《Frustum PointNets for 3D Object Detection from RGB-D Data》论文及代码学习(二)代码部分
文章目录
数据生成
frustum-pointnets-master/kitti/下面一共有两个文件夹,3个py文件,一个编译得到的pyc,三个单独下载下来的处理好的数据。
./rgb_detection
这个文件加下面存放着提前得到的2D估计结果,包括训练集结果和交叉验证集结果。结果格式为:
图片数据路径 类别标签 概率 矩阵坐标(应该是对角的两个点)
frustum支持从2D数据的基础上估计3D目标模型,这个数据可以用他们提供的,也可以自己生成其他的2D结果。
./kitty_object.py
文件的学习说明参见另一条博文。
这个文件是用来检查所需要的KITTI 3D数据库是否正确下载并且按照dataset/README.md中的要求放置在对应的文件夹下面。当所有文件都放好了,运行命令:
python kitti/kitti_object.py
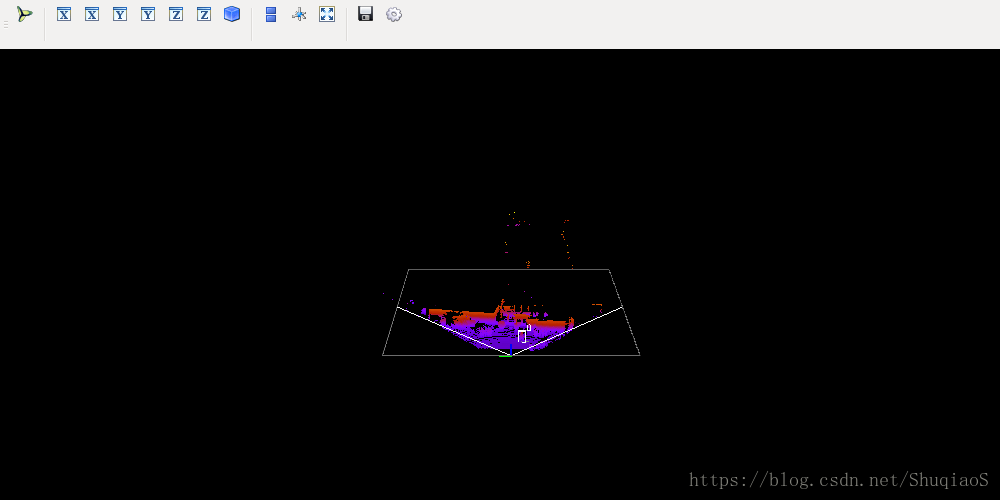
应该看到3D点云数据的平面和立体显示,如下图所示(运行过程会有一点慢,耐心等待):
首先获得平面图像:

在终端按下回车,继续得到3D点云图像:
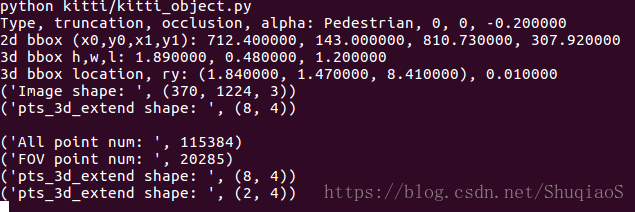
此时,终端上显示出各项参数:
此时就可以开始生成用于训练和测试的数据集了。除了运行下面的代码外,也可以直接下载论文作者生成好的数据集:
sh scripts/command_prep_data.sh
