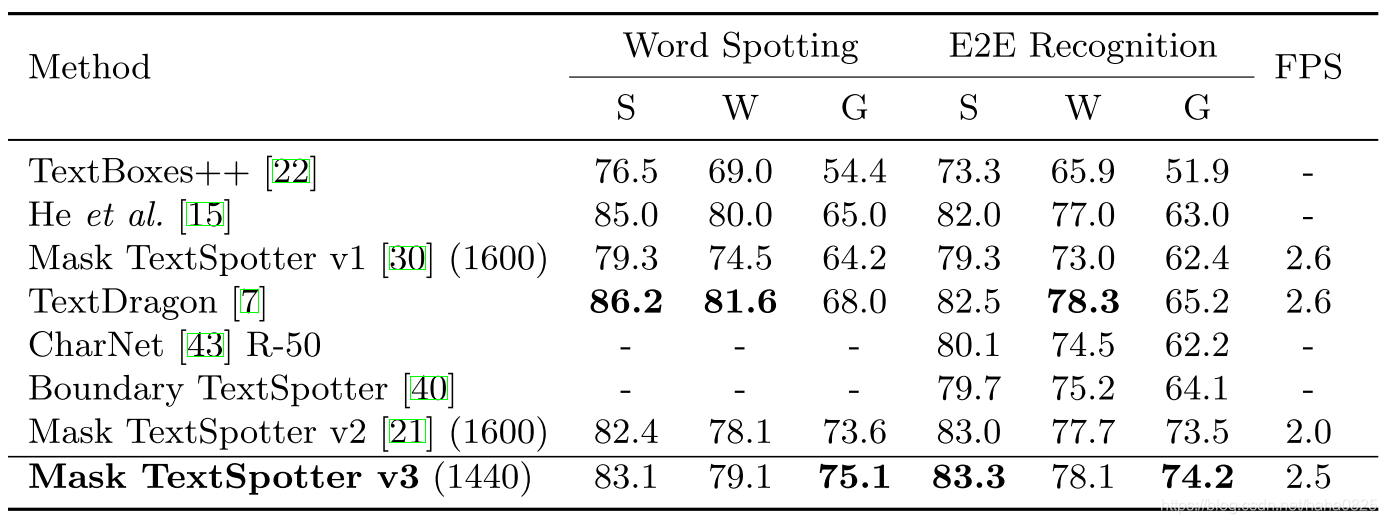
使用SPN代替RPN生成proposal,SPN从分割mask中生成proposal,然后通过Hard RoI masking来从proposal生成RoI特征,比RPN更为精确。
ECCV2020
论文地址:https://arxiv.org/abs/2007.09482
1. 总述
目前大多数端到端文本识别模型都使用RPN来生成proposals,但这样做有两个缺点:
- 严重依赖于人工设计的Anchor,在处理不规则文本实例时存在困难。
- proposals是轴对齐的矩形,在密集文本的情况下通常会将多个相邻文本实例包含在一个proposal中,识别会受到影响。
基于以上问题,本文提出使用SPN代替RPN生成proposals:
- SPN不基于Anchor,而是基于分割mask,所以更加精确,可以处理极端宽高比、不规则的文本实例。
- 精确的proposal可以使得使用mask ROI特征来分离相邻文本实例,使得识别精度不受附近文本或噪声的影响。
下面是RPN和SPN的可视化对比:

2. 总体结构
- V1版本基于mask-rcnn,再加个识别模块;
- V2在V1基础上使用空间注意力进行识别,缓解了字符级标注问题,提高了性能;
- 本文将SPN应用在V2版本上得到本文的V3版本。
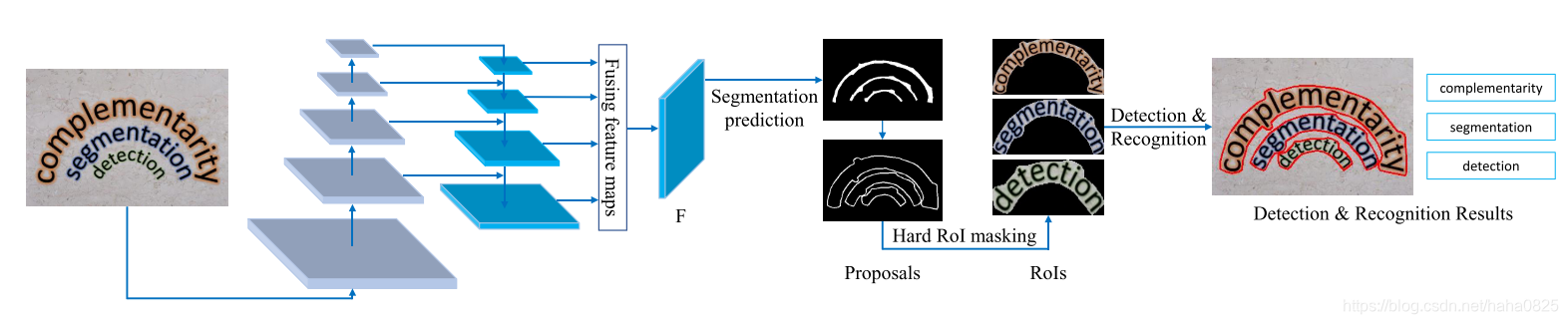 图片输入到SPN的U-Net结构中提取特征,然后融合不同层次的特征进行分割得到F,然后生成proposals,接着使用Hard RoI masking提取proposal特征,然后送入识别网络进行识别。
图片输入到SPN的U-Net结构中提取特征,然后融合不同层次的特征进行分割得到F,然后生成proposals,接着使用Hard RoI masking提取proposal特征,然后送入识别网络进行识别。
