本周内容:浅层神经网络
1. 神经网络概览:
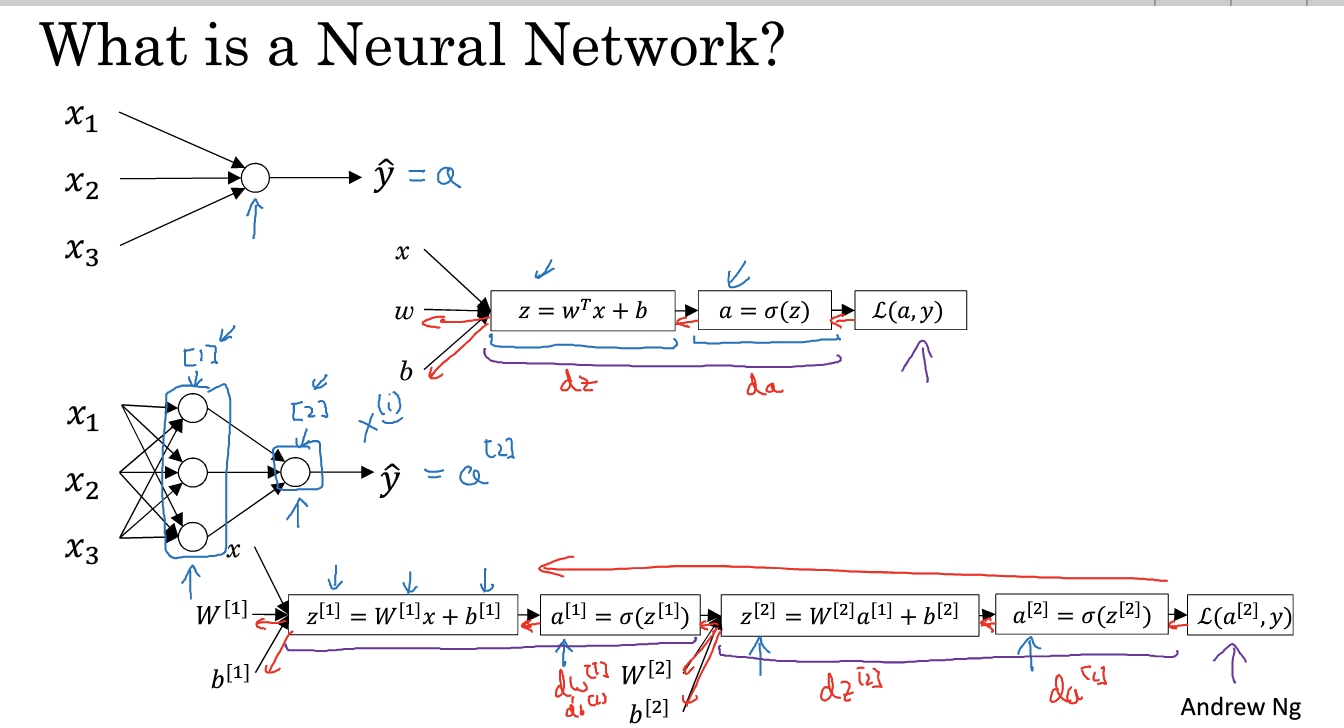
如图所示为一个简单的神经网络正向传播和反向传播的示意图,对于输入x,结合w and b得到z,进而得到a=sigmoid(z),再和w and b 得到z,得到a2(也是结果)。
2. 神经网络的表示:
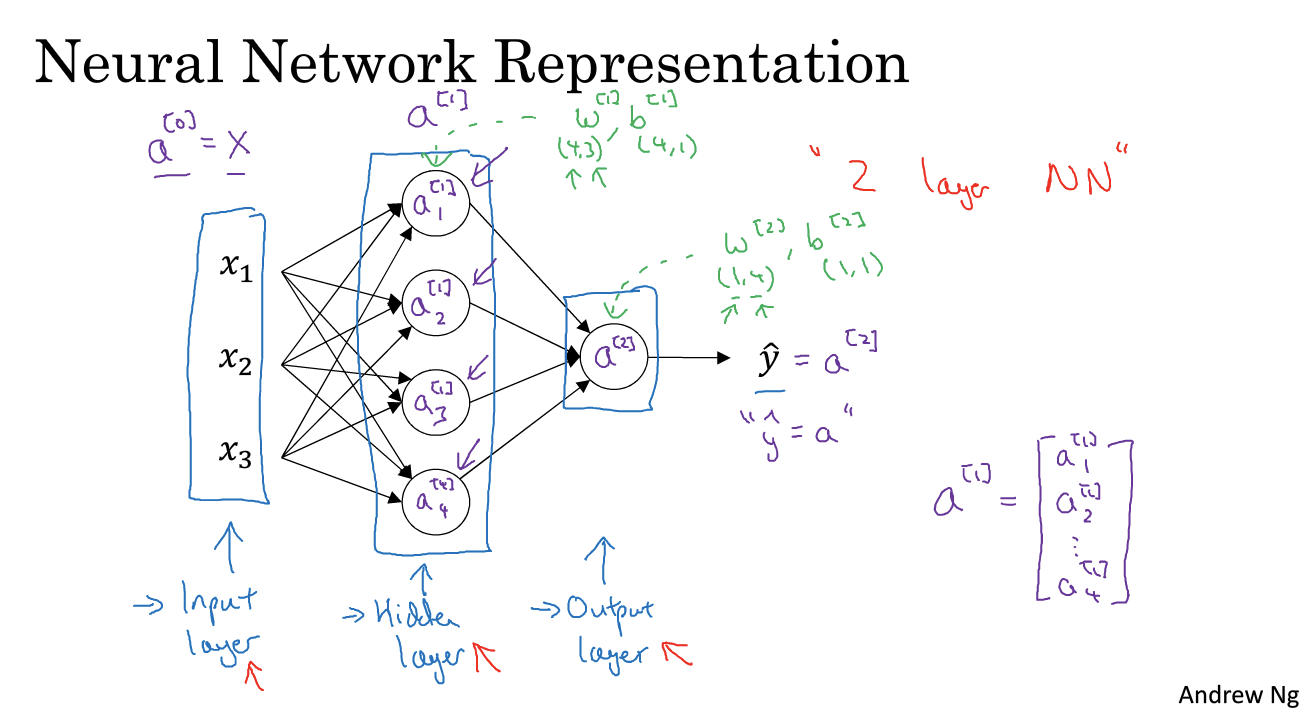
