《Frustum PointNets for 3D Object Detection from RGB-D Data》论文及代码学习
《Frustum PointNets for 3D Object Detection from RGB-D Data》一文是Charles R.Qi等人发表在CVPR2018上的文章(提前版本2017.11.22发表,2018.04.13提交了更新版本,主要修改了附件),这里是论文及代码。本文中记录了博主在学习论文和调试代码中遇到的问题。更新于2018.09.18。
环境配置中有Tensorflow、opencv、cv2、mayavi的安装教程,如果只需要教程的话可以直接看这里,就不用看这一大堆啦。
真是服了……之前没写好的版本竟然直接给我发出去了,说好的存成草稿呢……所以新的编辑器下面是不能直接点保存变成草稿了,坑
文章目录
论文学习
这篇论文的作者之前发表过两篇与frustum pointnets相关的论文,分别是PointNet和PointNet++。这三篇论文主要是解决3D点云下的目标分割和识别问题的,这里主要总结frustum pointnets,关于另外两篇论文的学习总结如果有需要会写出来。
Frustum PointNets是直接以RGB-D图像(即点云数据)为输入,实现3D场景下的目标识别的网络。其基本过程是,给定RGB图像后,网络先利用一个2D目标识别算法(任意一个都可以,论文中并未对此部分单独提出算法)确定目标在RGB图像中的位置。在给定这个位置后,其对应的四棱台区域和其对应的点云子集就可以确定了。随后,算法依赖一系列坐标系平移的辅助,基于之前提出的两种图像分割算法,实现3D场景下的目标识别。算法的输出为目标所在立体区域的中心坐标以及目标模型化的长方体(也就是能够将目标全部包含的长方体)的尺寸和朝向。损失函数监测的内容为:分割情况、长方体的朝向、中心位置、三边尺寸、三个角的位置。用于坐标平移的是一个单独的T-NET。
下面具体说一下每个部分:
坐标系转换
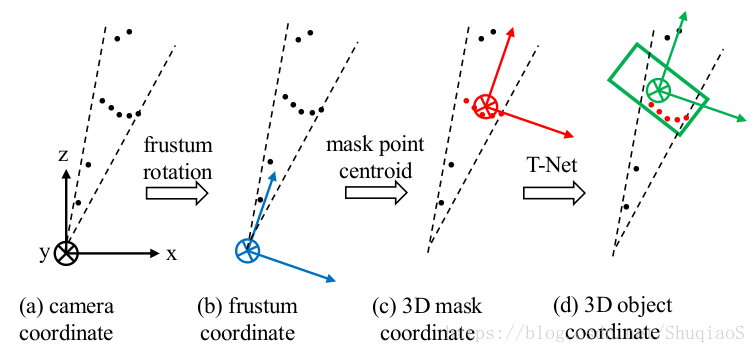
下图是frustum pointnets坐标转换步骤的示意图。图(a)是原始坐标系,也就是相机坐标系;图(b)是相机坐标系经过旋转得到的四棱台坐标系,改动就是将z轴旋转至棱台的中轴线,x轴则与中轴线正交;图©是经过mask的坐标系,改动是将棱台坐标系平移至目标点云的图心(centroid,代码里的具体实现就是求了被判定为目标的点坐标平均值);图©是目标坐标系,也就是最终估计目标模型的坐标系,由T-Net学习得到(具体实现方法看代码分析部分)。
损失函数
由于这是一个多任务优化算法,因此在损失函数中应包含用于图像分割的Pointnet的损失
、用于坐标平移的T-Net的损失、和用于框出目标的PointNet的损失三部分组成。具体的公式如下:
\begin{split}
L_{multi-tast}=&L_{seg}+\lambda(l_{c1-reg}+L_{c2-reg}+L_{h-cls}+\
&L_{h-reg}+L_{s-cls}+L_{s-reg}+\gamma L_{corner})
\end{split}
其中,
和
分别对应T-Net的坐标平移损失和box estimation的中心回归损失(也就是判断长方体模型中心产生的损失)。
和
分别对应朝向的类别损失和回归损失(这是因为frustum pointnet给box的朝向规定了几个量化的方向,在代码中既包含了这些方向的标号,也会将这些标号转成连续的弧度值)。
和
