前面博文介绍了目标检测的概况,以及【RCNN系列】的目标检测模型,这个系列介绍【YOLO系列】的目标检测模型。本篇文章介绍YoloV1网络模型的概况。
YoloV1论文:https://arxiv.org/pdf/1506.02640
YoloV1论文翻译:https://zhuanlan.zhihu.com/p/35416826
一、概述
Yolo(You Only Look Once),你只需要看一次,通过这个任性的名字,就可以稍微区分出其与【RCNN】系列的最重要的不同之处,YOLO是end-to-end模式,并且是真正意义上的 Real-Time Object Detection。(YoloV1 mAP:63%,fps:45;Faster RCNN mAP:73%,fps:7)
【传统检测方法】基于区域提名的,大致分为三个步骤:先使用不同的方法(滑动窗口、选择搜索、区域提案)提取区域的特征图,然后再使用分类器进行识别,最后回归预测。例如:R-CNN、SPPNet、Fast R-CNN、Faster R-CNN。
【改进检测方法】基于端到端的(end to end),无需候选区域。
二、网络模型

YOLO使用了24个级联卷积层和最后2个全连接层,交替的1×1卷积层降低了前面层的特征空间。在ImageNet分类任务上使用分辨率的一半(224×224输入图像)对卷积层进行预训练,然后将分辨率加倍进行目标检测。

2.1 Yolo实现思路:
1、将一副图片分成SxS个网格(Grid Cell);
2、每个网格要预测B个bounding box,每个box除了要回归自身的位置之外,还要附带预测一个Confidence:
Confidence由两部分乘积所得,Pr(Object)表示该bounding box是否含有object,Iou(truth/pred)表示预测与真实框的交并比。
3、每个网格要预测针对20个类别的条件概率(同一个网格B个bboxes共享一个条件概率)
训练:
测试:
4、在Pascal VOC中,YOLO检测系统的图像输入为448×448,S=7,B=2,一共有20个class(C=20),输出就是7×7×30的一个tensor。如上图所示,7*7*30中的30包含2个boundingbox预测的(x,y,w,h,c) + 20个类别。
2.2 Yolo实现细节
1、yolov1返回什么
【YOLO返回】返回S*S*(B*5 + C) = 7 * 7 (2* 5 + 20)tensor, 该7*7*30的tensor包含了 中心、宽高偏移以及置信度,和每个类别得分。

2、yolov1如何预测
【YOLO预测】预测目标的偏移和得分。 此处预测的(x, y )(w, h)和【RCNN】系列一样预测是偏移,而yolo还会进一步将该偏移进行归一化处理,也就是输出的(x, y)是相对于相对应网格的偏移得到的归一化数据,输出的(w, h)是相对于整张图片宽高归一化得到的数据。
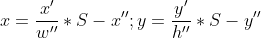
在此,规格宽高(w'', h'')就是整体图片打宽和高,规则中心(x'', y'')就是((0,0),(0,1),...(7,7)) ,如上图规格中心则为(4,2)

3、yolov1如何筛选
【横向筛选】:在不同的bbox里面都预测到某个目标,依据Confidence,即IOU。
如上图所示:
首先:将所有bbox(7*7*2=98个)中对于一个类别得分小于阈值的得分设置为0;
其次:将所有更新后得分的bbox排序,按照得分从高到底,选择该类别中得分最高的设置为bbox_max;
然后:将其余bbox类别的区域与bbox_max区域做IOU计算,如果得分大于阈值,则设置该bbox得分为0;【NMS】
然后:选择满足第1步的次得分高值重复进行2、3步的步骤,直至计算结束。
最后:针对下一个类别进行1、2、3、4的步骤。
【总结】:这个流程就会筛选出不同bbox对于同一个目标的预测情况,筛选出一个最好的。
【纵向筛选】:在同一个bbox里面预测到多个目标,依据P(Class),即分类得分。
找到20个类别里面得分最高的,也就是该bbox可能的类别。


4、yolov1损失计算
【损失】yolov1的损失包括3个环节,5部分。
第一环节:bbox的中心和宽高:
当有目标时中心的损失函数
当有目标时宽高的损失函数,添加根号防止小物体变
化影响不明显
第二环节:bbox置信度:
当有目标时置信度损失
当没有目标时置信度损失
第三环节:类别:
预测类别损失
【注意】
1、local损失和classify损失同样重要不合理,因此添加了 λcoord,设置为5;
2、对于不含有目标的bbox的置信度Confidence未将其权重设置为0,而是采用了λnoobj,设置为0.5,因为大多数bbox都不含有目标,如果单纯的将未含有bbox的confidence设置为0,则会造成不平衡;对于含有目标的bbox,对应的权重为1;
3、对于w和h的损失进行开根号处理,是因为不同大小的物体的偏离情况,小物体情况更严重点,如果不开根号,则loss一致,而开根号可以缓和这种不同尺寸物体偏离情况。
三、创新与挑战
1、创新
- YOLO速度非常快。YOLO的基础版本以每秒45帧的速度运行,而快速版本运行速度超过150fps。
- YOLO是在整个图像上进行推断的。与基于滑动窗口和候选框的技术不同,YOLO在训练期间和测试时都会顾及到整个图像,所以它隐式地包含了关于类的上下文信息以及它们的外观。
- YOLO能学习到目标的泛化表征。把在自然图像上进行训练的模型,用在艺术图像进行测试时,YOLO大幅优于DPM和R-CNN等顶级的检测方法。由于YOLO具有高度泛化能力,因此在应用于新领域或碰到意外的输入时不太可能出故障。
2、挑战
- 输入模型的尺度固定,因为输出层包含全连接层。
- 性能比较差,相对于当时最先进的目标检测技术。
- 定位精度不够高,相对于区域提案网络来说,定位不够理想。
总结:yolov1是在15年发明出来的,相对于当时最先进的目标检测模型Faster rcnn的mAP 73%的检测精度,其mAP 63%确实不够出色,但是对于与rcnn的mAP 53%要更优秀,主要是yolo将rcnn 两步走的模式并为一步走,端到端的模式,可谓一个大的改变,端到端的模式导致了训练、推断时间大幅度的降低,是一个真正意思上的可以达到实时检测(Faster rcnn fps 7, yolov1 fps 45)的模型。yolov1是【Yolo】系列的第一个版本,真正的改变了传统目标检测的思想,原来可以不用先提取区域再进行分类,原来目标检测可以这样玩,而这还只是yolo的开始。
