论文名称: Learning A Deep Direction Field for Irregular Scene Text Detection
论文原文:原文链接
已有方法回顾
场景文本检测大致分为两类:基于回归的方法和基于分割的方法。
- 基于回归的方法:通过直接回归包含文本的水平/定向矩形或四边形来调整一般物体检测框架以检测文本。缺点:用于检测不规则形状的文本时,性能显着下降,例如弯曲文本。
- 基于分割的方法:文本实例分割。缺点:将单独的文本实例分开是相当困难的。

(a-c)中的经典相对简单的文本表示未能准确地界定不规则文本。(e)中的文本实例使用(d)中的二进制文本掩码表示粘在一起,需要大量的后处理来提取文本实例。 (f)中提出的方向字段能够精确地描述不规则文本实例。
亮点
- 提出的TextField方法非常新颖,用点到最近boundary点的向量来区分不同instance,旨在分割文本并分离相邻的文本实例。
不好的地方:
- 怎么算最近boundary点距离,
- 还有后处理的方法都没办法说清,方法非常新颖,但是,后处理太复杂了
TextField模型
框架

在本文中,采用Instance-segmentation思路,提出了一种名为TextField的新型文本检测器,用于检测不规则场景文本。
具体来说,我们用一个VGG+FPN网络学习一个方向场TextField,该方向场由二维矢量的图像表示。它对二进制文本mask和用于分隔相邻文本实例的方向信息进行编码。
基于网络学习得到的方向场的两张score map图,我们应用基于形态学的后处理来实现最终检测。
方向场
使用方向字段来编码二进制文本mask和可用于分隔相邻文本实例的方向信息。
TextField是一个二维的向量,用来表示分割score map上的每一个点,它的含义是:由每个文本点的最近边界点指向该文本点的向量。它的属性包括:
- 非text像素点=(0, 0),text像素点 不等于(0,0)
- 向量的magnitude,相当于二进制文本掩码,可以用来区分是文字/非文字像素点
- 向量的direction,可以用来进行后处理帮助形成文本块

对于文本实例T内的每个像素p,Np是位于文本实例T之外的距离p最近的像素,然后我们定义由Np指向p的二维单位向量Vgt(p)。该单位向量Vgt(p)直接编码T内部的p的近似相对位置,并突出显示相邻文本实例之间的边界。 对于非文本区域,我们用(0,0)表示那些像素。 方向场用下式给出:

网络架构

Text Field采用的全卷积神经网络分为两个主要部分:特征提取网络和多尺度特征融合。
特征提取网络: VGG16(丢弃最后一个pooling层及其后续全连接层)作为骨干网络,在ImageNet上进行预训练,从而达到特征提取的目的。
多尺度特征融合: 我们利用VGG16骨干网的stage3,stage4和stage5的特征图。 然后将不同尺度的特征resize到与第三层一样的尺寸,然后通过串联合并在一起。 接下来是三个卷积层,产生一个双通道映射,用于预测方向场,最后将预测的方向场resize到原始尺寸大小。
优化和损失函数
1)损失函数
损失函数是每个像素上的均方误差的加权和

其中Vpred是预测方向场,w(p)表示像素p的权重系数。
为了平衡大文本和小文本对损失计算的影响,实施实例平衡策略。对于包含N个文本实例的图像,给定像素p的权重w定义如下:

其中| T |表示文本实例T中的像素总数,Tp表示包含像素p的文本实例。通过这种方式,任何大小的每个文本实例都赋予相同的权重,使得每个文本实例同样重要。
2)在线硬负例挖掘
文本实例通常只占图像的一小部分,因此,文本像素和非文本像素的数量相当不平衡。通过在线硬负例挖掘,解决这一问题。
非文本像素按其每像素损失的递减顺序排序。 然后,仅为前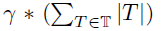 个非文本像素保留用于反向传播,其中γ是给定的超参数,其表示在计算总损失时非文本像素相对于文本像素的总数的比率。
个非文本像素保留用于反向传播,其中γ是给定的超参数,其表示在计算总损失时非文本像素相对于文本像素的总数的比率。
推断和后处理

