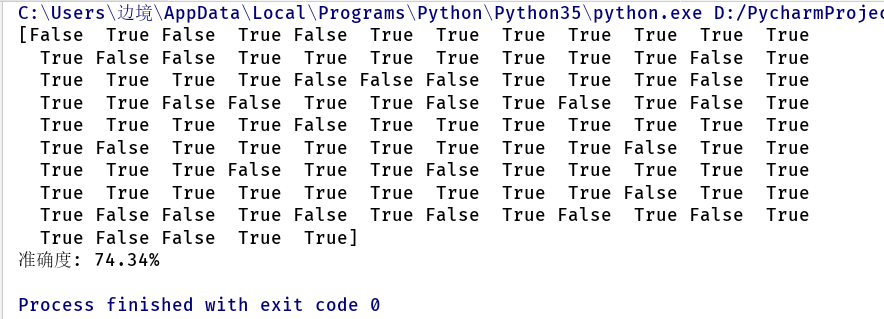
注:本人纯粹为了练手熟悉各个方法的用法
使用高斯朴素贝叶斯对鸢尾花数据进行分类
代码:
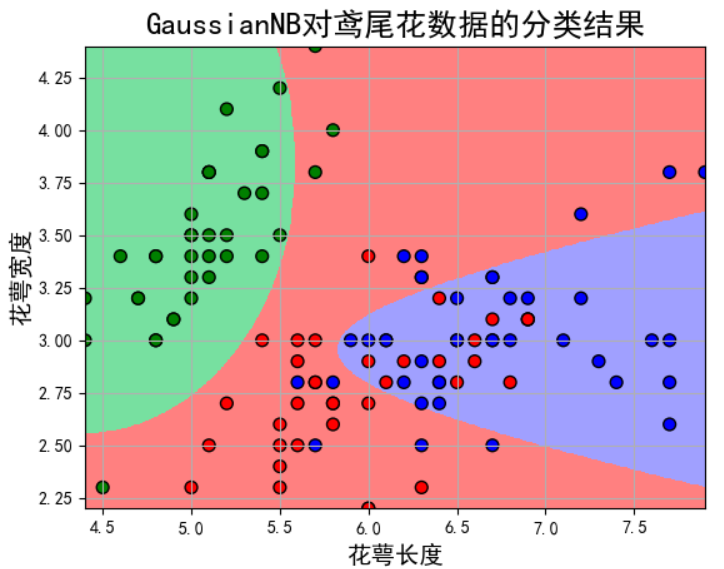
1 # 通过朴素贝叶斯对鸢尾花数据进行分类 2 3 from sklearn import datasets 4 from sklearn.model_selection import train_test_split 5 from sklearn.naive_bayes import MultinomialNB, GaussianNB 6 import matplotlib.pyplot as plt 7 import numpy as np 8 import matplotlib as mpl 9 from sklearn.preprocessing import StandardScaler 10 from sklearn.pipeline import Pipeline 11 12 iris = datasets.load_iris() # 加载鸢尾花数据 13 iris_x = iris.data # 获取数据 14 # print(iris_x) 15 iris_x = iris_x[:, :2] # 取前两个特征值 16 # print(iris_x) 17 iris_y = iris.target # 0, 1, 2 18 x_train, x_test, y_train, y_test = train_test_split(iris_x, iris_y, test_size=0.75, random_state=1) # 对数据进行分类 一部分最为训练一部分作为测试 19 # clf = GaussianNB() 20 # ir = clf.fit(x_train, y_train) 21 clf = Pipeline([ 22 ('sc', StandardScaler()), 23 ('clf', GaussianNB())]) # 管道这个没深入理解 所以不知所以然 24 ir = clf.fit(x_train, y_train.ravel()) # 利用训练数据进行拟合 25 26 # 画图: 27 x1_max, x1_min = max(x_test[:, 0]), min(x_test[:, 0]) # 取0列特征得最大最小值 28 x2_max, x2_min = max(x_test[:, 1]), min(x_test[:, 1]) # 取1列特征得最大最小值 29 t1 = np.linspace(x1_min, x1_max, 500) # 生成500个测试点 30 t2 = np.linspace(x2_min, x2_max, 500) 31 x1, x2 = np.meshgrid(t1, t2) # 生成网格采样点 32 x_test1 = np.stack((x1.flat, x2.flat), axis=1) 33 y_hat = ir.predict(x_test1) # 预测 34 mpl.rcParams['font.sans-serif'] = [u'simHei'] # 识别中文保证不乱吗 35 mpl.rcParams['axes.unicode_minus'] = False 36 cm_light = mpl.colors.ListedColormap(['#77E0A0', '#FF8080', '#A0A0FF']) # 测试分类的颜色 37 cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b']) # 样本点的颜色 38 plt.figure(facecolor='w') 39 plt.pcolormesh(x1, x2, y_hat.reshape(x1.shape), cmap=cm_light) # y_hat 25000个样本点的画图, 40 plt.scatter(x_test[:, 0], x_test[:, 1], edgecolors='k', s=50, c=y_test, cmap=cm_dark) # 测试数据的真实的样本点(散点) 参数自行百度 41 plt.xlabel(u'花萼长度', fontsize=14) 42 plt.ylabel(u'花萼宽度', fontsize=14) 43 plt.title(u'GaussianNB对鸢尾花数据的分类结果', fontsize=18) 44 plt.grid(True) 45 plt.xlim(x1_min, x1_max) 46 plt.ylim(x2_min, x2_max) 47 plt.show() 48 y_hat1 = ir.predict(x_test) 49 result = y_hat1 == y_test 50 print(result) 51 acc = np.mean(result) 52 print('准确度: %.2f%%' % (100 * acc))
图片显示:
正确率: