(一)论文简要说明
这是一篇2018年CVPR的最新论文,可以直接通过输入RGB图以及相对应的Depth图,然后可以直接补全任意形式深度图的缺失。

论文地址:https://arxiv.org/abs/1803.09326
github地址:https://github.com/yindaz/DeepCompletionRelease
(二)论文阅读
Abstract
1、Introduction
目标是用普通相机捕捉信息去完善RGB-D图片的深度通道(填充所有的空洞)——深度图像修复。
用深度网络从颜色去估计更新,但是并不能用于深度信息修补。
深度信息修补(即重建)过程的挑战:
1、Training data
困难之处:很难获得大规模的训练集,很多深度模型不完整,有缺失的现象。
解决方案:引入一个新的数据集,其中包含105432个RGB-D图像,这些图像与72个真实环境中大量重建的深度图对齐
2、Depth representation
困难之处:照理说是使用新数据集作为监督以训练完全卷积网络直接从RGB-D回归深度。但是从单目彩色图像估计绝对深度也很困难。
发现很难训练网络从深度输入来填补空洞,因为这只学会复制和插入输入深度。
解决方案:训练网络只预测深度的局部微分性质(表面法线和遮挡边界),然后用全局优化求出绝对深度。
3、Deep network design
困难之处:没有前人的经验。很难训练网络从深度输入来填补空洞——通常只学会复制和插入输入深度。
解决方案:只向网络提供彩色图片作为输入,训练网络在监督下预测局部表面法线和遮挡边界。然后将这些预测与全局优化中的输入深度结合起来,以解决返回到深度修补的问题。【网络通过颜色预测局部特征,这是网络所擅长的部分。通过从输入深度进行正则化的全局优化来重建场景的粗尺度结构。】
整个流程如下:
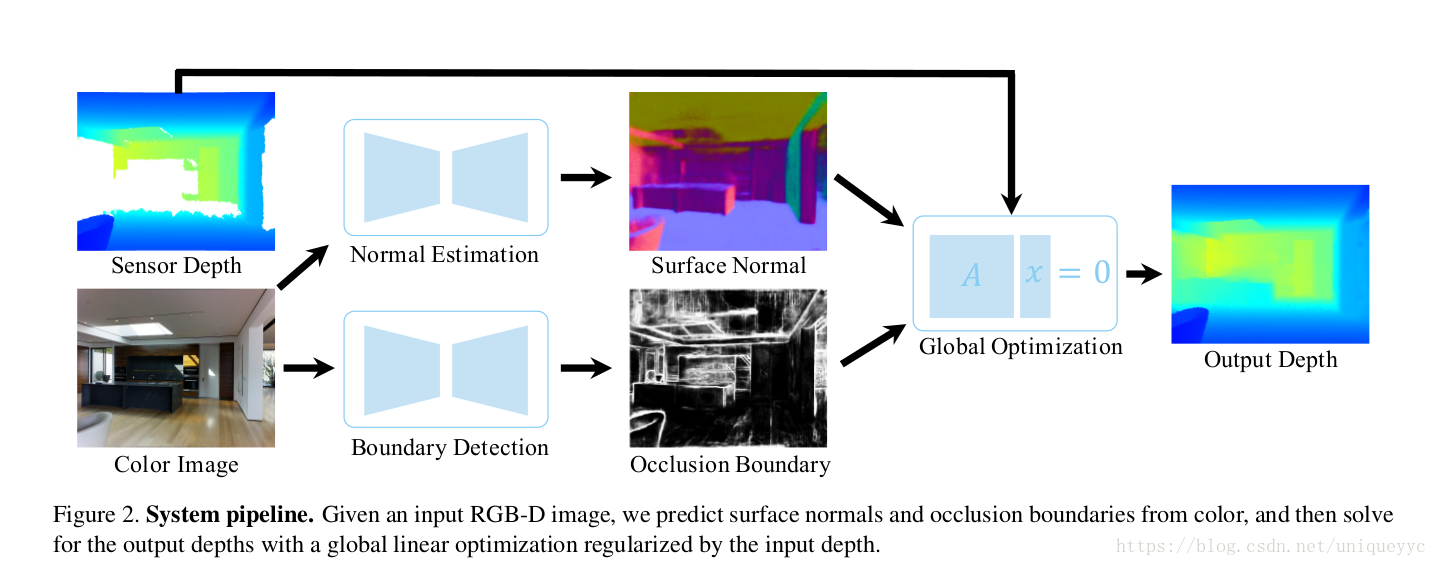
2、Related Work
(1)Depth estimation
关注深度补全,目标是对深度传感器没有返回的像素进行新的预测。由于这些像素在原始深度中缺失,因此只在原始深度上训练的方法不能很好的预测缺失的深度信息。
(2)Depth inpainting
最近,提出用自编码器和GAN体系结构绘制彩色图像的方法。先前的工作并没有研究如何使用这些方法来进行绘制深度图像。由于深度图像缺乏强大的特征和缺少大型训练数据集,这个问题更加困难了。
(3)Depth super-resolution
深度超分辨率。提出了几种利用高分辨率颜色提高深度图像分辨率的方法。包括Markov random fields, shape-from-shading, dictionary methods. 我们关注的是填充孔,它可能非常大且复杂,因此需要大规模内容合成。
(4)Depth reconstruction from sparse samples