文本超像素分割
利用方向场Vpred的大小信息生成候选的文本像素。 然后我们依靠Vpred携带的方向信息将候选文本区域分割成文本超像素。
准确地说,对于每个候选文本像素p,方向信息∠Vpred(p)被分成8个方向之一,指向其最近的相邻候选文本像素,表示为P(p),代表像素p的父。 每个候选文本像素指向唯一的相邻像素。 因此,父图像P形成森林结构F,将候选文本区域划分为文本超像素,每个文本超像素由树T∈F表示。可以通过斑点标记算法有效地实现该文本超像素分割(参见第7行 - 算法1中的15)。
文本超像素分组
基于树所代表的文本超像素,我们提出了一种简单的分组方法来形成候选文本实例。 由于所提出的方向场对距离最近边界的方向进行编码,因此所有树的根像素位于每个文本实例的对称轴附近。 由于文本对称的特性,相对于其父母具有大致相反方向的像素也靠近对称轴。 我们将所有这些像素视为所有文本超像素的代表。 文本实例的代表通常彼此接近(见图6)。 我们应用简单的扩张δ(具有3×3结构元素)来对同一文本实例的代表进行分组。 接下来是形成候选文本实例的连通组件标签。 文本超像素分组在算法1的第17-21行中描述。
文本实例过滤
在提取候选文本实例之后,我们应用一些过滤策略来删除一些非文本的形状和大小。如图6所示,文本实例的代表性像素应该具有对称的方向分布。因此,在具有相反方向的意义上,文本实例的所有代表性像素应该近似配对。基于该观察,我们计算未配对代表的比率,并滤除具有低于给定值λr(设置为0.6)的比率的候选文本实例。对于剩余的候选文本实例,我们在非文本像素上应用形态学闭合φ(具有11×11结构元素)以填充内部孔。然后我们还丢弃一些区域小于λa(设置为200)的噪声候选实例。剩余的候选文本实例是最终检测到的文本。文本实例过滤在算法1的第23-27行中给出。

具体而言,所提出的后处理在算法1中详述。该算法的核心体是通过由父母身份图像P编码的森林结构构建文本超像素的斑点标记。该斑点标记过程可以使用堆栈数据结构S和访问的辅助图像。文本超像素由图像L标记。然后,我们通过那些树的根像素和与其父母具有大致相反方向的候选像素来识别代表像素R.这些代表性像素也由图像M存储。然后,将具有核k1×k1(k1 = 3)的扩张δ应用于组代表像素,接着连接标记CC标记以形成候选文本实例。然后,我们按非配对代表过滤不平衡文本的比例过滤掉一些候选文本实例。然后将每个剩余候选文本实例的标签传播到相同文本超像素内的所有像素。最后,我们在非文本像素上应用具有内核k2×k2(k2 = 11)的闭合φ以填充每个候选文本实例内的孔,然后移除小的候选文本实例。此后处理提供由M.编码的最终检测到的文本。
实验
数据集
SCUT-CTW1500:曲文数据集
Total-Text:包含弯曲文本
ICDAR2015:场景文本
MSRA-TD500:主要由矩形或一般四边形的多向文本组成。
SynthText:用于网络的与训练
评估方法
评估参数:precision, recall, and f-measure

TP:正确检测的文本实例的数量
若检测结果与真实的标签相交的IOU大于一个阈值(通常设置为0.5),则判定为正确检测
FP:错误检测的文本实例的数量
FN:漏检的文本实例的数量
实验结果
不同的方法在四个数据集上进行实验,做出对比。


比较有意思的一个实验:用一个数据集来训练,用另外一个数据集来测试,主要是用来说明TextField有很好的泛化能力,

部分典型的实验结果

对于一些比较困难的图像,比如物体遮挡,大字符大间距,类似文本的情况,会出现检测失败的结果。