神经网络分为三层:input/hidden/output layer
为什么称为hidden layer:在训练集中无法“看到”
输入层x也叫a[0](上标),activation表示这些值会传递给下一层。
在计算网络的层数中,不计算输入层
隐藏层和输出层是带有参数的(w and b)
3. 计算一个神经网络的输出
各个参数上标表示层数,下标表示对应层的第几个节点
如何向量化参数以及如何用四行代码写出输出:
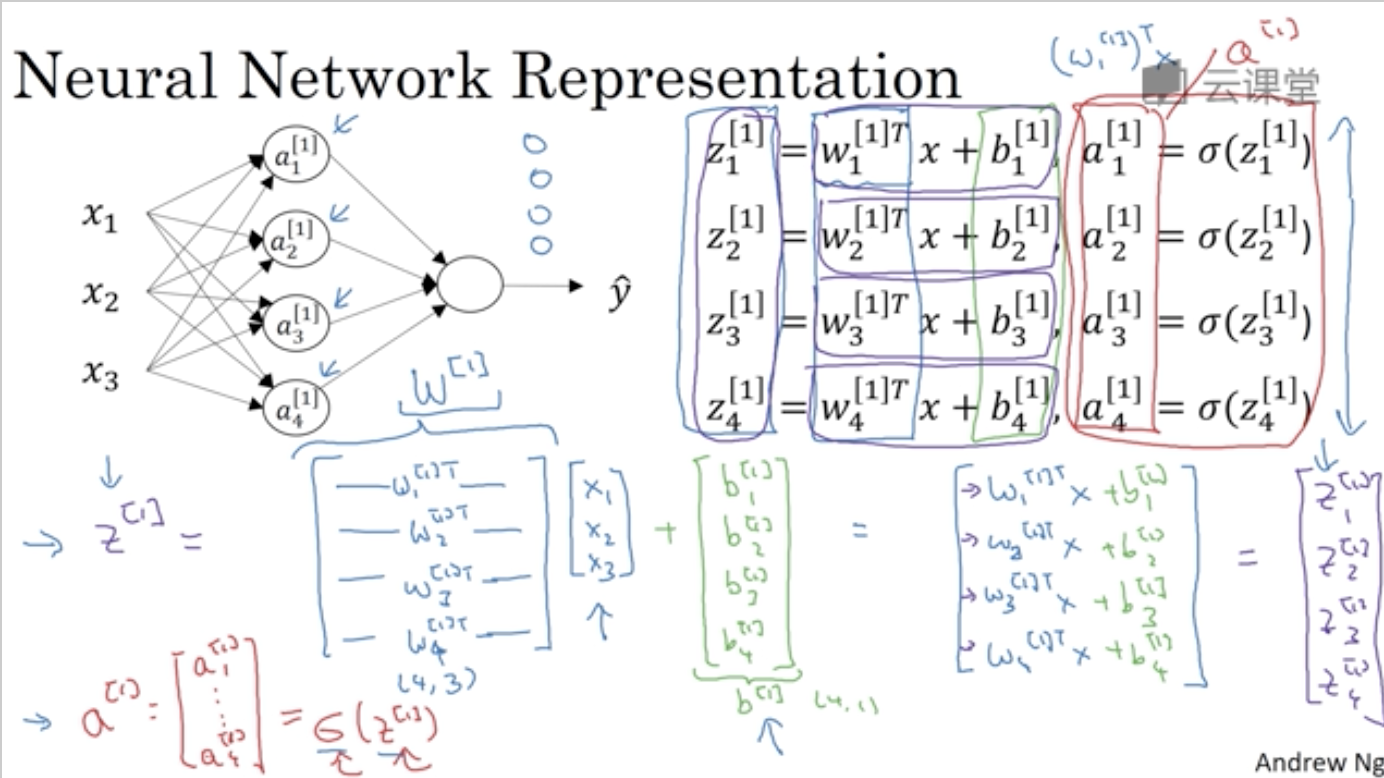
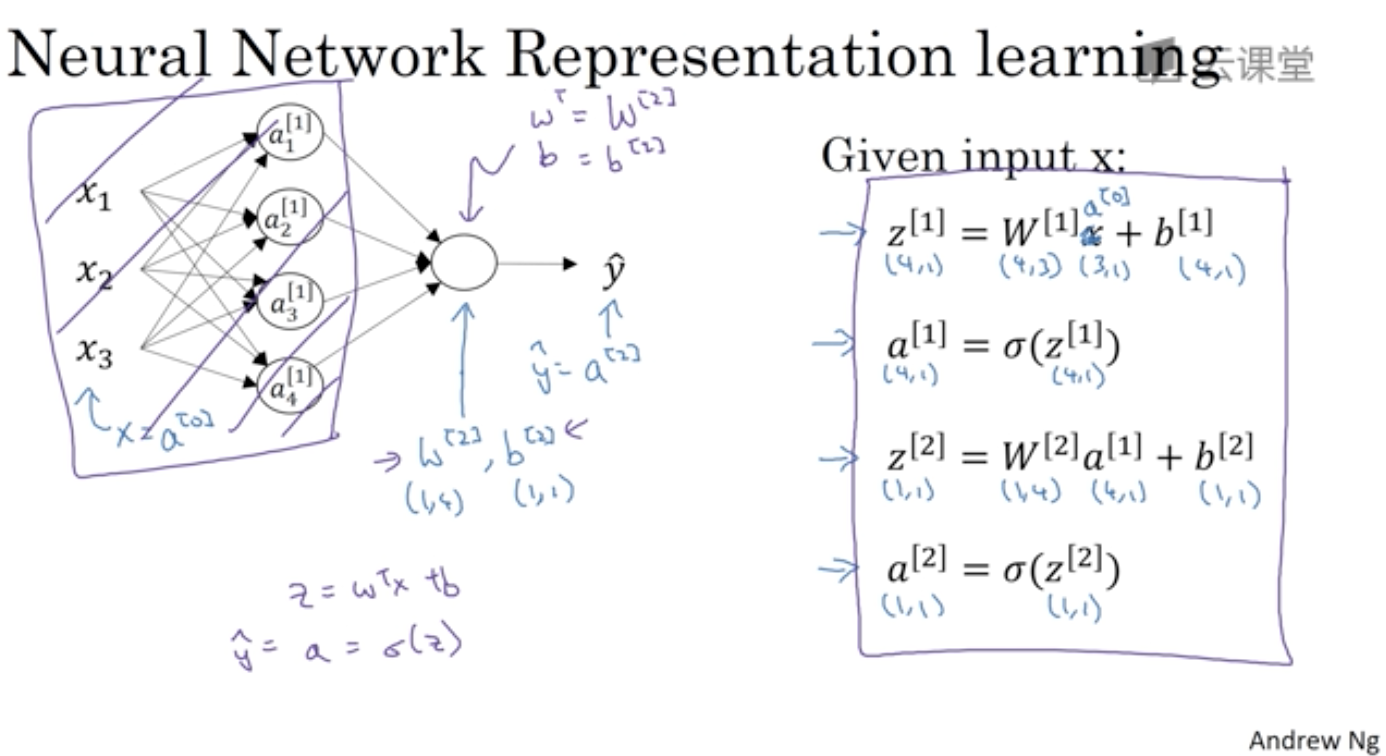
z[1], a[1]计算隐藏层,z[2], a[2]计算输出层。
4. 多个样本的向量化
方括号:层数
圆括号:训练样本 i
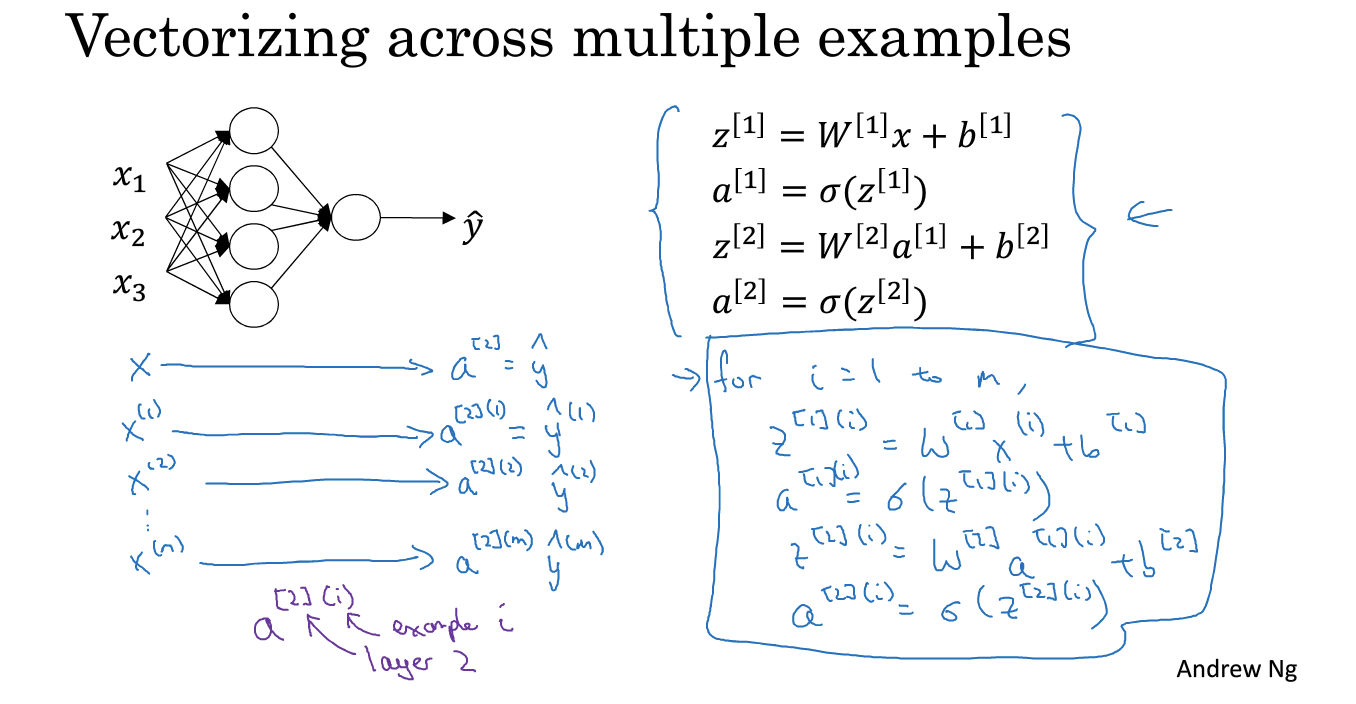

