
发表时间:2018
论文地址:https://arxiv.org/pdf/1803.01534.pdf
信息在神经网络中的传播方式是非常重要的。在本文中,我们提出了路径聚合网络(PANet),旨在在基于所提出的实例分割框架中促进信息流。具体来说,我们通过自底向上的路径增强,利用底层中的精确定位信号来增强整个特征层次,缩短了下层与最上层特征之间的信息路径。我们提出了自适应特征池化,它将特征网格和所有特征级别连接起来,使每个特征级别上的有用信息直接传播到下面的子网。为每个proposal创建了一个捕获不同视图的互补分支,以进一步改进掩模预测。
这些改进很容易实现,但会带有细微的额外计算开销。我们的PANet在COCO 2017挑战实例分割任务中获得第一名,在目标检测任务中获得第二名。它也是在 MVD和 Cityscapes数据集上最先进模型。
1. Introduction
实例分割是最重要和最具挑战性的任务之一。它的目的是预测类标签和像素级的实例mask,以定位在图像中的不同的实例。这项任务广泛地有利于自动驾驶汽车、机器人技术、视频监控等等。
在深度卷积神经网络的帮助下,提出了几种分割等框架,如[21,33,3,38],其中性能快速增长的[12]。Mask R-CNN [21]是一个简单而有效的实例分割系统。基于快速/更快的R-CNN [16,51],采用全卷积网络(FCN)进行掩模预测,并进行盒回归和分类。为了实现高性能,利用特征金字塔网络(FPN)[35]提取网络内特征层次,其中增强了带有横向连接的自上而下路径,以传播语义强特征。
几个新发布的数据集[37,7,45]为算法的改进提供了很大的空间。COCO [37]由20万张图像组成。在每个图像中都捕获了许多具有复杂空间布局的实例。不同的是,Cityscapes[7]和MVD [45]在每张图片中提供了大量交通参与者的街景。模糊、重遮挡和极小的实例出现在这些数据集中。
在图像分类中设计网络已经提出了几个原则,这些原则对目标识别也很有效。例如,缩短信息路径、使用残差简化信息传播[23,24]和密集的连接[26]是有用的。通过遵循split-transform-merge策略[61,6]创建并行路径来增加信息路径的灵活性和多样性也是有益的。
Our Findings 我们的研究表明,信息传播在最先进的Mask R-CNN可以进一步改进。具体来说,低级别的特性有助于大实例的识别。但是从低级结构到顶层特征的路径很长,增加了获取准确定位信息的难度。此外,每个方案都是基于从一个特征级别汇集的特征网格进行预测的,这是启发式分配的。这个过程可以被更新,因为在其他级别中丢弃的信息可能有助于最终的预测。最后,在单一视图上进行掩模预测,失去了收集更多样化信息的机会。
Our Contributions 受这些原则和观察结果的启发,我们提出了PANet,如图1所示,例如分割。首先,为了利用精确的低级定位信号来缩短信息路径,增强特征金字塔,我们创建了自下而上的路径增强功能。事实上,在[44,42,13,46,35,5,31,14]系统中利用了低层特征。但是没有探索传播低级特征来增强整个特征层次的实例识别。
其次,为了恢复每个proposal和所有特征层之间的中断信息路径,我们开发了自适应特征池。它是一个简单的组件,可以为每个proposal聚合来自所有特性级别的特性,从而避免任意分配的结果。通过此操作,可以创建比[4,62]更干净的路径。
最后,为了捕获每个方案的不同视图,我们使用微小的全连接(fc)层来增强掩模预测,这些层与Mask R-CNN最初使用的FCN具有互补的特性。通过融合这两种观点的预测,信息多样性增加,产生了质量更好的mask。
前两个组件由目标检测和实例分割共同共享,从而大大提高了这两个任务的性能。