另一项工作是研究用稀疏的深度测量集增强彩色图像的深度重建。动机是为了降低专门设置下的传感成本,而不是为了完成通常在容易获得深度摄像机中丢失的数据。
3、Method
(1)Dataset
如何创建RGB-D图像与完整深度图像相匹配的数据集?
①使用低成本的RGB-D摄像机捕捉图像,并将它们与高成本深度传感器同时捕获的图像对齐。这种方法既昂贵又耗时,这种类型的最大公共数据集涵盖了少量的室内场景。
②此论文所使用的方法,利用从大环境的多视图RGB-D扫描重建的现有表面网格(例如:Matterport3D, ScanNet, SceneNN, SUN3D)。此论文使用的是Matterport3D,对于每个场景,我们使用经过筛选的Poisson表面重构从一个全局表面重构中提取出每个房间有1-600万个三角形网格M。然后,对于场景中RGB-D图像的采样,我们从图像视点的摄像机姿态渲染重构网络M,得到完整的深度图像D*。

这样得到的图像的优点:
①补全的深度图像有更少的孔洞(因为不是限于一个视图,而是所有摄像机的观察视角的结合所产生的表面的重建)
平均而言,在原始深度图像中缺失的像素中有64.6%是由我们的重建过程填充的。
②补全的深度图像通常复制了近距离表面原始图像的分辨率,但远距离表面的分辨率要高的多。由于表面重建是在三维网格大小上构建的,与深度相机的分辨率相当,因此在完整的深度图像上通常没有分辨率的损失。然而,同样的3D分辨率,当投影到视图平面上时,可以有效地为离摄像机更远的表面提供更高的像素分辨率。因此,在绘制高分辨率网格时,完成的深度图像可以利用亚像素反锯齿来获得比原始图像更好的分辨率。
③补全的深度图通常比原始的噪声小的多。由于表面重建算法通过滤波和平均的方法将来自许多摄像机视图的噪声深度样本组合在一起,因此从本质上消除了表面的噪声。这对于遥远的观测(>4米)尤为重要,因为在那里的原始深度测量是量化和噪声的。
【本文数据集:117516张带渲染补全的RGB-D图像,其中105432张图像为训练集,12084张图像为测试集】
(2)Depth Representation
什么几何表示法最适合深度补全?
方法一,直接,设计一个从原始深度和颜色回归完整深度的网络。
方法二,间接表示,本文关注与预测表面法线和遮挡边界。由于法线是不同的表面性质,它们只依赖于像素的局部领域。
【问题:如何使用预测的表面法线和遮挡边界来完成深度图像】
理论上不可能只从表面法线和遮挡边界来解决深度问题。但是现实中,可以使深度不确定的部分相对于图片的其他部分,也就是说,对于现实场景来说,图像区域不太可能同时被遮挡边界包围,并且根本不包含原始深度观察。因此,发现在深度图像中,即使是较大的空洞,也可以使用预测表面法线来完成,用预测遮挡边界加权的相干性和受观测原始深度约束的正则化来完成。
(3)Network Architecture and Training
训练深层网络来预测表面法线和遮挡边界以达到补全深度信息的最佳方法是什么?
