版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/PeaceInMind/article/details/78689049
FuseText是非常典型的一种工作模式。首先看下框架图,如果看了FPN和FCIS,就会一目了然。
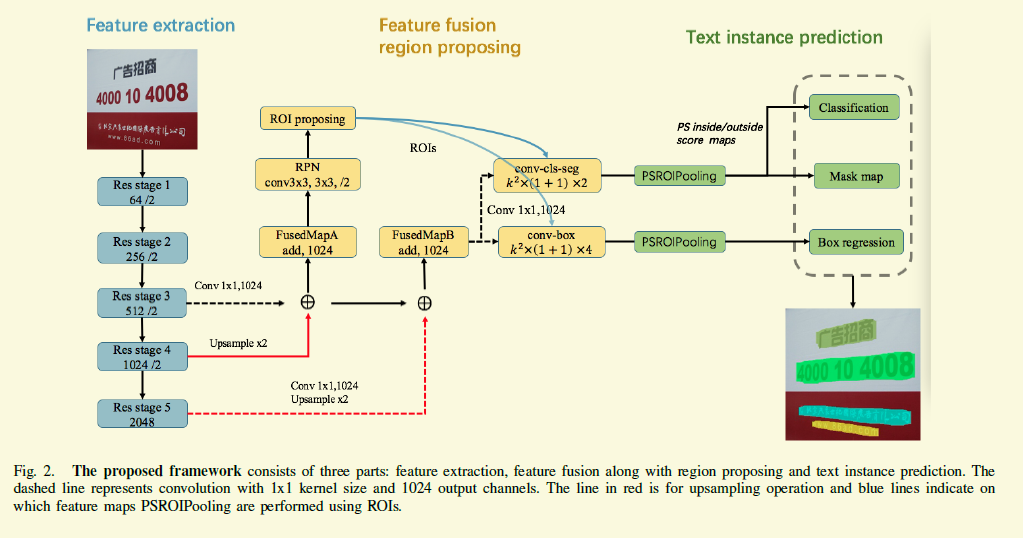
它的架构主要依赖于FCIS,然后个人觉得加强的部分有两点:
1 加入了FPN的思想
2 在更高分辨率的feature map上进行分割。
另外从文字检测的结果上来看,在大量合成数据和Resnet101的加持下,取得了很好的性能,速度方面也能接受,4个FPS.
缺点方面,由于个人做了一段时间scene text的工作,就不负责任地评价下,很有可能不对。
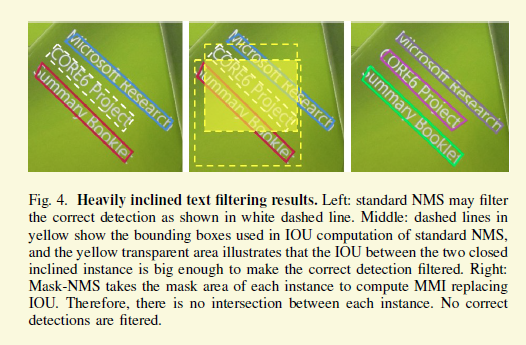
1 文字检测的最终目的还是为了识别,但是不同于物体,文字的框如果定位不准那么识别基本上也不会准,比如911,只框住了91,那能识别对么。 Box regression的缺点在于它的复杂度很高,很多东西需要人工精心设计,比如anchor,损失函数等,所以基本上很难得到比较完美的框,特别是对整行文字进行regression,当然现在很多的其他方法都有这样的问题。整行地做回归是我最不看好的,虽然按照目前的评价标准没什么问题。可以看下图,也是论文放出来的图,有明显的框不全情况。如果用这种框去做识别,也许只能用word classifier这种方式。但是这种方式有明显的缺点,不能识别不在字典的单词,比如数字等。