Experimental Results 使用PANet,我们在多个数据集上实现了最先进的性能。以ResNet-50 [23]作为初始网络,我们的PANet用单一尺度测试,在目标检测[27]和实例分割[33]任务方面已经优于COCO 2016挑战的冠军。请注意,这些之前的结果是通过更大的模型[23,58]以及多尺度和水平翻转测试来实现的。
我们在COCO 2017挑战实例分割任务中获得第一名,在目标检测任务中获得第二名(模型没有经过大batch训练)。我们还在Cityscapes和MVD上对我们的系统进行了基准测试,这同样会产生顶级的结果,这表明我们的PANet是一个非常实用和性能最好的框架。我们的代码和模型在 https://github.com/ShuLiu1993/PANet 可见
2. Related Work
Instance Segmentation 在实例分割中,主要有两种方法流。最受欢迎的一个方案是基于proposal的方案。该方法的传输流中与目标检测有很强的连接。在R-CNN [17]中,将从[60,68]中获得的object-proposal输入到网络中,提取特征进行分类。而Fast/Faster R-CNN [16,51]和SPPNet [22]则通过汇集全局特征图中的特性,加快了这一过程。早期的工作[18,19]将MCG [1]的mask-proposals作为输入来提取特征,而CFM [9],MNC [10]和Hayder等人[20]将特征池合并到网络中,以获得更快的速度。较新的设计是在网络中生成实例掩码,作为proposal[48,49,8]或最终结果[10,34,41]。Mask R-CNN [21]是属于该流中的一个有效框架。我们的工作是建立在Mask R-CNN的基础上,并从不同的方面进行了改进。
其他流中的方法主要是基于分割的。他们学习了特殊设计的转换[3,33,38,59]或实例边界[30]。然后从预测的转换中解码实例掩码。通过其他pipeline的实例分割也存在。DIN [2]融合了来自目标检测和语义分割系统的预测。在[66,65]中使用了一个图形化模型来推断实例的顺序。在[53,50]中使用RNN在每个时间步中提出一个实例。
Multi-level Features 利用不同层的特征进行图像识别。[49],Peng等人[47]和LRR [14]融合了特征图,以更精细的细节进行分割。FCN [44],U-Net [54]和Noh等人[46]通过跳过连接融合了来自底层的信息。TDM [56]和FPN [35]都增强了一个自上而下的横向连接路径,用于目标检测。与TDM不同的是,TDM采用分辨率最高的融合特征图,SSD [42]、DSSD [13]、MS-CNN [5]和FPN [35]将建议分配到适当的特征级别进行推断。我们以FPN为基线,并大大提高了它。
ION [4],Zagoruyko等人,[62],Hypernet[31]和Hypercolumn[19]连接了来自不同层的特征网格,以更好地预测。但需要一系列的操作,即标准化、连接和降维来获得可行的新特征。与之相比,我们的设计更加简单。
[52]中融合了来源不同的proposal。但该方法在不同尺度的输入图像上提取特征映射,然后进行特征融合(最大操作),以改进对输入图像金字塔的特征选择。相比之下,我们的方法旨在利用网络内特征层次结构中的所有特征层次的信息。启用端到端培训。
Larger Context Region [15,64,62]的方法将每个proposal的特征合并,以利用来自不同分辨率区域的上下文信息。从一个更大的区域汇集出来的特性提供了周围的上下文。在PSPNet [67]和ParseNet [43]中使用了全局池化,极大地提高了语义分割的质量。Peng等人的[47]也观察到了类似的趋势,其中使用了全局卷积。我们的掩码预测分支也支持访问全局信息,但技术却完全不同。