5. 向量化样本的正确实现
X是x列向量组成的,W是w的行向量组成的,得到的A是由a列向量组成的


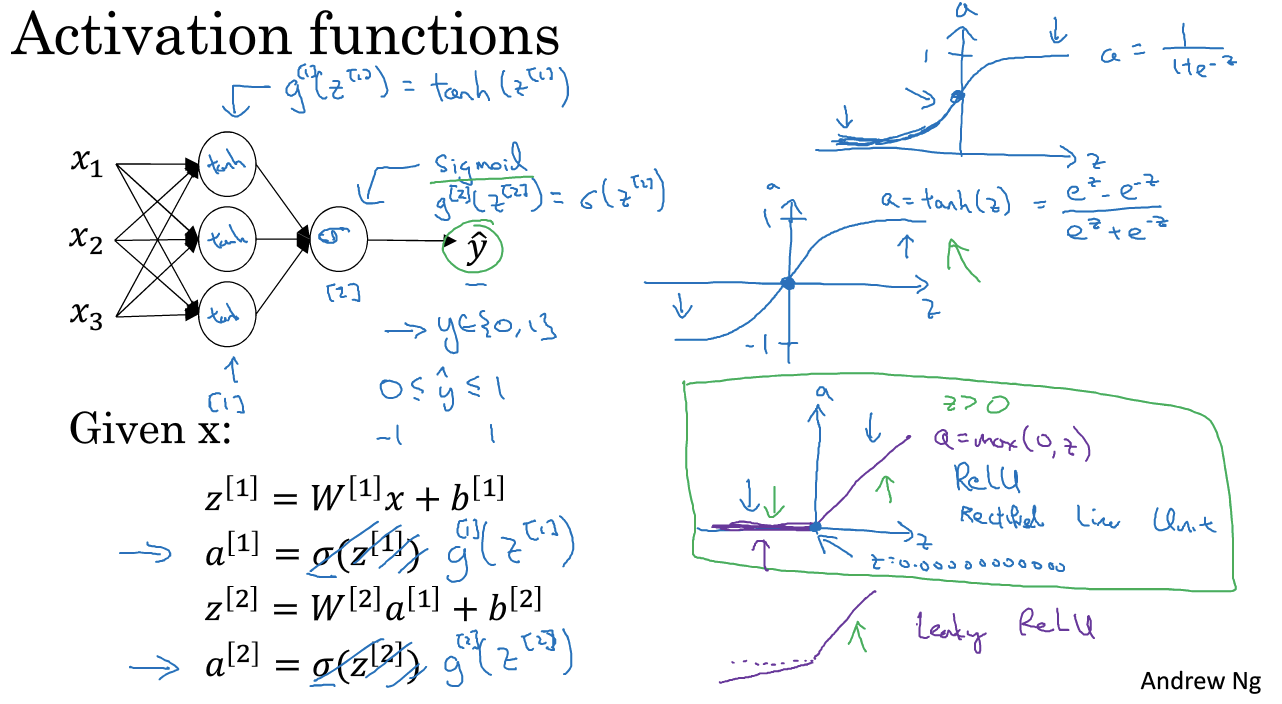
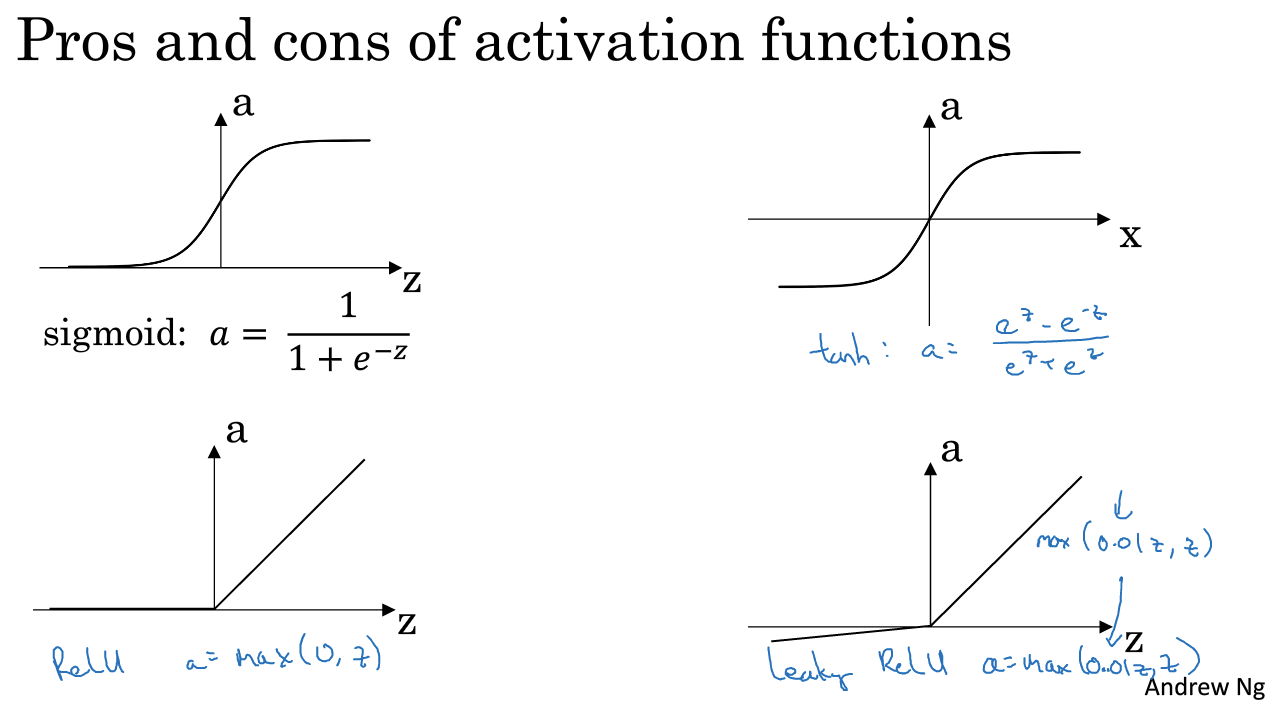
6. Activation functions 激活函数
在很多实验中,sigmoid函数并不是最好的选择。接下来介绍几个激活函数以及为什么要使用激活函数。
tanh函数一般比sigmoid函数表现好(输出层除外),有类似数据中心化效果。
二分类的时候常用sigmoid作为输出,其他时候选用ReLU(最常用的激活函数)。
g上标[1]作为不同激活函数的标志
sigmoid和tanh函数都有一个缺点:当X很大或者很小的时候,倒数的梯度可能很小,会拖慢梯度下降算法。所以比较流行的解决方法是使用ReLU。
那么为什么神经网络需要激活函数呢?