分别代表box尺寸的类别损失和回归损失,与朝向类似,尺寸也是被规定出了几个标准尺寸,但是在计算损失的时候也会将这些量化尺寸转化成连续的尺寸损失。
类别判定过程中用的是Softmax方法,回归问题用的是smooth- (huber)损失。
(这里插一句,在神经网络的训练过程中经常可以看到Softmax和Softmax损失,需要注意的是,这两个并不是同一个东西。在分类任务中,Softmax其实是为了实现找到max值的作用,但是由于max运算无法求导,因此用softmax替代。具体可以参见我的另一篇博客。)
上面的损失公式将box的尺寸和角度等参数视为独立的变量计算损失,但实际情况是box的尺寸和角度共同决定了box的信息,而最终得到的box的信息才是我们想要的。因此,frumstum pointnet引入了box的角损失,也就是上面的损失公式中的 ,具体的计算公式为:
注意最后一项中是对 求和的,论文中这里写的是对 求和,博主认为根据文章要表达的意思,这里应该是写错了。最后两项之间找一个最小值的原因是,frusmtum pointnet算法认为估计得到的box上下颠倒其实并不影响最终给出的结果,因此将box上下旋转180度,取最小的那个损失。
网络模型
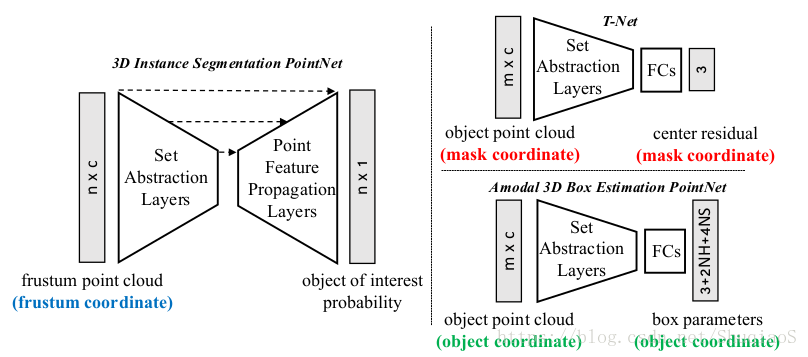
下图是frustum pointnet的概念性网络结构示意图。其中,最左边的3D instance segmentation pointnet是用于图像分割的(也就是pointnet或pointnet++),右上角的T-Net是用于坐标系平移的(估计以目标中心为原点的坐标系),右下角的amodel 3D Box Estimation PointNet是用来估计框出目标的box的各项参数的(朝向、尺寸)。
具体的网络结构如下图所示:
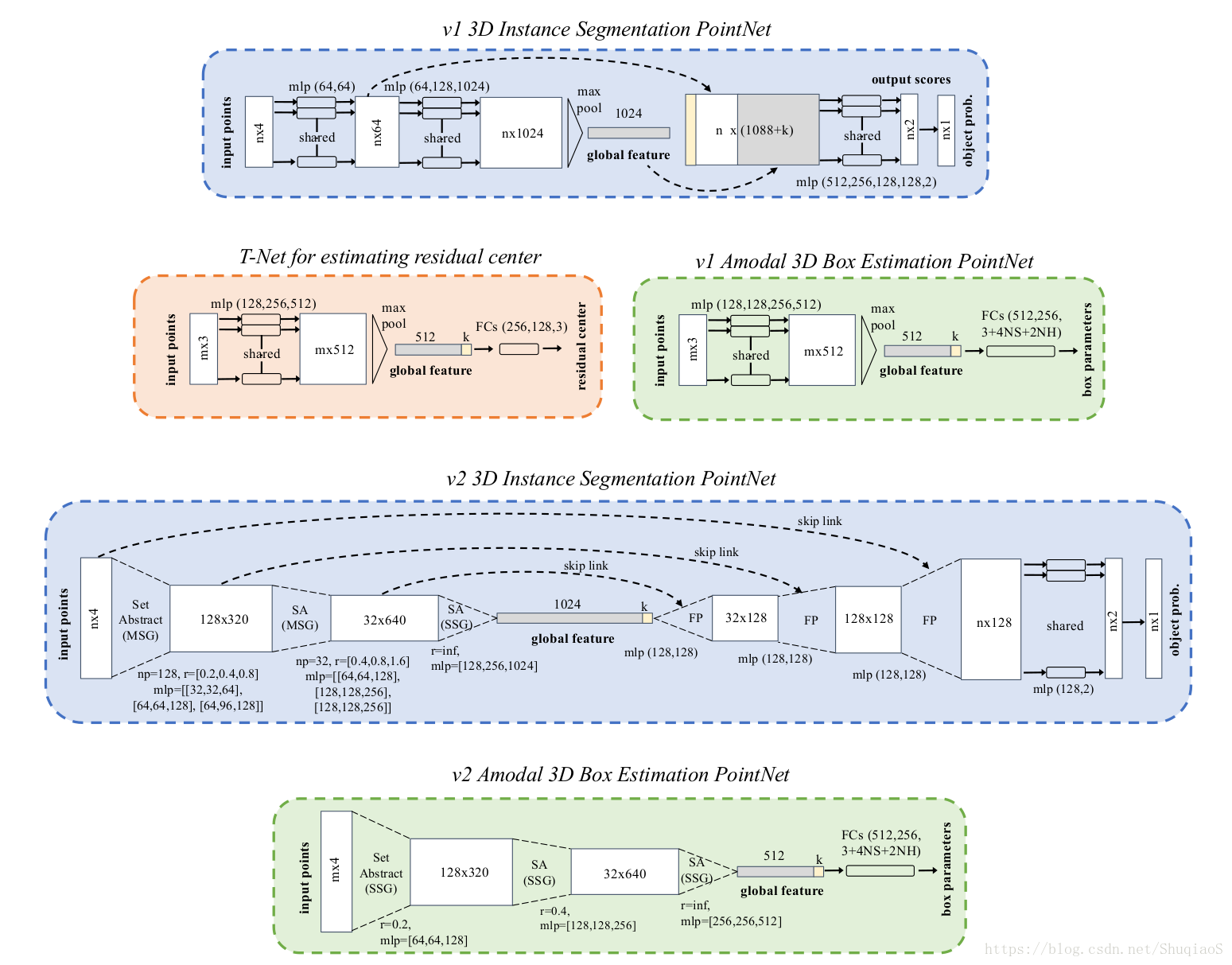
其中,v1 3D Instance Segmentation PointNet对应的是PointNet,v2 3D Instance Segmentation PointNet对应的是PointNet++。v1和v2两个网络结构共用同一个T-Net结构平移坐标系,但是分别对应了各自的Box Estimation网络。
结构中的mlp是multi-layer perceptron(多层感知机)的简称,括号中表示的是感知机中hidden layer的神经元个数。关于两个图像分割网络的具体分析,如果有需要,会在单独分析这两个网络的博文中写。
数据库
frustum pointnet用的是KITTI的3D目标识别数据库(还有一个博主没有研究过),用到了左图、点云、相机参数和训练样本标签。KITTI中一共有三类样本,分别是人、车、自行车。代码中提供了查看数据库的程序,直接运行就可以查看3D数据。用于训练网络的信息为标签、点云和3D框(box)。代码中也给出了论文作者处理好的数据和训练得到的模型参数,可以直接下载。
实验设置
训练过程中的主要评价指标是IoU(Intersection over Union),阈值为0.7。
最优化方法用的ADAM;学习率0.001,每60k次迭代衰减一半;多任务损失公式中
,
;朝向和尺寸的回归损失部分用的系数为10,从而能够与其他数据量级匹配;除了最后的分类层或回归层,其他的层都用了batch normalization(初始衰减率0.5,逐步降为0.99(每20k次迭代衰减一半));v1的batch size为32,v2的是24。所有网络都是端到端训练。
设备:GTX 1080 GPU。