选择了zhang et.al中提出的深度网络架构,因为在正太估计和边缘检测方面都显示出了竞争性能【80】.The model is a fully convolutional neural network built on the back-bone of VGG-16 with symmetry encoder and decoder.用重建网格计算出的表面法线和轮廓边界来训练网络。
【如何进行深度训练?】
训练网络应该用什么损失函数?
因为目标是训练一个网络,所以仅对原始深度图像的孔洞的像素进行法线预测。由于这些像素的颜色外观特征可能与其他像素不同,人们可能认为网络应该受到监督,只对这些像素进行法线回归。所以本文对比了,在所有像素上进行训练以及仅在孔洞处进行训练。结果显示,所有像素训练的模型比仅使用观察到的或仅使用未观察到的像素训练的模型表现更好,而使用渲染法线训练的模型比使用原始法线训练的模型表现更好。

【网络应该输入哪些图像通道?】
一开始并没有将深度信息输入,直接让网络预测深度信息的效果更好。
结果表明可以训练一个网络仅从颜色来预测表面法线,并且在从法线求深度时只使用观察到的深度作为正则化。这种将无深度预测与有深度优化分离开来的策略很有吸引力,首先,预测网络不需要对不同深度传感器进行重新训练。其次,优化可以推广到各种深度观测作为正则化,包括稀疏深度样本。
(4)Optimization
最后进行优化的过程。
目标函数为:四项误差平方的加权和
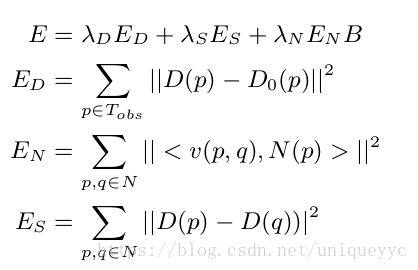
ED:在像素p处,估计深度D(p)与观察到的原始深度D0(p)的距离
EN:估计深度与预测表面法线N(p)的一致性
ES:促进相邻像素之间具有相同的像素
B ∈ [0, 1] downweights the normal terms based on the predicted probability a pixel is on an occlusion boundary (B(p)).(根据一个像素在遮挡边界B(p)上的预测概率对正常项进行加权)
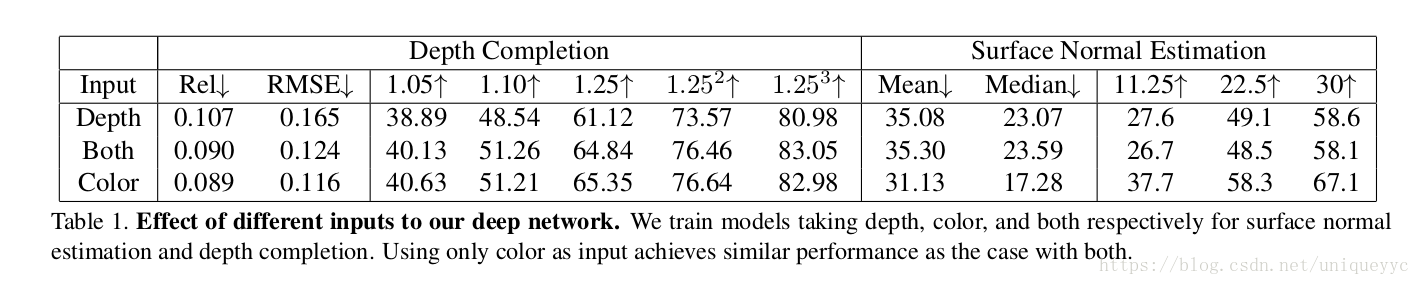
4、Experimental Results
实验是在SUNCG数据集上进行预训练的,然后在本文的新数据上训练进行微调的。仅仅使用颜色作为输入,并计算所有渲染像素的损失。
(1)Ablation Studies
第一组实验研究了不同的测试输入、训练数据、损失函数、深度表示和优化方法对深度预测结果的影响。
什么数据应当被作为网络的输入?
color only
什么深度表示最好?
从预测法线(N)求解深度得到的结果是最好的。
原因:法线只代表表面的方向,这是相对容易预测的。法线不像深度或深度导数那样随深度缩放,因此在一系列视图中更加一致。
遮挡边界的预测有用吗?