3. Framework
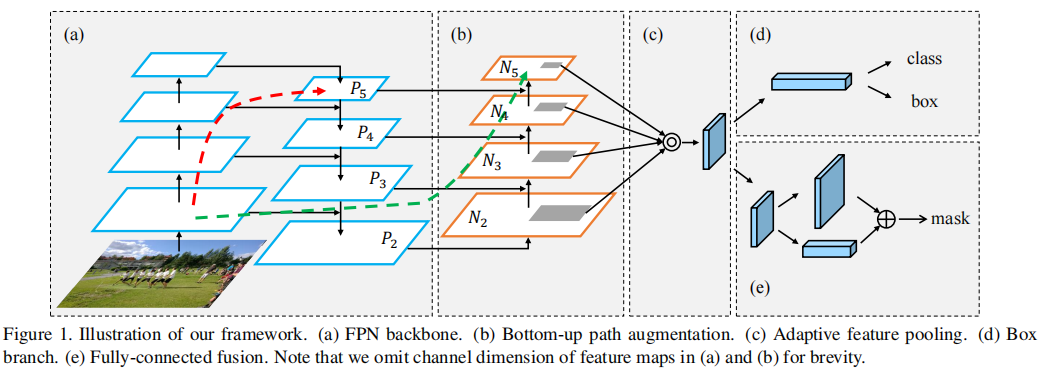
我们的框架如图1所示。为了提高性能,我们进行了路径增强和聚合操作。增强了一个自底向上的路径,使底层信息更容易传播。我们设计了自适应特征池,以允许每个proposal访问来自所有级别的信息以进行预测。在掩模预测分支中添加了一个互补的路径。这种新的结构带来了良好的性能。与FPN类似,该改进是独立于CNN结构的,例如,[57,32,23]。
3.1. Bottom-up Path Augmentation
Motivation 有见地的观点 [63] :神经元在高层强烈响应整个对象,而其他神经元更有可能被局部纹理和图案激活,这表明增加自上而下路径的必要性。在 FPN 中以合理的分类能力传播语义强的特征并增强所有特征。
我们的框架基于对边缘或实例部分的高响应是准确定位实例的有力指标这一事实,通过传播低级模式的强烈响应,进一步增强了整个特征层次结构的定位能力。 为此,我们构建了一条从低层到顶层的具有清晰横向连接的路径。 因此,有一个“捷径”(图 1 中的绿色虚线),由不到 10 层组成,跨越这些层级。 相比之下,FPN 中的 CNN 主干给出了一条长路径(图 1 中的红色虚线),从低层到最顶层穿过甚至 100+ 层。
Augmented Bottom-up Structure 我们的框架首先完成了自下而上的路径扩充。 我们遵循 FPN 来定义处于相同的网络阶段生成具有相同空间大小的特征图的层。 每个特征级别对应一个阶段。 我们还以 ResNet[23] 作为基本结构,使用 {P2, P3, P4, P5} 来表示 FPN 生成的特征级别。 我们的增强路径从最低层 P2 开始,逐渐接近 P5,如图 1(b) 所示。 从 P2 到 P5,空间大小以因子 2 逐渐下采样。我们使用 {N2, N3, N4, N5} 来表示对应于 {P2, P3, P4, P5} 的新生成的特征图。 请注意,N2 只是 P2,没有任何处理。
如图 2 所示,每个构建块通过横向连接获取更高分辨率的特征图 Ni 和更粗糙的图 Pi+1,并生成新的特征图 Ni+1。 每个特征图 Ni 首先经过一个步长为 2 的 3×3 卷积层以减小空间大小。 然后通过横向连接将特征图Pi+1的每个元素与下采样图相加。 然后融合特征图由另一个 3 × 3 卷积层处理以生成 Ni+1 用于后续子网络。 这是一个迭代过程,在接近 P5 后终止。 在这些构建块中,我们始终使用特征图的通道 256。 所有卷积层后面都是 ReLU [32]。 然后每个proposal的特征网格是从新的特征图池化,即{N2,N3,N4,N5}。

3.2. Adaptive Feature Pooling
Motivation 在FPN [35]中,proposals根据proposals的大小被分配到不同的特性级别。它将小proposals分配给低特性级别,将大proposals分配给高特性级别。虽然简单而有效,但它仍然可以产生非最优的结果。例如,两个具有10像素差异的proposals可以被分配到不同的级别。事实上,这两个proposals相当相似。
此外,特征的重要性可能与它们所属的级别没有很强相关性。高级特性由大的接受域生成,并捕获更丰富的上下文信息。允许小proposal访问这些特性,更好地利用有用的上下文信息进行预测。同样,低级别的特征具有许多精细的细节和较高的定位精度。让大proposal获得它们显然是有益的。有了这些想法,我们建议为每个proposal汇集各个层级的特征,融合它们以进行后续预测。我们称这种过程为自适应特征池。
