1 概览
EAST是今年文字检测相关论文中本人比较喜欢的一篇,由于已经有大神复现出来了[2],也方便学习。
喜欢的原因主要在结果上,有几点,在没引入额外数据的情况下,效果挺好;用PVA的骨架处理速度相对较快;实验比较全,在COCO-Text上也做了实验。可以改进的地方,在不同的数据库上取得最好效果的是不同的骨架,所以比较有点不太公平。2同样存在框不准的情况,特别是直觉上感觉角度的regression不太靠谱,这一个参数影响太大,不过没做实验就没有发言权,纯属猜测.
从原理上看,主要结合了以下几点
1采用了direct regression.不需要设计anchor或default box,直接进行dense pixel prediction。
2网络架构上结合了U型网络,也融合了像素分割的loss。
2 网络框架
首先看下主网络,还是比较清楚的。从第四个stage逆向连接到stage1.为了减少计算量,每一次特征融合后,都有降channel数的操作,也就是其他文章中的bottleneck.但是按照它这个规律,应该在f1处接个1*1*256和3*3*256,不加的话通道数不对称,f1的影响会大一些,不过这种事情说不清楚,以实验为准。

然后正文部分重点讲解怎么构造回归目标和损失函数。
3 回归目标和损失函数
3.1Indirect regression和 Direct regression
Indirect regression 参考[1],EAST用的是direct regression,所以有必要解释下。一般像faster rcnn,ssd这样的框架都会预设几个或者几十个anchors或者叫defaultbox的框,如下图左边蓝色的虚线框。这些框对于feature map上的任何点都是一样的,但是物体的尺寸千变万化,所以indirect regression方法是在蓝色框的基础上学习绿色框,要学习的内容是相对的位置,考虑到梯度爆炸,收敛性什么的,回归的目标函数和损失函数都是需要仔细设计的,我这菜鸟肯定是设计不来的,能理解就不错了。一般的论文都是套用fast rcnn里面的定义。
Direct regression去掉了anchor,直接对ground truth回归,如右图,回归的目标可以是当前点相对ground truth四个顶点的距离关系,需要8个变量,好处是不用对角度进行回归了,因为角度这个变量实在是太重要了,差之毫厘,谬之千里,缺点是好像只能用smooth L1之类的loss,没有scale不变性。

现在我们具体地来看下EAST的回归目标。由于在ICDAR15中,标注的是斜的四边形,作者尝试了两种方式,一种是去回归四边形,一种使用旋转矩形拟合这个四边形,然后回归这个旋转矩形。根据结果,旋转矩形的结果更好,因此我这里偷下懒,只看旋转矩形。
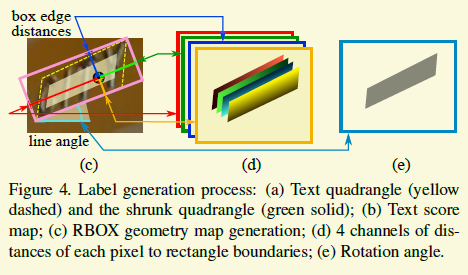
如上图,左边的黄色虚线框表示的groundtruth,粉色的实线框是拟合的旋转矩形。红、蓝、绿、土黄箭头表示的就是是要回归的目标,也就是点到四条边的距离,虽然回归的变量只需要4个,但是还需要回归角度。除了这个,不管是用8个变量还是5个变量都得定义四边形的起始点,以现在EAST代码中采用的方案来说,个人觉得肯定有不足在里面,因为在某个角度范围内,微小变动会导致起始点确定的变化,不是很合理,当然菜鸟更想不到什么解决方案。
3.2 损失定义
3.2.1回归损失
我们还是接着先看回归的损失定义。对于四个距离变量,作者采用的是IOU损失,拥有scale不变性。
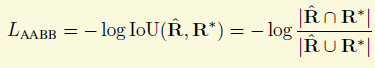
角度的损失是

三角函数能归一到0到1,并且在。
最后回归这部分的损失是由上面两个损失加权相加而成,角度损失的权重是10。在代码实现中,实现者都先用sigmoid输出归一划到(0,1),然后乘以相应的范围,比如位置的范围就是尺寸,而角度比较取巧,所有的文字框都限制在-45到45度范围内,比如一个90度的框也可以用0度代替~
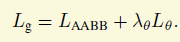
3.2.2 分割损失
上面已经提到EAST用了分割的损失。不过有可能为了鲁棒性考虑,作者并没有把旋转矩形内部所有点作为文字的像素点,猜测原因比如有些单词首字母是大写,其他是小写,那么标注的边缘很多不是文字像素点,另外由于旋转矩形拟合的原因,造成了旋转矩形不能很好地贴紧文字。作者选择了内部一个成比例的框,参考下图浅绿的框。不过感觉是不是把旋转矩形的其他部分标注为not care比较好啊。

损失的定义采用了HED里面比较经典的weighted sample loss,因为负样本比较多,所以正负样本的损失前面加了个系数,该类别样本越多,权重越小。
最后综合的损失有回归损失和分割损失组成,两者权重相等,都是1.
4 最大值抑制
发现现在很多相关的文章都要设计一个自己的NMS。看了代码后感觉不是受到了soft NMS等其他东西的影响,主要原因还是由于回归的不精确造成的,个人觉得这更像是个大的trick,.
[1] He W, Zhang X Y, Yin F, et al. Deep DirectRegression for Multi-Oriented Scene Text Detection[J]. arXiv preprintarXiv:1703.08289, 2017.