这个过程就是依照2D bounding box真值(训练集和验证集)和目标检测器估计的2D bounding box(验证集)将KITTI中的四棱台点云和对应的类别标签提取出来。其中,训练集和测试集的图片标号分别保存在路径kitti/image_sets/train.txt和kitti/image_sets/val.txt下。也会从上面提到的kitti/rgb_detections/rgb_detection_val.txt文件中提取验证集的估计2D bounding box结果。
运行下面的代码可以看到具体的数据生成步骤:
python kitti/prepare_data.py --demo
第一步:提取2D和3D bounding boxes

第2步:获取点云
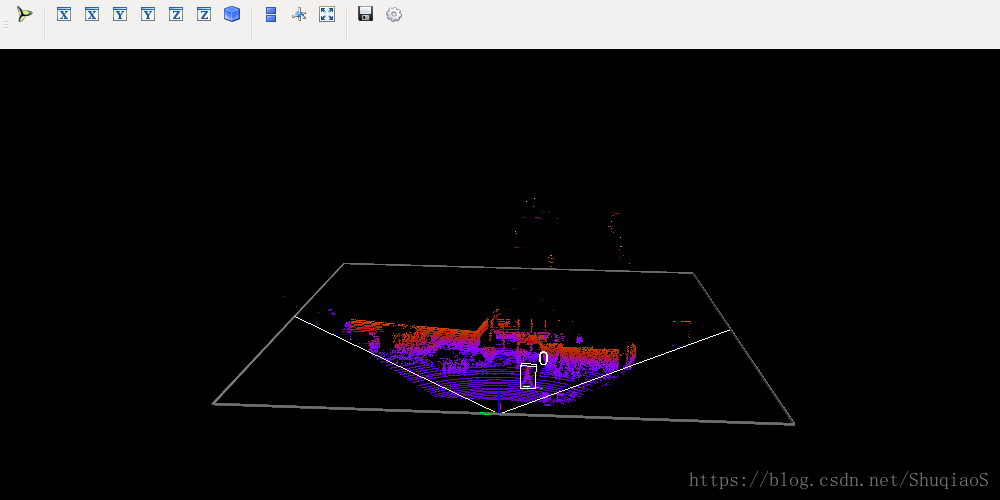
第3步:将点云投射到图像平面

第4步:提取3D bounding box内的点云
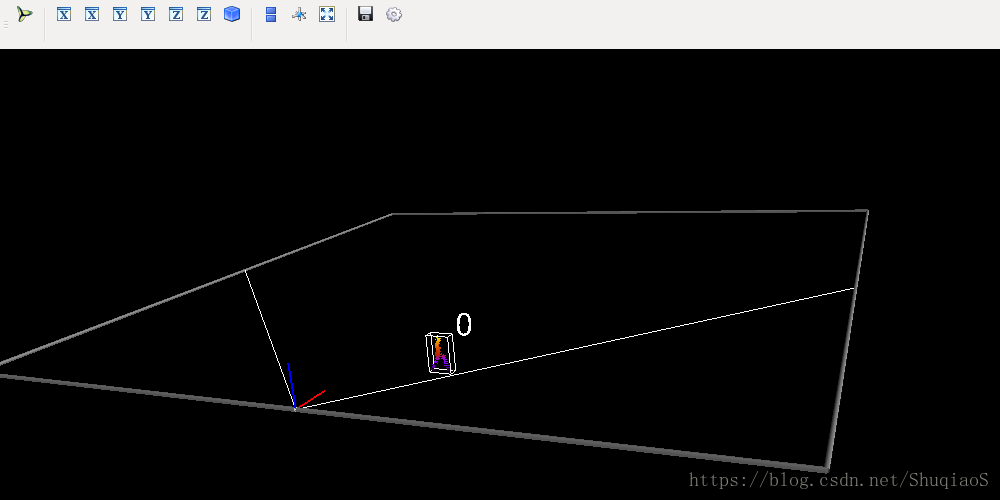
第5步:提取从2D bounding box看出去的点云四棱台
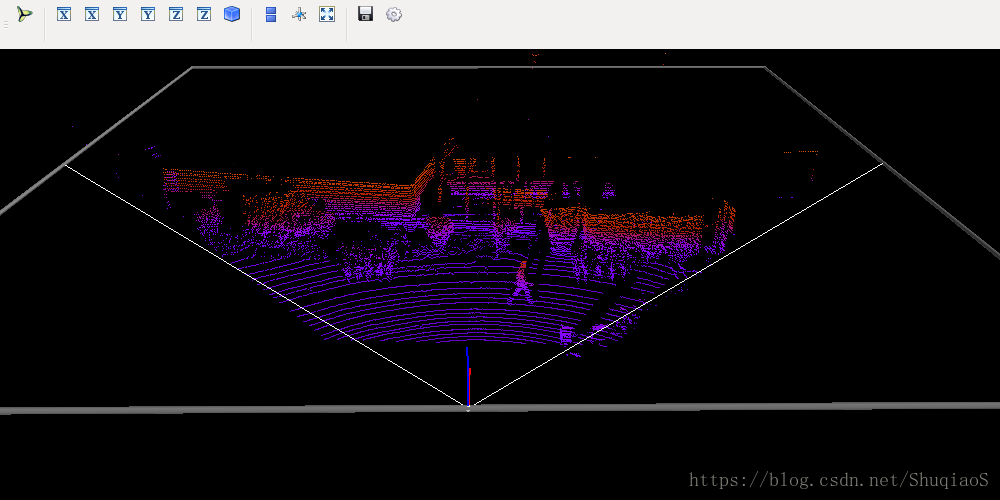
第6步:提取目标bounding box对应的点云四棱台
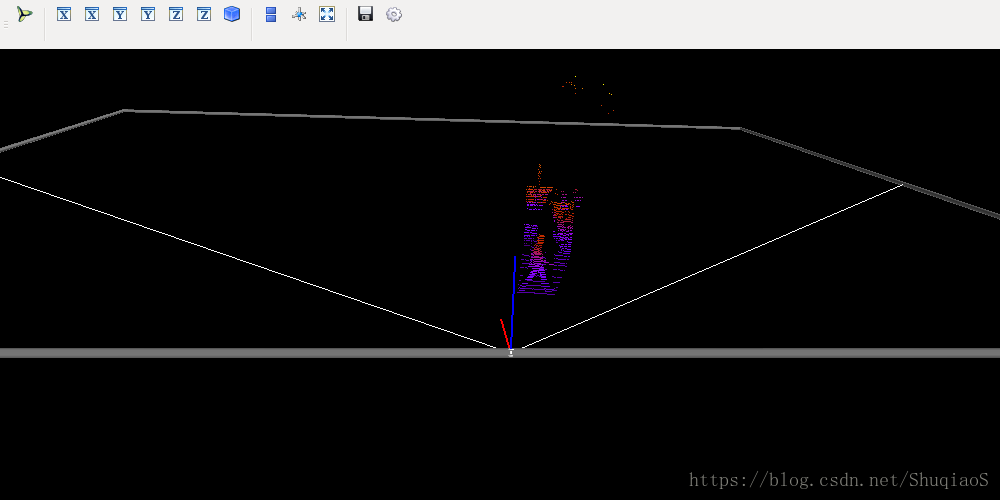
结束。
具体的程序实现过程可以参照文件 kitti/prepare_data.py,由于目前博主并不关心具体的实现过程,此处就不做详细阅读和说明了。
网络训练
训练网络可以在终端运行下面的命令:
CUDA_VISIBLE_DEVICES=0 sh scripts/command_train_v1.sh
类似地,要训练v2只需要训练scripts/command_train_v2.sh即可。训练数据和检查节点信息会保存在train/log_v1(或train/log_v2)中。训练中的参数可以通过python train/train.py -h查看。