训练时长:v1网络(全部三个部分)200次迭代需要两天;v2网络(全部三个部分)200次迭代需要六天。实验中结果评估用到的迭代次数为200次的实验结果。
代码学习
环境配置
1. 安装Tensorflow
(论文的版本用的是TF1.2或TF1.4,因此版本不要太新):
pip install tensorflow==1.4.0
如果提示pip找不到命令,则先更新pip,再安装:
pip install --upgrade pip
安装tensorflow可能需要一段时间,安心等待就好~
2. 安装opencv和cv2
如果没有安装opencv就先按照下面的步骤安装opencv(这里安装的版本是3.1.0),也可以按照官方文档安装:
a) 安装opencv的支持库:
sudo apt-get install build-essential
sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
sudo apt-get install python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev
b)克隆opencv包(网速不好需要很久,耐心等等):
cd ~/<my_working_directory>
git clone https://github.com/Itseez/opencv.git
git clone https://github.com/Itseez/opencv_contrib.git
c)用CMake安装
cd ~/opencv
mkdir build
cd build
cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local ..
在上一步有可能出现卡在下载 ippicv_2017u3_lnx_intel64_general_20170815.tgz这个地方,那么证明网速不是很好。如果实在不行,可以尝试根据这里的方法,预先下载这个tgz文件,在camke。
d)上一步成功之后,在build文件夹下运行:
make -j8
e)可以选择安装文档(也可以省略):
cd ~/opencv/build/doc/
make -j7 html_docs
f)安装libraries,在build目录下运行:
sudo make install
g)最后,可以测试以下程序:
[optional] Running tests
Get the required test data from OpenCV extra repository.
For example
git clone https://github.com/Itseez/opencv_extra.git
set OPENCV_TEST_DATA_PATH environment variable to <path to opencv_extra/testdata>.
execute tests from build directory.
For example
<cmake_build_dir>/bin/opencv_test_core
至此,opencv就安装成功了。
安装cv2只需要运行下面的命令就可以了:
pip install opencv-python
3. 安装mayavi
运行下面的命令即可:
pip install mayavi
至此,所有的依赖库已经安装完毕,当然,为了运行程序,电脑上还应该装有python,建议安装2.7,不要安装3,以免程序出现问题。
代码说明
每个代码文件的学习笔记博主将会整理出来贴上链接,此处到时仅作文件功能说明用。