函数,其定义域是
,其值域为
,通过logistic函数,我们可以将预测值
从
一一映射到
内。
其中,
表示的是分类为正类的概率。
在Step 3中,我们设立一个阈值(一般都是0.5),当分类为正类的概率大于这个阈值是,我们将其分为正类,当分类这个概率小于0.5时,我们将其分为负类。
当然也会有一些情况这个阈值不取0.5,比如我们要对药物的副作用进行分类(有副作用和无副作用)。这种时候因为若将药物从有副作用误分为无副作用,可能会造成比较恶劣的影响,所以此时阈值一般不取0.5。
多分类问题
多分类的问题可以转化为多个二分类问题。这个思想不仅仅适用于逻辑回归方法,同时也适用于其他任何分类方法。
我们依然以足球比赛的结果作为例子。足球比赛的结果包含胜负平三种,首先我们可以把它分为胜和不胜两类,之后我们在将不胜分为平和负。由此达到多分类的目的。
python实现逻辑回归二分类问题
在本例中,我们使用python自带的鸢尾花数据集,这样比较方便自行实现。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn import datasets
#导入数据
iris = datasets.load_iris()
#区分数据的自变量和因变量
iris_X = iris.data
iris_Y = iris.target
#将数据分成训练集和测试集,比例为:80%和20%
iris_train_X , iris_test_X, iris_train_Y ,iris_test_Y = train_test_split(
iris_X, iris_Y, test_size=0.2,random_state=0)
#训练逻辑回归模型
log_reg = LogisticRegression() #此处这个函数中有很多参数可供选择
log_reg.fit(iris_train_X, iris_train_Y)
#预测
predict = log_reg.predict(iris_test_X)
accuracy = log_reg.score(iris_test_X,iris_test_Y)结果:accuracy = 0.9666667
通过这样的方式就可以简单的使用逻辑回归方法进行分类了。
在LogisticRegression()函数中,有很多参数是可以选择的,具体可以参考LogisticRegression()参数