我们现在用自适应特征池分析不同级别特征的比率。我们使用最大操作来融合不同层次的特征,这让网络选择元素级有用的信息。我们根据最初在FPN中分配的级别将proposals聚为四个类。对于每一组proposal,我们计算从不同级别中选择的特征的比例。在符号中,级别1−4代表从低到高的级别。如图3所示,蓝线表示最初在FPN中被分配给级别1的小proposal。令人惊讶的是,近70%的功能来自其他更高的层次。我们还使用黄线来表示在FPN中被分配到第4级的大proposal。同样,50%的+是来自其他较低级别的特性。这一观察结果清楚地表明,多个层次的特征一起有助于准确预测。这也是设计自下而上路径增强的有力支持。

Adaptive Feature Pooling Structure 自适应特性池实际上在实现中很简单,如图1©.所示首先,对于每个proposal,我们将它们映射到不同的特征级别,如图1(b).中的深灰色区域所示在Mask R-CNN [21]之后,使用ROIAlign来汇集每个级别的特征网格。然后利用融合操作(元素级的最大值或和)来融合来自不同层次的特征网格。
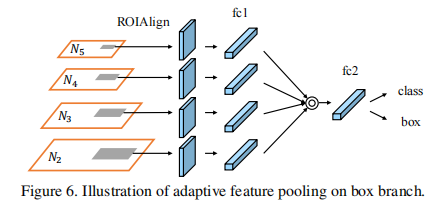
在接下来的子网络中,合并的特征网格独立经过一个参数层,然后进行融合操作,使网络能够适应特征。例如,在FPN中的box分支中有两个fc层。我们在第一层之后应用融合操作。由于在Mask R-CNN的掩模预测分支中使用了四个连续的卷积层,因此我们将融合操作放置在第一层和第二层卷积层之间。消融研究报告详见第4.2节。融合特征的网格作为每个proposal的特征网格,用于进一步的预测,即分类、盒回归和掩模预测。图6显示了在方框分支上的自适应特性池的详细说明。
我们的设计侧重于融合来自网络特征层次的信息,而不是来自输入图像金字塔[52]的不同特征图的信息。与需要L-2归一化、串联化和降维的[4,62,31]过程相比,它更简单。
3.3. Fully-connected Fusion
Motivation 全连接层或MLP被广泛应用于实例分割[10,41,34]和掩模proposals生成[48,49]中的掩模预测。[8,33]的结果表明,FCN也能够预测像素级掩模。最近,Mask R-CNN [21]在合并特征网格上应用了一个微小的FCN来预测相应的掩模,避免了类之间的竞争。
我们注意到,与FCN相比,fc层产生不同的属性,后者基于局部接受域对每个像素进行预测,并且参数在不同的空间位置共享。相反,fc层是位置敏感的,因为不同空间位置的预测是通过不同的参数集来实现的。所以它们有能力适应不同的空间位置。同时,利用整个proposal的全局信息对每个空间位置进行预测。它可以帮助区分实例[48]和识别属于同一对象的不同部分。给定fc层和卷积层的性质不同,我们融合了这两种层的预测,以更好地进行掩模预测。
Mask Prediction Structure 我们的掩模预测组件是轻权重的,易于实现。掩码分支会对每个proposal的池化特征网格进行操作。如图4所示,主路径为一个小的FCN,它由4个连续的卷积层和1个反卷积层组成。每个卷积层由256个3×3的滤波器和倍数为2的反卷积层上采样组成。它为每个类独立地预测一个二值像素级掩码来解耦分割和分类,类似于Mask R-CNN。我们还创建一个从图层conv3到fc图层的短路径。有两个3×3卷积层,第二个层将通道缩小到一半,以减少计算开销。