7. 为什么需要非线性激活函数
如果不使用非线性函数作为激活函数而直接使用wx + b(线性函数),那么输出就会为输入的线性组合:

结果是无论网络有多深,也只是在计算线性组合,那么到不如去掉中间的unit,和没有隐藏层的效果是一样的。
下面的课会介绍梯度下降的基础。
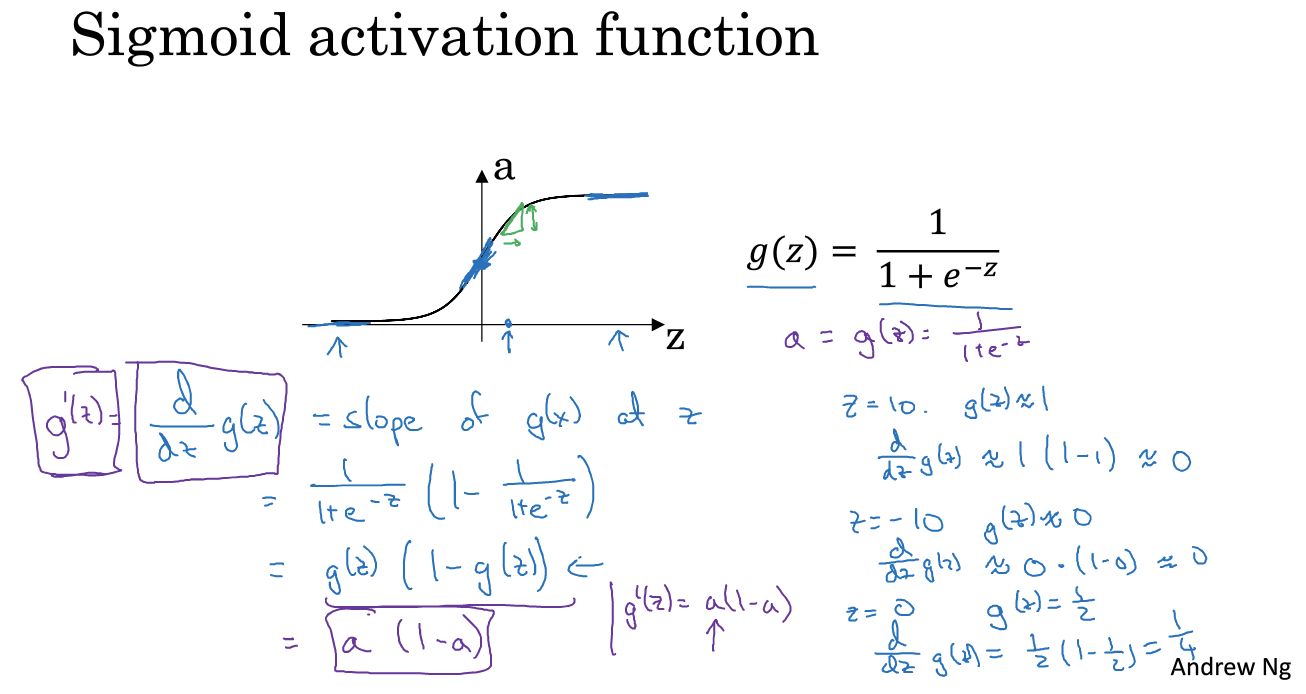
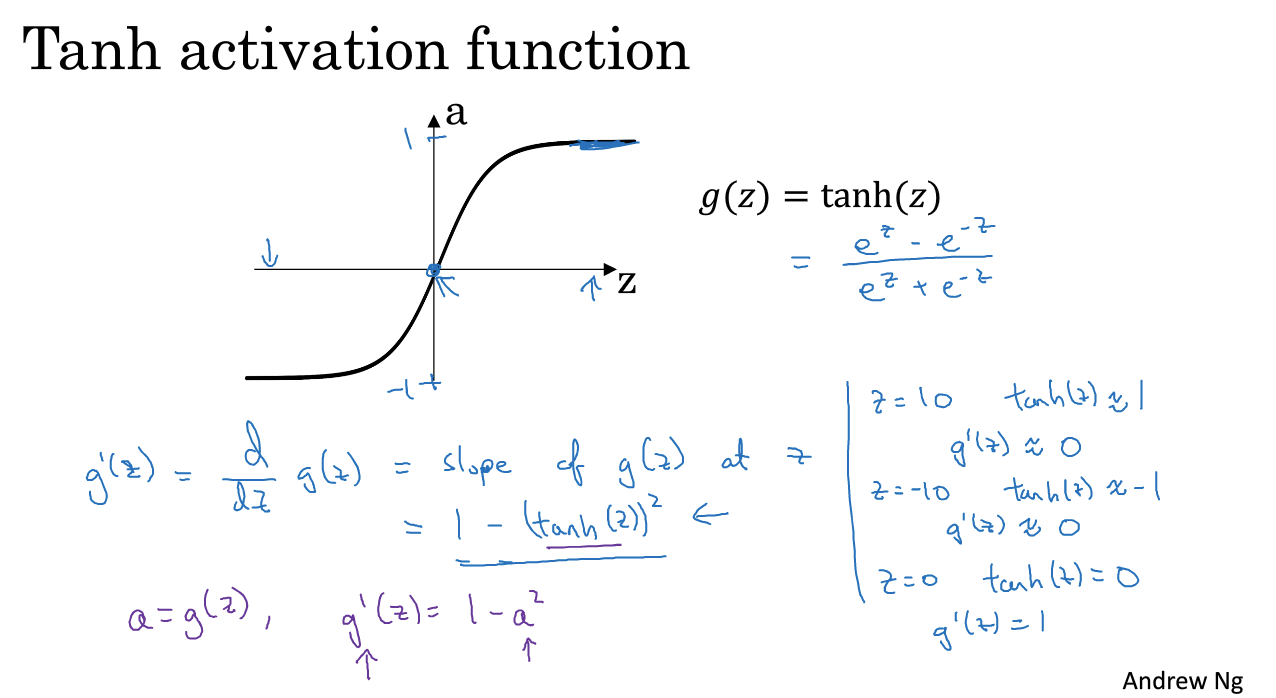
