目标检测总结:RCNN系列(1)
之前主要是回顾了常见的卷积神经网络,下面开始回顾目标检测相关的算法。首先RCNN系列说起。
RCNN
RCNN算法主要包括两部分部分:1.region proposal 生乘候选框,2.对选出的region proposal进行特征提取。
- region proposal:图像中物体可能存在的区域应该是有某些相似性或者连续性区域的。因此,选择搜索基于上面这一想法采用子区域合并的方法进行提取bounding boxes候选边界框。首先,对输入图像进行分割算法产生许多小的子区域。其次,根据这些子区域之间相似性(相似性标准主要有颜色、纹理、大小等等)进行区域合并,不断的进行区域迭代合并。每次迭代过程中对这些合并的子区域做bounding boxes(外切矩形),这些子区域外切矩形就是通常所说的候选框。RCNN算法就是通过 selective search进行候选框的选择。
- 特征提取:将所有的region proposal进行resize到227的大小。然后输入到卷积神经网络,通过神经网络进行特征提取,每个region都会产生一个4096维的特征。另外,文章提到了两个resize方式:1、是将包围盒的短边扩展为和长边一样大,使之成为正方形再缩放,这样做的好处是能保证目标的比例不会变化,2、是将包围盒两边加上图像均值的padding,再缩放,同样保证了目标的比例不会变化。
由于RCNN是介绍的第一篇目标检测算法,很多算法细节第一次写,就写的比较细致。我们将算法的训练过程和测试过程分开描述。
训练过程:
1,有监督的预训练,利用ImageNet,只有类别的标签,没有位置的标注
2,finetuning:将与gtbox的iou>0.5的region作为正例,其他的作为负例进行finetuning,每次迭代32个正例,96个负例,batchsize为128,输出类别为21(voc20类+1类background)
3,SVM训练:对每个类都训练一个线性的SVM分类器。正样本为gtbox,负样本为与gtbox的iou<0.3的region proposal, 由于负样本太多,训练中采用了 hard negative mining的策略。hard negative mining,其实就是对分类错误的样本重新训练。
4,bound-box-regression 训练。这一步就是为了纠正region proposal与gtbox之间的误差,因为regionproposal即使SVM后得到的confidence较高,但region proposal 与 gtbox相差仍可能很大。其输入为4096维特征,输出为平移尺度和缩放尺度。其中d(p)为4096维特征。
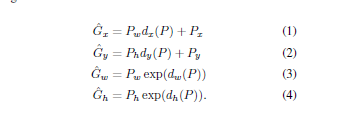
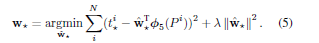
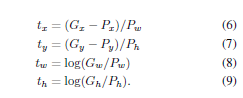
测试过程
- selective search 提取regionproposal,2000个
- 对regionproposal 进行放缩到训练的统一大小的size
- 输入CNN,得到特征。
- 4906特征输入SVM得到得分
- NMS,删除重叠的regionproposal
- 利用box regrssion得到最终的box
RCNN是RCNN系类的开山之作,但是其速度较慢,不能端对端的训练,但也算是开two-stage支先河。
SPP-NET
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(空间金字塔池化),有Kaiming He提出。
在SPPnet之前,所有的神经网络的输入都是需要固定大小的,比如之前RCNN,为了满足这个条件,需要将不同大小的region-proposal进行resize到统一尺寸,
创新点:SPP-net在卷积层和全连接层之间加入了金字塔池化层,使用这种方式,可以让网络输入任意大小的图片,而且还会生成固定大小的输出。
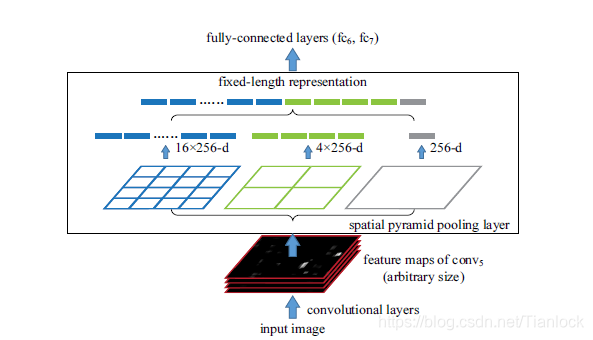
如上图所示,金字塔池化层就是对特征进行划块来提取特征,上图将4×4,2×2,1×1的网格放到特征图上然后可以得到16+4+1=21块,每个块提取一个特征,得到了21维的向量。这种以不同大小格子的组合方式来池化的方法就是空间金字塔池化。其优点在于不论特征图的大小是多少,只要特征金字塔确定了,总能得到同一尺寸的向量特征。值得一提的是1×1的网格其实就是全局池化。
SPPnet用于目标检测
之前介绍的RCNN在对region proposal的处理方式是将其resize到固定大小来解决CNN的尺度问题,然后将所有的proposal输入CNN,十分的耗时,一张图有2000个region,就要进行2000次的特征提取。有了SPPNET,只需要在整张图片上提取一次特征,然后在每个特征图的候选框上应用金字塔池化,就可以得到同一纬度的特征向量。
论文中也是利用selective search的方法产生2000个候选框,金子塔为4层(1,2,3,6共50)。每个候选框产生50*256维的向量。另外,在region坐标映射到候选框的时候,左上的坐标是向下取整,右下的坐标向上取整。
把SPPNET加入RCNN系列的原因是,其算法除了在特征计算方面只对每张图进行一次特征提取之外,其余细节和RCNN类似,并且为RCNN系列提供了新的思路,所以也把SPPNET加进来。
Fast RCNN
Fast RCNN 是 RCNN作者的改进之作,RCNN有几个缺点:1多步操作,步骤繁琐,2耗时耗力,主要原因是没有share computing 即每个region单独计算特征。
改进:
- 参考SPPNET,对每张图只进行一次卷积,通过将region映射到特征层,,然后利用ROIpooing(池化金字塔的简化),得到相同尺度的特征。ROIpooling其实就是一层SPP,将Proposal内的特征划分成7×7的大小。
- 将regressor放入网络,不再是单独处理 box regression。同时用softmax代替原来的SVM。之前RCNN的时候为什么不同softmax代替SVM呢,因为微调和训练SVM的正负样本的阈值不同。
其他算法细节
- 训练中,每个batch 2张图,128个roi(其实就是region),正例25%,与gtbox的iou> 0.5, 负例75%。iou<0.5.
- 损失函数:损失函数的定义是将分类的loss和回归的loss一同考虑。
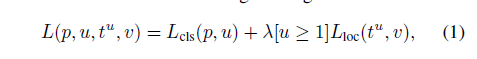
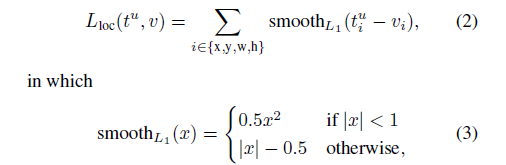
cls损失函数为交叉熵。
本文主要介绍了RCNN系列的前两篇,由于计算速度以及精度方面的缺点,现在目标检测已经很少使用这些算法了,但对于理解RCNN系列的终极篇Faster RCNN有一定的帮助。