一个fc层用于预测一个类别不可知的前景/背景mask。它不仅是有效的,而且允许参数在fc层中训练更多的样本,从而导致更好的通用性。我们使用的掩模大小是28×28,因此fc层产生一个784×1×1向量。这个向量被重塑为与FCN预测的掩模相同的空间大小。为了获得最终的掩模预测,我们添加了FCN中的每个类的掩模和fc中的前景/背景预测。只使用一个fc层,而不是多个,来进行最终的预测,可以防止将隐藏的空间特征图压缩成一个短的特征向量,从而丢失空间信息。
4. Experiments
我们将我们的方法与在具有挑战性的COCO [37]、Cityscapes[7]和MVD [45]数据集上的最先进技术进行了比较。我们的研究结果在所有这些研究结果中都排名第一。对COCO数据集进行了综合消融研究。我们还展示了我们关于COCO 2017实例分割和对象检测挑战的结果。
4.1. Implementation Details
我们基于Caffe [29]重新实现了Mask R-CNN和FPN。我们在实验中使用的所有预先训练过的模型都是公开的。我们采用以图像为中心的训练[16]。对于每张图像,我们对512个正负比为1: 3的感兴趣区域(roi)进行采样。权重衰减为0.0001,动量设置为0.9。其他的超参数根据数据集的不同而略有不同,我们在各自的实验中详细说明了它们。在Mask R-CNN之后,proposal来自一个独立训练的RPN [35,51],以方便的消融和公平的比较,即主干不与目标检测/实例分割共享。
4.2. Experiments on COCO
Dataset and Metrics 由于数据的复杂性,COCO [37]数据集是分割和目标检测等中最具挑战性的数据集之一。它包括11.5k用于训练的图像和5k用于验证的图像(2017年的新拆分)。20k图像用于测试开发,20k图像用于测试挑战。test-challenge 和 test-dev的GT标签都是不公开的。它具有80个类别的像素级实例分割数据。我们在train-2017子集上训练了我们的模型,并报告了val-2017子集的消融研究结果。我们还报告了测试开发的结果以进行比较。
我们遵循标准的评价指标,即AP、AP50、AP75、APS、APM和APL。最后三个测量了不同尺度的物体的性能。由于我们的框架对实例分割和目标检测都很通用,所以我们也训练独立的对象检测器。我们报告了mask AP、独立训练的目标检测器的 a p A P b b ap AP^{bb} apAPbb,以及以多任务方式训练的目标检测分支的 A P b b M AP^{bbM} APbbM。
Hyper-parameters 我们训练图像的batch size为16。 图像的短边和长边是 800 和 1000,如果没有特别说明的话。 例如分割,训练我们的模型,学习率为 0.02 进行 120k 迭代,0.002 进行另外 40k 迭代。 对于目标检测,我们训练了一个没有掩码预测分支的目标检测器。 目标检测器经过 60k 次迭代训练,学习率为 0.02,另外 20k 次迭代,学习率为 0.002。 这些参数是从 Mask R-CNN 和 FPN 中采用的,没有经过任何微调。
Instance Segmentation Results 我们报告了我们的PANet在测试开发上的性能,有和没有多尺度训练进行比较。如表1所示,我们的ResNet-50 panet在多尺度图像上训练,在单尺度图像上测试,在2016年已经优于Mask R-CNN和Chipon,后者使用了更大的模型集成和测试技巧[23,33,10,15,39,62]。训练和测试的图像大小为800,与Mask R-CNN相同,我们的方法在相同的初始模型下优于单模型最先进的Mask R-CNN近3个点。

