『写在前面』
继续学习基于深度学习的点云分割算法~~~在PointCNN之后,依次阅读了PointNet、PointNet++和Frustum Pointnets三部曲,然后才看的D-CNN。鉴于“三部曲”的篇幅较长且相关blog已经有很多朋友写过,今天我就先把D-CNN给码了,后面有时间再整理。本篇blog为方便自己回忆要点用,建议参照原版paper使用。欢迎各位指正纰漏。
作者repo:https://github.com/laughtervv/DepthAwareCNN.git
论文出处:ECCV 2018
作者机构:Weiyue Wang等,University of Southern California
目录

3.2 Depth-aware Average Pooling
3.3 Understanding Depth-aware CNN
3.4 Depth-aware CNN for RGB-D Semantic Segmentation
Abstract
- 传统CNNs方法无法很好地处理点云这种非网格化的数据;
- 深度相机的广泛使用为使用CNN进行RGB-D图像的分割提供了基础;
- 当前state-of-the-art的方法主要分两类:一类是将深度图像作为额外的输入通道feed到网络中;另一类是3D volume化。弊端是增加了空间开销和计算开销。
- 为了解决上述问题,作者提出了两种新的运算符:Depth-aware Conv. 和 Depth-aware Average Pooling。使用它们替换传统CNN中的相应运算符,使之可以无缝地接入传统分割模型框架中,从而低成本且充分利用深度图信息。我认为,作者的贡献主要是另辟蹊径,建立了一种新的能够将2D-CNN和3D数据联系起来的纽带。
1 Introduction
- FCN及其衍生模型等,将深度图像视为一个额外的输入,使用两个CNN网络分别处理RGB图像和深度图像,这类做法不但翻倍了运算开销和参数量,而且还没有办法将两幅图像直接的几何相关性关联起来并借助CNN模型训练。
- 3D-CNN太笨重
Depth-aware Conv. 特点:使与kernel中心像素深度相似的像素对输出的贡献更大。作者认为,这样的trick可以有效地将几何结构融入卷积核中,从而有助于使卷积核摆脱网格结构的限制,更加关注深度信息的感知。
Depth-aware Average Pooling 特点:在计算时考虑kernel各像素点的深度信息相关性,使视觉信息和几何信息可以一并传播,几何信息(由深度图像提供)有助于确定物体边界。
提出这两种Ops的中心思想:具有相同语义标签和相似深度的像素点应该对彼此产生更大的作用。
使用Depth-aware Conv. & Depth-aware Average Pooling的好处:
- 将深度图像反映的几何信息无缝地集成到CNNs中;
- 不会带来参数量和计算量的增加;
- 能够以最小的成本取代传统CNN中的相应操作符。
2 Releated Works
2.1 RGB-D语义分割
- 第一类方法,直接将深度图作为附加通道处理;
- 第二类方法,先将深度图像编码成HHA图像(3通道:水平时差、地面高度、法线角度),然后通过两个CNNs分别学习再集成;
- 第三类方法,体素化,转3D网格,然后使用3D-CNN;
- 第四类方法,PointNets类方法,当下的state-of-the-art,缺点是依靠KNN搜索空间相关点,效率较低。
2.2 CNN中的空间变换
- 膨胀卷积
- 空间变换网络(STN)
- Deformable CNN
类比空间变换对改善传统CNNs起到的作用,作者认为,深度图像中含有的几何信息对优化CNNs的表现同样具有重要意义。
3 Depth-aware CNN
提出的两个操作符的输入都是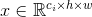

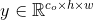

关于图2,(a)Depth-aware Conv.的输出激活是深度相似度矩阵、卷积核、feature map窗口三者的卷积乘;(b)Depth-aware Average Pooling的输出是使用深度相似度矩阵作为权值进行的加权平均值。
3.1 Depth-aware Convolution
与传统卷积运算的唯一区别是,在计算输出时,多乘了一个深度相似度矩阵
,其计算公式如下:
其中,α是一个常数,可以调节。
这个直观上的理解就是,与中心点深度值越接近,相似度越高,最大值为1。

重点:不需要引入额外参数;训练中不需要为
3.2 Depth-aware Average Pooling
传统的平均池化在计算时对kernel内所有像素一视同仁,会模糊边界。而在分割任务中,边界信息的作用很大,所以作者对这一点进行了优化。
与传统平均池化的计算相比,差别在于计算时使用深度相似矩阵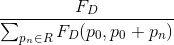
3.3 Understanding Depth-aware CNN
传统CNN中,感受野和采样区域在feature map上是固定的;而在D-CNN中,我们通过深度相似矩阵去影响感受野和采样动作。如图3所示,红点区域代表采样位置,可以发现大多数红点都落在了与中心点(绿点)属于相同类别的地方。

3.4 Depth-aware CNN for RGB-D Semantic Segmentation
Depth-aware CNN在DeepLab的基础上构建,DeepLab是目前语义分割领域的最佳实现。作者将DeepLab作为基线模型,并使用Depth-aware Ops替换其中部分对应操作符。具体模型结构如下:

4 实验
模型结构方面,作者对比了以下几种模型:
- 使用VGG-16作为主干网络的Baseline DeepLab
- 基于baseline DeepLab构建的D-CNN(VGG-D-CNN)
- D-CNN + HHA
- 将VGG-16替换成ResNet50(ResNet-D-CNN)
实验1:证明引入Depth-aware操作的模型优于现有框架;
实验2:部分替换VGG-D-CNN中的相关层,证明提出的这两种操作符的有效性;
实验3:深度相似度计算函数中α参数的设置,结论是α=8.3最佳。
实验4:性能分析。参数量没有增加,计算耗时轻微增加,总体来说比较轻量。