方法概述
该方法用一个端到端网络完成文字检测整个过程——除了基础卷积网络(backbone)外,包括两个并行分支和一个后处理。第一个分支是通过一个DSSD网络进行角点检测来提取候选文字区域,第二个分支是利用类似于RFCN进行网格划分的方式来做position-sensitive的segmentation。后处理是利用segmentation的score map的综合得分,过滤角点检测得到的候选区域中的噪声。
文章亮点:
(1)不是用一般的目标检测的框架,而是用角点检测(corner point detection)来做。(可以更好解决文字方向任意、文字长宽比很大的文本)
(2)分割用的是“position sensitive segmentation”,仿照RFCN划分网格的思路,把位置信息融合进去(对于检测单词这种细粒度的更有利)
(3)把检测+分割两大类的方法整合起来,进行综合打分的pipeline(可以使得检测精度更高)
主要流程
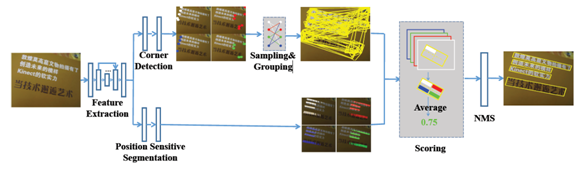
Figure 2. Overview of our method. Given an image, the network outputs corner points and segmentation maps by corner detection and position-sensitive segmentation. Then candidate boxes are generated by sampling and grouping corner points. Finally, those candidate boxes are scored by segmentation maps and suppressed by NMS.
(1)backbone:基础网络(DSSD),用来特征提取(不同分支特征共享)
(2)corner detection:用来生成候选检测框,是一个独立的检测模块,类似于RPN的功能
(3)Position Sensitive Segmentation:整张图逐像素的打分,和一般分割不同的是输出4个score map,分别对应左上、左下、右上、右下不同位置的得分
(4)Scoring + NMS:综合打分,利用(2)的框和(3)的score map再综合打分,去掉非文字框,最后再接一个NMS
网络结构
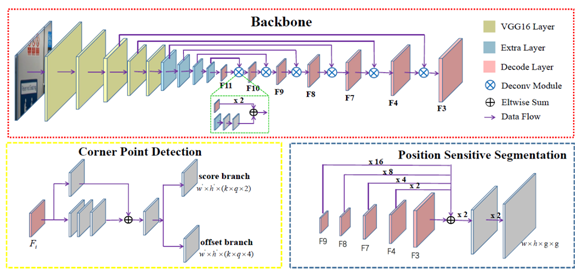
网络包含三个部分:基础网络(backbone)、角点检测和敏感位置分割。
Backbone改编于DSSD;Corner Point Detection建立在多个特征层(粉红色的块)上;Position Sensitive Segmentation与Corner Point Detection共享部分特征(粉红色块)。
实验结果
(1)深度学习框架:PyTorch
(2)实验条件:CPU: Intel(R) Xeon(R) CPU E5-2650 v3 @ 2.30GHz;
GPU: Nvidia Titan Pascal;
RAM: 64GB
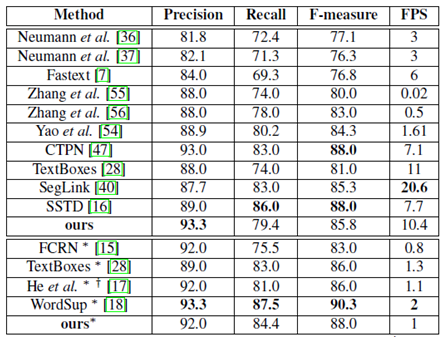
所有表格中,*表示多尺度输入,†表示网络的基础模型不是VGG16
(3)
多尺度(512*512,768*768,768*1280,1280*1280)
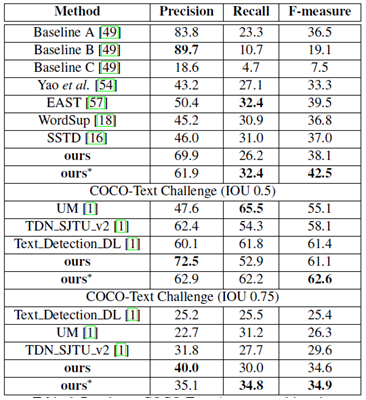
ICDAR2015(倾斜文本)
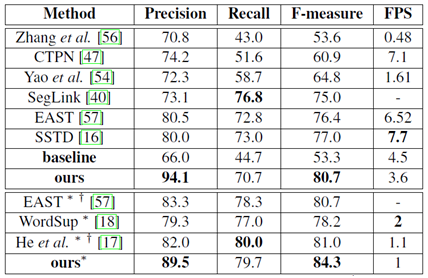
ICDAR2013(水平文本)
MSRA-TD500(倾斜文本行)

MLT(多语言文本)

COCO-Text