Object Detection Results 与Mask R-CNN中采用的方法类似,我们也报告了从框分支推断出的边界框结果。表2显示,我们使用ResNet-50的方法在单尺度图像上进行训练和测试,即使使用更大的ResNeXt-101 [61]作为初始模型,也大大优于所有其他单模型。通过多尺度训练和单尺度测试,我们使用ResNet-50的PANet在2016年超过了冠军,后者使用了更大的模型集成和测试技巧。
Component Ablation Studies 首先,我们分析了每个被提出的组件的重要性。除了自底向上路径的增强、自适应特征池和全连接融合外,我们还分析了多尺度训练、多gpu同步批归一化[67,28]和更重的头部。对于多尺度训练,我们将较长的边设置为1400,另一个边的范围从400到1400。当使用多gpu同步批处理归一化时,我们基于所有gpu中的所有样本计算平均值和方差,在训练过程中不固定任何参数,并在所有新层之后建立一个批处理归一化层。较重的头部使用4个连续的3×3个卷积层,由盒子分类和盒子回归共享,而不是两个fc层。它类似于在[36]中使用的头部,但是用于盒子分类和盒子回归分支的卷积层在它们的情况下并不共享。
我们从基线逐渐到纳入的所有成分的消融研究是在val-2017子集上进行的,如表3所示。ResNet-50 [23]是我们的初始模型。我们报告了mask AP、独立训练的目标检测器的box AP和多任务训练的盒子分支的box-mask AP的性能。

1) Re-implemented Baseline. 我们重新实现的Mask R-CNN的性能与原始论文中描述的相当,而且我们的目标检测器的性能更好。
2) Multi-scale Training & Multi-GPU Sync. BN. 这两种技术有助于网络更好地收敛,提高了泛化能力。
3) Bottom-up Path Augmentation. 使用或不使用自适应特征池,自下而上路径增强持续将掩码AP和box ap APbb分别提高0.6和0.9以上。对大规模实例的改进是最为显著的。这验证了来自较低特性级别的信息的有效性。
4) Adaptive Feature Pooling. 无论是否使用自底向上的路径增强,自适应特性池都能持续地提高性能。根据我们的观察,所有尺度的性能通常都会提高,这是一致的,即其他层的特征在最终预测中都很有用。
5) Fully-connected Fusion. 全连接融合的目的是预测质量更好的mask。它在mask AP方面有了0.7%的改进。它通常适用于所有尺度上的实例。
6) Heavier Head. 重头对多任务方式中box AP的训练是非常有效的。而对于mask AP和独立训练的目标检测器,改进幅度较小。
对于PANet中的所有这些组件,掩模AP的改进比基线高出4.4。独立训练的对象检测器的Box ap APbb增加了4.2。他们是很重要的。中小型实例的贡献最大。一半的改进来自于多尺度训练和多GPU同步。BN,这是帮助训练更好的模型的有效策略。
Ablation Studies on Adaptive Feature Pooling 我们对自适应特征池进行了消融研究,以寻找融合操作的位置和最适合的统合操作。我们把它放在ROIAlign和fc1之间,用“fu.fc1fc2”表示,或者放在fc2之间,fc1和fc2用“fc1fu.fc2”表示,具体如表4所示。类似的设置也应用于掩码预测分支。对于特征融合,测试了max运算和sum运算。

如表4所示,自适应特征池对融合操作不敏感。然而,允许一个参数层来适应来自不同级别的特征网格是非常重要的。我们使用max作为融合操作,并在我们的框架中的第一个参数层后面使用它。