训练好的网络参数可以直接从论文作者提供的网址下载获得,只需要将下载的文件解压,并将log_*文件夹放置在train文件夹下即可。
下图是显示出的可供调节的训练命令:
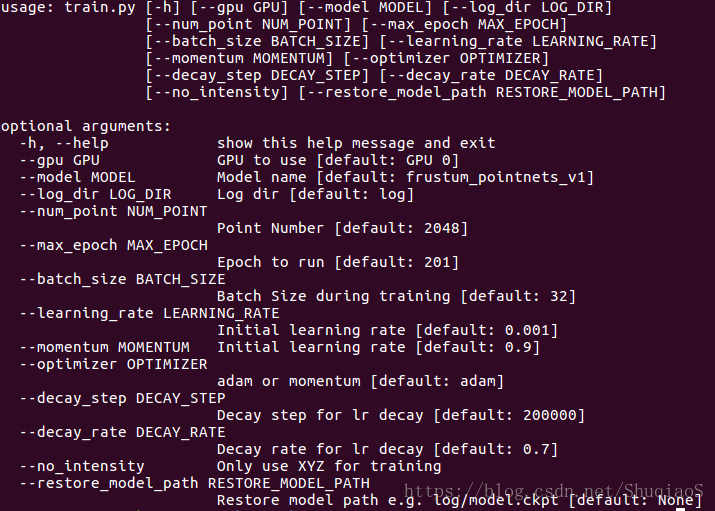
文件scripts/command_train_v1.sh中的命令是这样的:
python train/train.py --gpu 0 --model frustum_pointnets_v1 --log_dir train/log_v1 --num_point 1024 --max_epoch 201 --batch_size 32 --decay_step 800000 --decay_rate 0.5
其中train/train.py的详细注解请参照学习笔记。
其他命令说明:
命令--gpu 0设定的是用来运行程序的GPU编号,0就是第一块GPU;
命令--model frustum_pointnets_v1指定了用于图像分割的网络结构是v1还是v2,这里指定的是v1;
命令--log_dir train/log_v1确定的是log的存储路径;
命令--num_point 1024指定对于每一个样本只从点云四棱台中抽取1024个点用于训练;
命令--max_epoch 201指定一共要运行多少个epoch(一个epoch中会运行数次迭代);
命令--batch_size 32规定batch size为32;
命令--decay_step 800000规定每多少次进行衰减;
命令--decay_rate 0.5规定初始衰减率。
网络测试
可运行下面的程序测试网络:
CUDA_VISIBLE_DEVICES=0 sh scripts/command_test_v1.sh