遮挡边界为深度不连续提供信息,有助于保持边界锐度。
需要多少观测的深度?
实验结果表明,当只给原始深度图像中的一小部分像素时,优化器几乎可以得到几乎同样精确的结果。该方法可用于其他深度传感器的稀疏测量设计。在这种情况下,我们的深层网络不必为每一个新的密集传感器进行重新训练(因为仅依赖于颜色),这是本文两阶段方法的优点。
(2)Comparsion to Baseline Methods
第二组实验研究了该方法与基线深度绘制和深度估计方法的比较。
①Comparison to Inpainting Methods.
②Comparison to Depth Estimation Methods.
5、Conclusion
本文介绍了一种普通RGB-D相机获得的RGB-D图像深度通道的深度学习框架。它提供了两个主要的研究贡献。首先,它建议用两个阶段的过程完成深度补全,是从颜色预测表面法线和遮挡边界,然后再结合原始深度信息完成深度补全。其次,通过对大规模表面重建的数据进行监督训练,学习如何补全深度图像。在一个新的基准测试中,我们发现所提出的方法在深度测绘和估计方面优于以前的基线方法。
(三)实现
1、quick test
(1)Download realsense data in ./data/, and unzip it there.
(2)Download bound.t7 and normal_scannet.t7 in ./pre_train_model/.
(3)Compile depth2depth in ./gaps/.
(4)Run demo_realsense.m in ./matlab/.
按照官方github上的上述步骤进行。
在(3)时出现编译错误,提示为

看自己是否已安装一下依赖
sudo apt-get install libhdf5-10
sudo apt-get install libhdf5-serial-dev
sudo apt-get install libhdf5-dev
sudo apt-get install libhdf5-cpp-11然后测试自己所需的依赖都已经安装了,但是仍然找不到hdf5.h,所以猜测应该是环境变量中没有加入
find /usr -iname "*hdf5.h*" //查找出所有的含有这个文件的路径
export CPATH="/usr/include/hdf5/serial/" //使用这条命令加入环境变量然后
make clean
make还是错误。
继续测试更新中……
补充解决方案
改变makefile中的
USER_LIBS=-lhdf5
改为
USER_LIBS = -L/自己目录中查出的地址/hdf5/serial -lhdf5
问题解决,生成depth2depth可执行文件
然后安装MATLAB,如果是学校学生,用学校邮箱可以免费使用正版的MATLAB软件。具体安装不再赘述。
执行
matlab demo_realsense.m //在MATLAB目录下执行此命令,出现可视化界面。运行即可。代码可能需要些许改动,已向作者提问,应该会修改。
%% Demo for depth completion on RGBD images from Intel Realsense.
% Torch must be installed.
% If command lines cannot be called, please copy and run them in terminal.
cd('../torch/');
% Boundary detection
cmd = 'th main_test_bound_realsense.lua -test_model ../pre_train_model/bound.t7 -test_file ./data_list/realsense_list.txt -root_path ../data/realsense/';
system(cmd); % the result should be in ../torch/result/
% Surface normal estimation
cmd = 'th main_test_realsense.lua -test_model ../pre_train_model/normal_scannet.t7 -test_file ./data_list/realsense_list.txt -root_path ../data/realsense/';
system(cmd);
cd('../matlab/');
% Get occlusion boundary (the 2nd channel) and convert to weight
GenerateOcclusionWeight('../torch/result/bound_realsense_test_bound/', '../torch/result/bound_realsense_weight/');
% Compose depth by global optimization
composeDepth('../data/', '../torch/result/normal_scannet_realsense_test', '../torch/result/bound_realsense_weight', 'realsense', '../results/realsense/', [1000, 0.001, 1]);
% 改动处
% Visualize results
%需要显示哪幅图就改成图的位置就行,当然这个代码仅用于可视化效果对比作用而已,影响不大。
input = imread('../data//realsense/012_depth_open.png');
output = imread('../results/realsense//realsense_012_1.png');
colormap = jet(double(max([input(:);output(:)])));
figure;
subplot(1,2,1); imshow(label2rgb(input, colormap)); title('Input');
subplot(1,2,2); imshow(label2rgb(output,colormap)); title('Output');quicktest运行至此完毕,后续深入将继续。