Ablation Studies on Fully-connected Fusion 我们用不同的方法来实例化增强的fc分支来研究性能。我们考虑了两个方面,即启动新分支的图层和融合来自新分支和FCN的预测的方法。我们分别从conv2、conv3和conv4创建新的路径。“max”、“sum”和“product”操作用于核聚变。我们以具有自底向上的路径增强和自适应特征池的重新实现的掩码R-CNN为基线。相应的结果如表5所示。他们清楚地表明,从conv3开始凝视并取和进行融合会产生最好的结果。
COCO 2017 Challenge 通过PANet,我们参与了COCO 2017年实例分割和对象检测挑战。我们的框架在没有大批量训练的实例分割任务中排名第一名,在对象检测任务中排名第二名。如表6和表7所示,与去年的冠军相比,我们在实例分割上实现了9.1%的绝对改进和24%的相对改进。而对于目标检测,绝对提高9.4%,相对提高23%。
顶级性能包括PANet中的更多细节。首先,我们使用可变形卷积。更多的训练细节包含:采用了多尺度测试、水平翻转测试、掩模投票、箱形投票等方法。对于多尺度测试,我们在前200个step中将较长的边设置为1400,其他范围从600到1200。只使用了4个尺度。其次,我们使用公开提供的、更大的初始模型。我们使用3个ResNeXt-101(64×4d)[61],2个SE-ResNeXt-101(32×4d)[25],1个ResNet-269 [64]和1个SENet [25]作为边界盒和掩模生成的集合。不同较大初始模型的性能是相似的。一个ResNeXt-101(64×4d)被用作生成提案的基本模型。我们用不同的随机种子训练这些模型,有或没有平衡抽样[55],以增强模型之间的多样性。我们提交的检测结果是通过收紧实例掩模获得的。我们在图5中展示了一些可视化的结果——我们的大多数预测都是高质量的。
4.3. Experiments on Cityscapes
Dataset and Metrics Cityscapes[7]包含了由车载摄像头捕捉到的街景。有2975张训练图像,500张验证图像和1525张具有精细注释的测试图像。另外2万张图像带有粗糙的注释,不包括训练在内。我们报告了我们在val和test子集上的结果。8个语义类用实例掩码进行了注释。每张图像的大小为1024×2048。我们基于AP和AP50来评估结果。
Hyper-parameters 我们使用与Mask R-CNN [21]中相同的超参数集来进行公平的比较。具体来说,我们使用从{800,1024}中随机抽取的具有较短边缘的图像进行训练,并使用具有较短边缘1024的图像进行推理。没有使用测试技巧或DCN。我们对我们的模型进行18k次学习率为0.01的迭代,另外6k次学习率为0.001的迭代。8个图像(每个GPU1个图像)在一个图像批处理中。采用ResNet-50作为该数据集的初始模型。
Results and Ablation Study 我们对表8中的test子集进行了技术比较。在“仅精细”数据上进行训练后,我们的方法在“finy-only”数据上比Mask R-CNN多出5.6分。它甚至可以与COCO预训练的Mask R-CNN相媲美。通过对COCO的预训练,我们在相同的设置下比Mask R-CNN多出4.4分。可视化结果如图5所示。
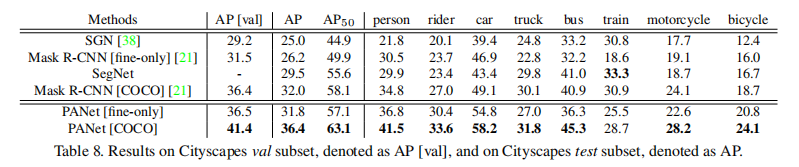
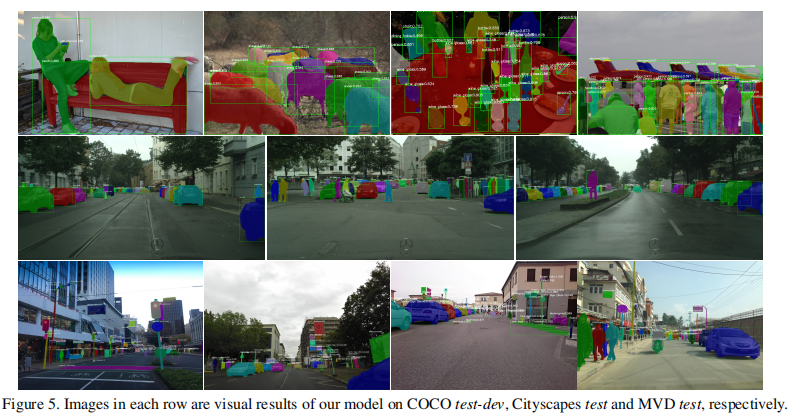
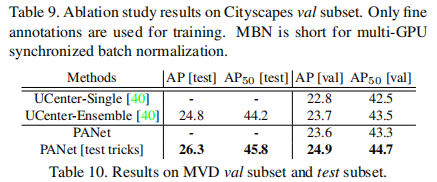
表9给出了我们分析val子集改善情况的消融研究。基于我们重新实现的基线,我们添加了多gpu同步批归一化,以帮助网络更好地收敛。它将精度提高了1.5分。有了我们的PANet,性能进一步提高了1.9个百分点。