3. SPN
特征提取采用U-Net结构,可以对尺度具有鲁棒性。融合不同层次的特征得到的F用于分割预测,然后基于分割mask生成proposals。
3.1 Segmentation label generation
为了分离相邻的文本实例,采用Vatti裁剪算法 [Vatti, B.R.: A generic solution to polygon clipping. Communications of the ACM 35(7), 56–64 (1992)],通过裁剪像素d来缩小文本区域。像素d的offset定义为: d = A ( 1 − r 2 ) / L d=A(1-r^2)/L d=A(1−r2)/L,A和L分别为代表文本区域的面积和周长,r为收缩率(本文设置为0.4)。下面是一个示例:

左:红色和绿色多边形分别是原始注释和收缩区域。
右:分段标签;黑色和白色分别表示0和1的值。
3.2 Proposal generation
给定一个文本分割图S,值的范围在[0,1]之间,然后首先将S二值化为二值图B:
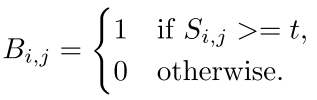
i和j是图的索引,t设置为0.5,得到的B是和S一样的size。
然后将B中的连接区域进行分组。这些连接区域可以被视为收缩文本区域,因为文本分段标签是收缩的,如3.1所述。因此,再使用Vatti剪裁算法通过取消剪裁像素来扩展它们为收缩前的区域,其中 d ^ \hat{d} d^计算为 d ^ = A ^ × r ^ / L ^ \hat{d}=\hat{A} × \hat{r}/\hat{L} d^=A^×r^/L^。这里, A ^ \hat{A} A^和 L ^ \hat{L} L^是预测的收缩文本区域的面积和周长。 r ^ \hat{r} r^对应于收缩率r的值设置为3.0.