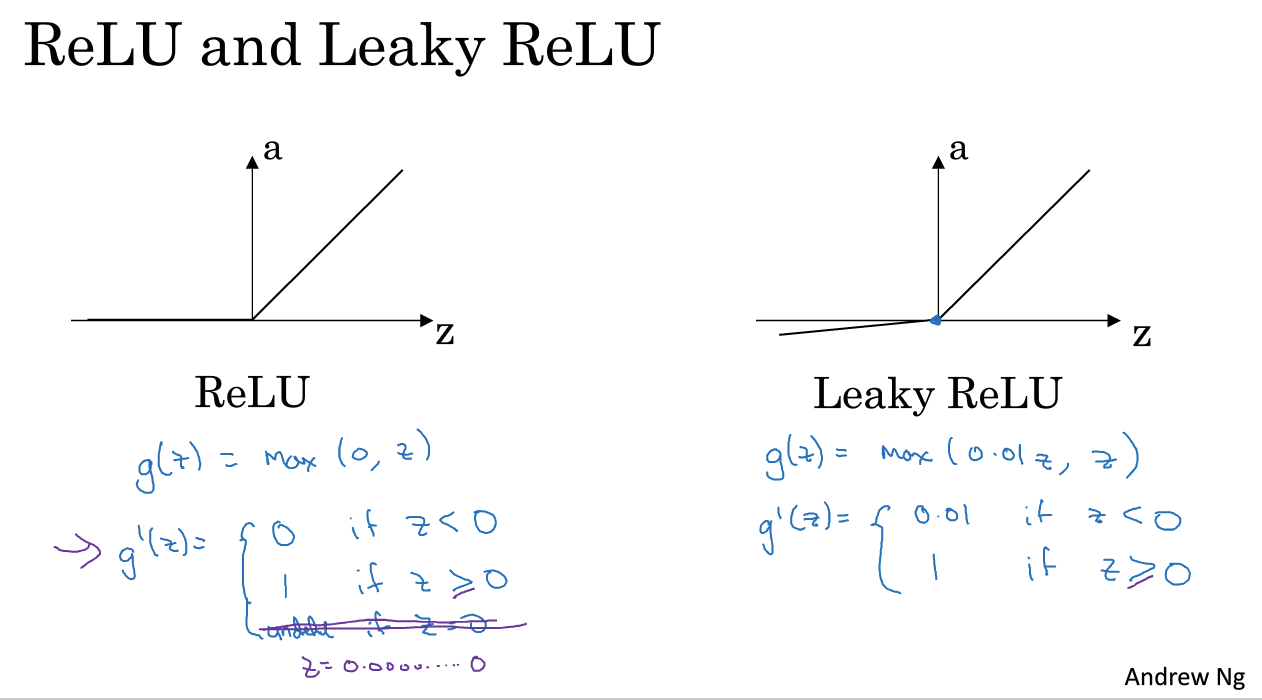
8. 激活函数的导数
ReLU在0处怎么办:实际中很少value为0.00000000的值,所以可以忽略或者直接在0处的导数记作1.
9. 梯度下降的实现
正向传播:4个公式,反向传播:6个公式,可以自己推导,下一节详细讲。


10. 直观理解反向传播(选修)
需要了解链式法则,注意六个关键等式的推导,最后向量化




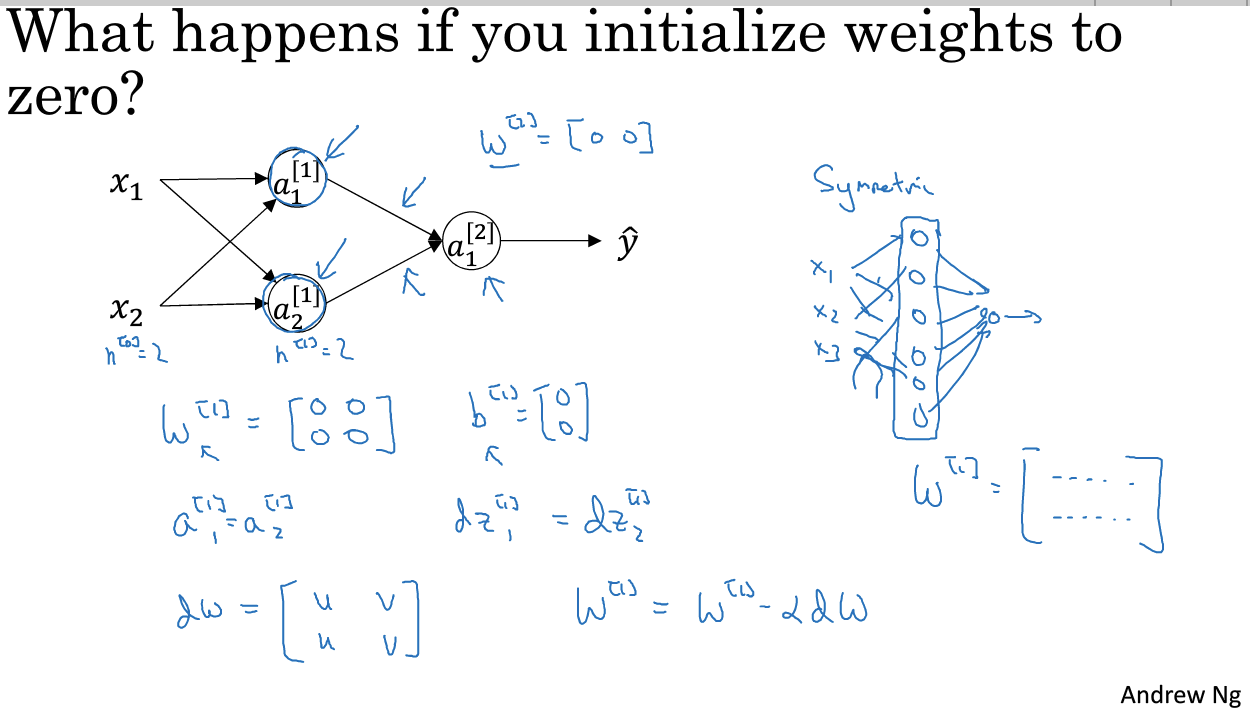