4.4. Experiments on MVD
MVD [45]是一个相对较新的、大规模的实例分割数据集。它提供了25,000张街景图像,并为37个语义类提供了精细的实例级注释。它们被使用不同的设备从几个国家被捕获。其内容和分辨率差别很大。我们以ResNet-50作为初始模型,在训练子集上训练我们的模型,并报告了根据AP和AP50在val和秘密测试子集上的性能。
我们在表10中展示了我们的结果。与UCenter [40]在LSUN 2017实例分割挑战的赢家数据集相比,我们的PANetResNet-50已经与COCO预训练的集成结果进行了比较。UCenter也采用了多尺度和水平翻转测试,我们的方法性能更好。定性结果如图5所示。
5. Conclusion
我们已经在实例分割上展示了我们的PANNet。我们设计了几个简单而有效的通信组件,以增强在具有代表性的管道中的信息传播。我们汇集了所有特征级别的特征,并缩短了较低和最上层特征之间之间的距离,以实现可靠的信息传递。增强了互补路径,以丰富每个方案的特性。产生了令人印象深刻的结果。我们未来的工作将是将我们的方法扩展到视频和RGBD数据。
Appendix
A. Training Details and Strategy of Generating Anchors on Cityscapes and MVD.
在Cityscapes[7]上,训练超参数遵循了Mask R-CNN [21],并在第4.3节中进行了描述。RPN锚跨越5个尺度和3个长宽比。在MVD [45]上,我们采用了获胜选手[40]的训练超参数。我们用60k迭代训练0.02,用0.002迭代训练我们的模型。我们在一个图像批中拍摄16张图像进行训练。我们将输入图像的较长边缘设置为2400像素,其他范围设置为600到2000像素,用于多尺度训练。多尺度测试采用尺度{1600、1800、2000}。RPN锚点跨越7个尺度,即{ 8 2 、 1 6 2 、 3 2 2 、 6 4 2 、 12 8 2 、 25 6 2 、 51 2 2 8^2、16^2、32^2、64^2、128^2、256^2、512^2 82、162、322、642、1282、2562、5122}和5个高宽比,即{0.2、0.5、1、2、5}。RPN的训练规模与目标检测/实例分割网络训练的规模相同。
B. Details on Implementing Multi-GPU Synchronized Batch Normalization.
我们在Caffe [29]和OpenMPI上实现了多gpu批处理标准化。给定B批中的n个GPU和训练样本,我们首先将训练样本平均分成n个子批,每个子批表示为bi,分配给一个GPU。在每个GPU上,我们基于bi中的样本计算均值µi。然后应用AllReduce操作来收集所有gpu上的所有µi,以获得整个批b的平均µB。µB被广播到所有gpu。然后,我们独立地计算每个GPU的临时统计量,并应用AllReduce操作来产生整个批B的方差 σ B 2 σ^2_B σB2。 σ B 2 σ^2_B σB2也被广播给所有的GPU。因此,每个GPU都有计算出的对B中所有训练样本的统计量。然后我们对于每个训练样本执行标准化 y m = γ x m − μ B σ B 2 + ϵ + β y_m=\gamma \frac{x_{m}-\mu_{B}}{\sqrt{\sigma_{B}^{2}+\epsilon}}+\beta ym=γσB2+ϵxm−μB+β。在反向操作中,AllReduce操作同样用于从所有gpu中收集信息以进行梯度计算。