之前两篇文章介绍了two-stage 的目标检测框架,本文开始介绍 one-stage。
YOLO v1
YOLO,解决了目标检测中最大的难题:速度,它为目标检测提供了新的思路。
主要特点:1,快,2,将背景预测为前景的错误率小,3,泛化能力强。
主要思想:
- 将整张图作为网络的输入,直接在输出层回归box的位置和类别。
- 将图像分为S×S个网格,如果某个object的中心落在这个网格中,则这个网格就负责预测这个object。
- 每个网格要预测B个box,坐标+confidence,共5维。confdience计算如下,
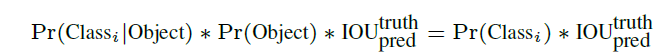
- 每个网格预测5维,同时还要预测类别信息(假设有C类),则输出为S×S×(5×B + C)。文中S为7,B取2
- ,VOC数据集的C为20
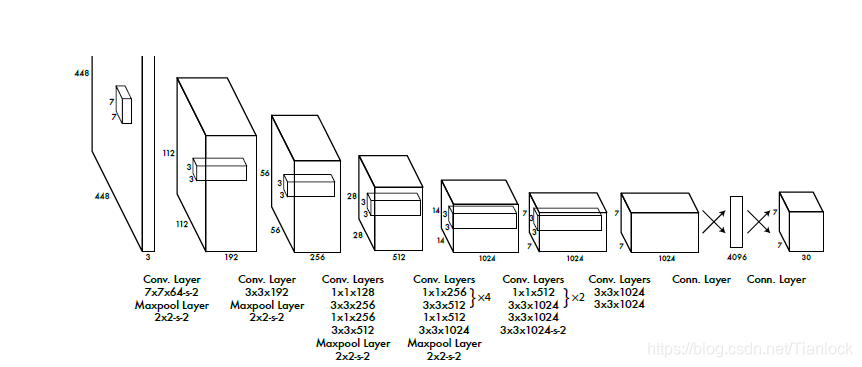
网络
其他细节 - 改用 leaky ReLU激活函数:修正了数据的分布,保留了负值,是的负的数据不会全部丢失。增加了模型的泛化能力。
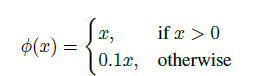
- 损失函数计算,使用sum-squared error loss,存在的问题:第一,8维的localization error和20维的classification error同等重要显然是不合理的; 第二,如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence push到0,相比于较少的有object的网格,这种做法是overpowering的,这会导致网络不稳定甚至发散。
解决方法:坐标的预测有更大的权值(5),对没有object的box的confidence权值更小(0.5),有object的box的confidence正常(1)。


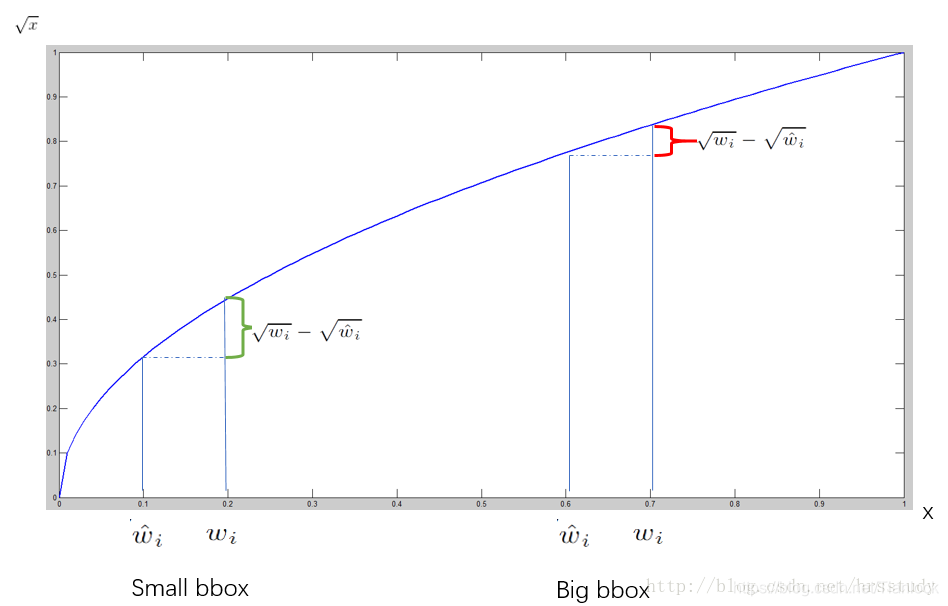
- 对不同大小的bbox预测中,相比于大bbox预测偏一点,小box预测偏相同的尺寸对IOU的影响更大。而sum-square error loss中对同样的偏移loss是一样。为了缓和这个问题,作者用了一个巧妙的办法,就是将box的width和height取平方根代替原本的height和width。
- box与gtbox的iou最大的predictor负责当前的object。
缺点
互相靠近的物体,小群体检测效果不好,如果出现新的不常见的长宽比的目标,泛化能力弱,定位不准确,尤其是在处理大小目标时。
YOLO v2
Yolo v1版本有两个缺点:1.定位不准确,2.召回率低
改进点:
- 网络加入了BN层
- 高精度的预训练,原来预训练的ImageNet的尺寸从224 变为448