同样,如果要测试网络2,只需要运行scripts/command_test_v2.sh文件即可。这个代码会基于2D目标检测器的2D bounding box计算结果,自动评估frustum pointnets在验证集上的效果(2D检测器的代码不包含在frustum pointnets中);随后运行KITTI的离线评估代码,计算并显示2D检测、bird’s eye view检测和3D检测的平均精度。
如果想看网络的估计结果,博主写了一个python程序,下载后放在kitti文件夹下运行就可以啦。如果对大家有帮助,请在GitHub上Star一下哦。
尽管这里没有公布对于测试集的测试代码,但是算法的README文件给出了可行的方案:
首先,要用一个2D检测器获取KITTI测试集的检测结果,并将其存储在kitti/rgb_detections的一个文件中;
随后,要修改kitti/prepare_data.py从而获取测试集的点云四棱台;
接下来,可以修改在scripts下的文件中的数据路径、刚才生成的训练数据路径、以及输出文件名。
论文作者说明:他们所提供的结果报告是用了全部的trainval训练网络得到的。
测试结果
下图是车辆的2D检测结果
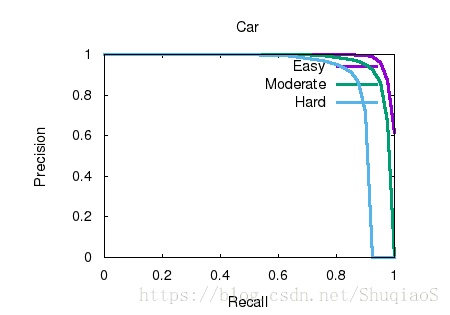
3D检测结果
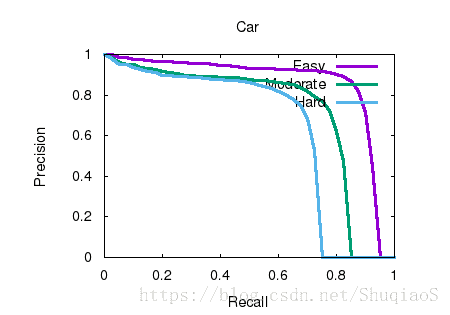
以2D bounding box真值为输入的结果
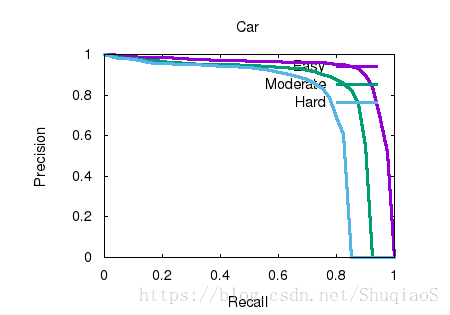
根据评估曲线可以看到,虽然3D检测结果好坏在一定程度上依赖2D的检测精度,但二者并非是简单的叠加关系。算法本身的精度还有可提升的空间,尤其对于行人和自行车,算法的效果仍然可以提高。