目标检测总结:YOLO系列(2)
Yolo v3
v3版本针对yolo又提出了一些小的改进。
- 使用逻辑回归预测边界框的分数
- 用逻辑回归取代softmax预测类别,将原来的但标签多分类变为了多标签多分类,因为在一些复杂场景下,一个object可能不止属于1类。用逻辑回归层做二分类,用到了sigmoid。
- multiscale anchor: 将v2中的fine-grained feature 进一步加强,融合了三个scale的特征(13 26 52)。anchor的初始尺寸还是利用v2中的聚类方法得到,总共有九中聚类结果。
- 网络结构方面,Darknet 53, 基本采用全卷积,并且引入了Residual结构
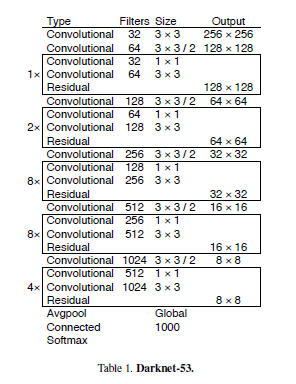
总结:
创新点主要有:
1,使用了不同scale的 anchor
2,用逻辑回归代替softmax
3,Darknet53
文章的内容并不多,并且 多个scale anchor哪里说得不是很清楚,需要结合源码来理解。
prediction across scales:
看了yolov3的源码,其实这一部分的操作比较简单,将13×13的featuremap进行上采样至26×26,然后与上一层26×26的featuremap进行concat,这样做的好处是将高层的语义信息和底层的细粒度信息结合起来,是的featuremap有更好的表征。同时26×26的map在原始图像中的anchor更小,可以监测到更小的目标。