- 借助Faster RCNN中anchor的思想,首先更改了网络模型,去除了原来网络的全连接层和最后一个Pooling层,使得最后的卷积层有更高的分辨率,然后缩减网络,用416size大小的输入代替原来448大小的,样做的原因在于希望得到的特征图都有奇数大小的宽和高,奇数大小的宽和高会使得每个特征图在划分cell的时候就只有一个center cell(比如可以划分成77或99个cell,center cell只有一个,如果划分成88或1010的,center cell就有4个)。为什么希望只有一个center cell呢?因为大的object一般会占据图像的中心,所以希望用一个center cell去预测,而不是4个center cell去预测。网络最终将416416的输入变成1313大小的feature map输出,也就是缩小比例为32。
- 原来的Yolo是将图像分成7×7的网格,每个网格预测两个box,现在每个grid预测9个anchor
- Dimensional Clusters
我们知道在Faster R-CNN中anchor box的大小和比例是按经验设定的,然后网络会在训练过程中调整anchor box的尺寸。但是如果一开始就能选择到合适尺寸的anchor box,那肯定可以帮助网络越好地预测detection。所以作者采用k-means的方式对训练集的bounding boxes做聚类(加入先验知识),试图找到合适的anchor box。
另外作者发现如果采用标准的k-means(即用欧式距离来衡量差异),在box的尺寸比较大的时候其误差也更大,而我们希望的是误差和box的尺寸没有太大关系。所以通过IOU定义了如下的距离函数,使得误差和box的大小无关: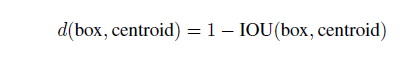
在分析了聚类的结果并平衡了模型复杂度与recall值,作者选择了K=5。 - direct location prediction:并没有采用直接预测offset的方法,沿用了yolo算法中直接预测相对于grid cell的坐标位置的方式。
faster RCNN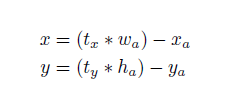
yolo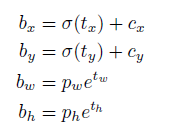
yolo预测的是边界框的中心店相对于对应cell左上角的相对偏移量。cxcy分别是一个cell和图像左上角的距离。如下图所示:
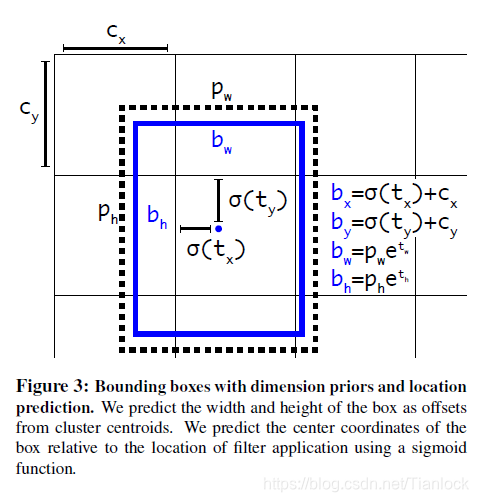
- Fine-Grained Features
在最后13×13size的特征层和前一个26×26大小的特征层进行连接。吸收更大的特征层,有利于检测较小的object。 - 多尺度训练 [320,352… 608].均为32的倍数。
- 另外,需腰注意的是,v2中每个grid cell 预测五个box,每个box(5个坐标,20类)。与v1不同,v2针对同一个gridcell中的box的类别是不同的。
Darknet
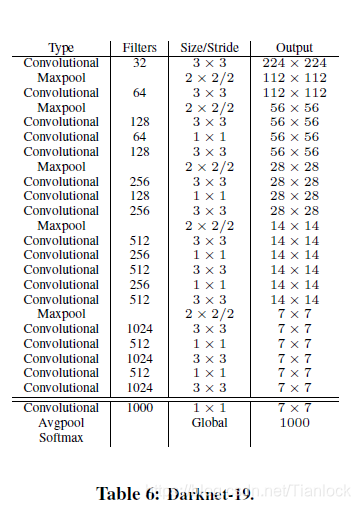
为了使目标检测更快,作者提出了新的网络模型,darknet。类似于VGG,反复堆叠3×3的卷积层,同时用全局池化代替全连接。