11. 随机初始化
全部随机初始化为0是不可行的:多个隐藏单元计算完全一样的函数,使得多个单元无意义。
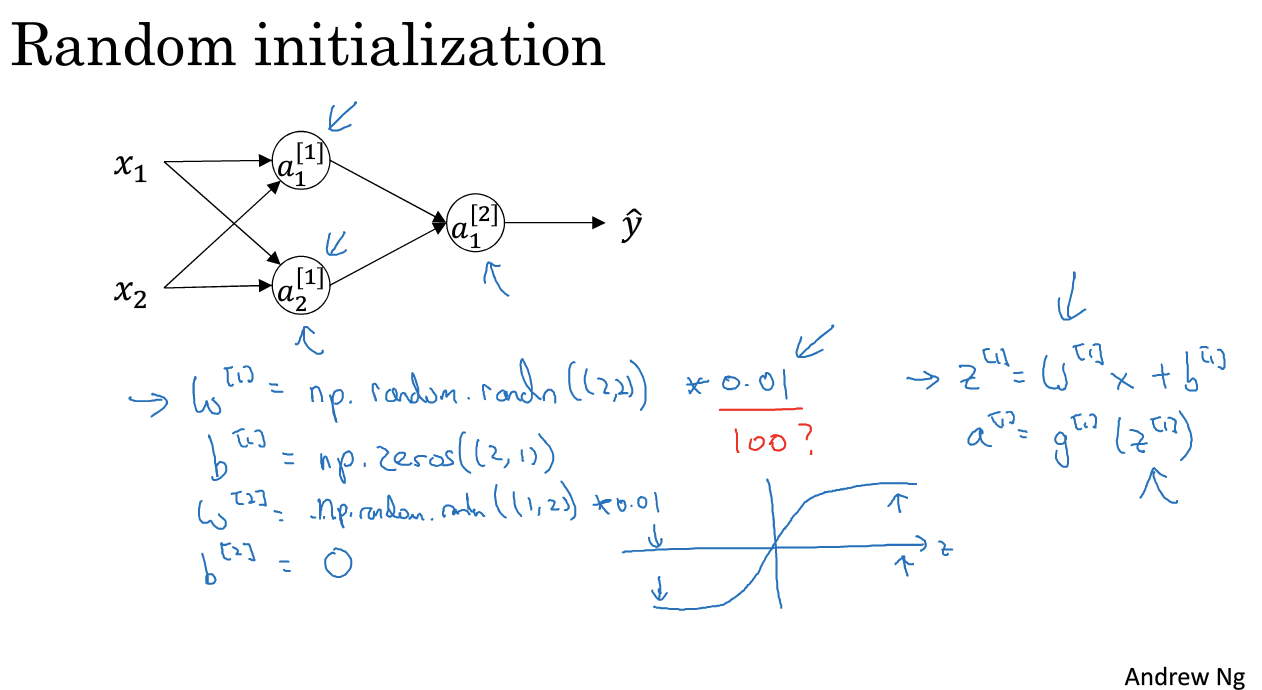
解决方法:随机初始化 w = np.random.randn((m,n)) * 0.01
为什么0、01:w 大,z and a 会很大,落在(tanh)接近饱和的区域减缓训练速度
训练很深的神经网络时,可以选择0.01以外的数来初始化,下周的课程讲。