3.3 Hard RoI masking
由于自定义RoI Align操作符只支持轴对齐的矩形边界框,因此本文使用多边形proposal的最小、轴对齐的矩形边界框来生成RoI特征,以保持RoI Align操作的简单性。
Qin等人将mask概率图与RoI特征相乘得到RoI mask,但它的mask概率图由mask rcnn生成,不够准确,一个proposal中可能包含多个文本实例。而本文的proposal是精确的多边形,所以可以通过Hard RoI masking从proposal提取RoI特征。
Hard RoI masking将二值多边形mask与RoI特征相乘以抑制背景噪音或相邻文本实例,其中多边形mask M表示轴对齐的矩形二值图,其中多边形区域中的所有值为1,多边形区域之外的所有值为0。
假设 R 0 R_0 R0是RoI特征,M是多边形mask,其尺寸为32×32,则masked RoI特征 R R R可以计算为 R = R 0 ∗ M R=R_0∗M R=R0∗M,其中 ∗ ∗ ∗表示按元素的乘法。通过在多边形proposal区域填充1,同时将多边形外部的值设置为0,可以轻松生成M。
通过使用masked RoI 特征抑制了背景区域或相邻文本实例,降低了检测和识别错误。
3.4 损失函数
SPN使用DICE Loss [Milletari, F., Navab, N., Ahmadi, S.A.: V-net: Fully convolutional neural networks for volumetric medical image segmentation. In: Int. Conf. on 3D Vision. pp. 565– 571 (2016)] ,DICE Loss讲解
假设S和G是分割图和目标图,则分割损失 L s L_s Ls可计算为:
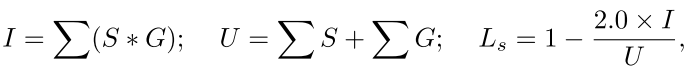
其中I和U表示两个映射的交集和并集,而*表示元素乘法。
4. 实验
只要验证了文本的方向(旋转)鲁棒性、宽高比鲁棒性和形状的鲁棒性。
(1)RoIC13数据集,由旋转IC13中的数据得到,旋转的角度为15,30,45,60,75和90度。

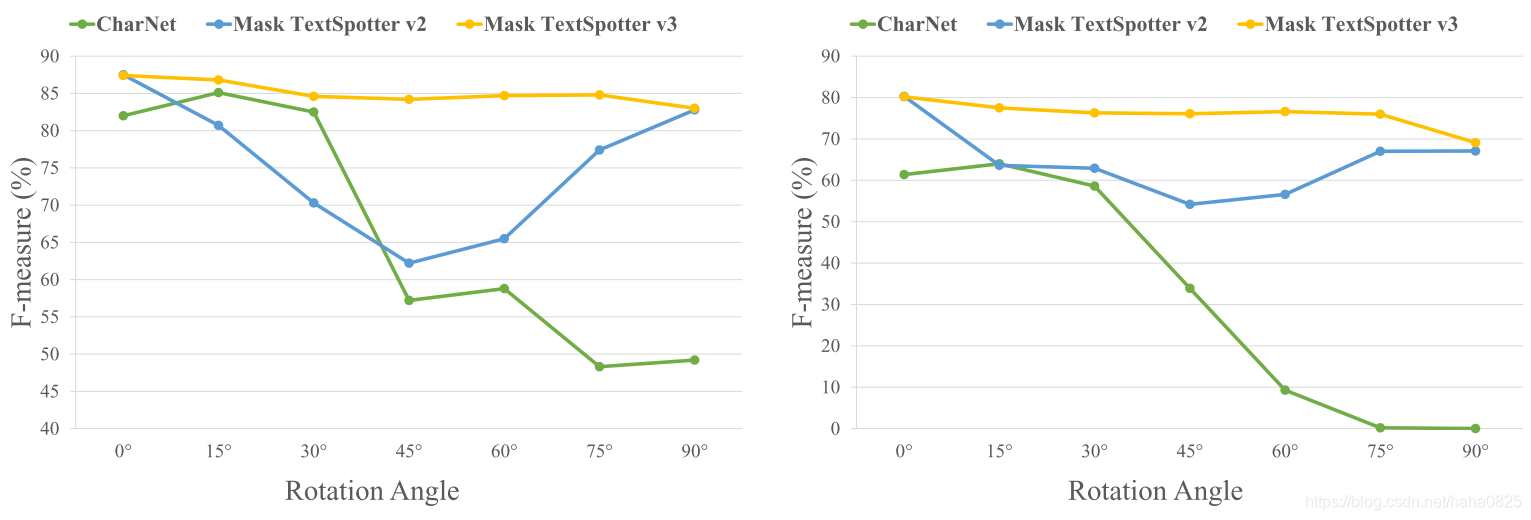
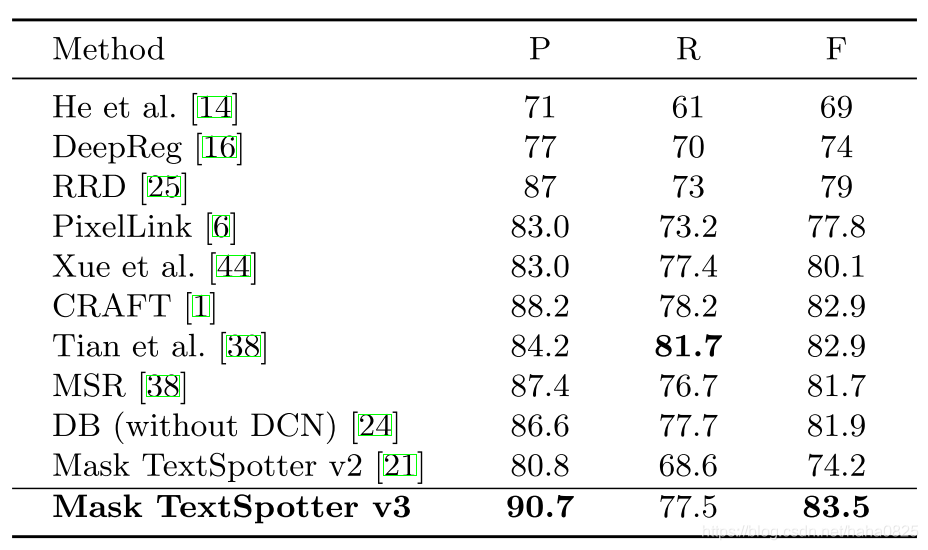
(2)MSRA-TD500数据集,其中的数据宽高比有很多种。
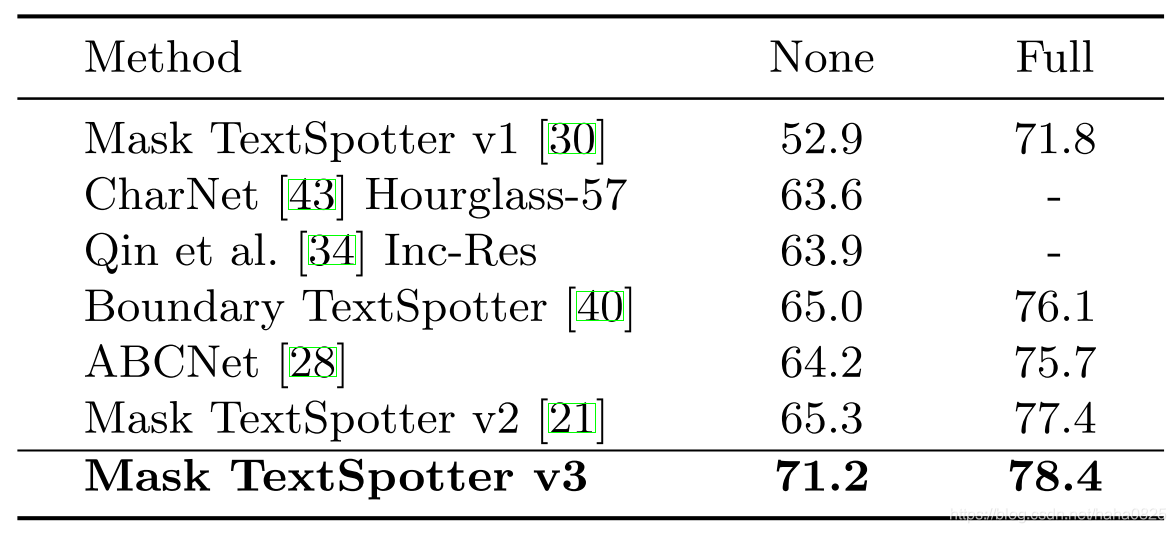
(3)Total-Text数据集,弯曲文本较多。
(4)IC15数据集,小文本较多。