KNN算法介绍详见:https://blog.csdn.net/Nicht_sehen/article/details/80495884
原理详见:维基百科
题外话:维基百科真的是个好东西 (:D)
查看数据
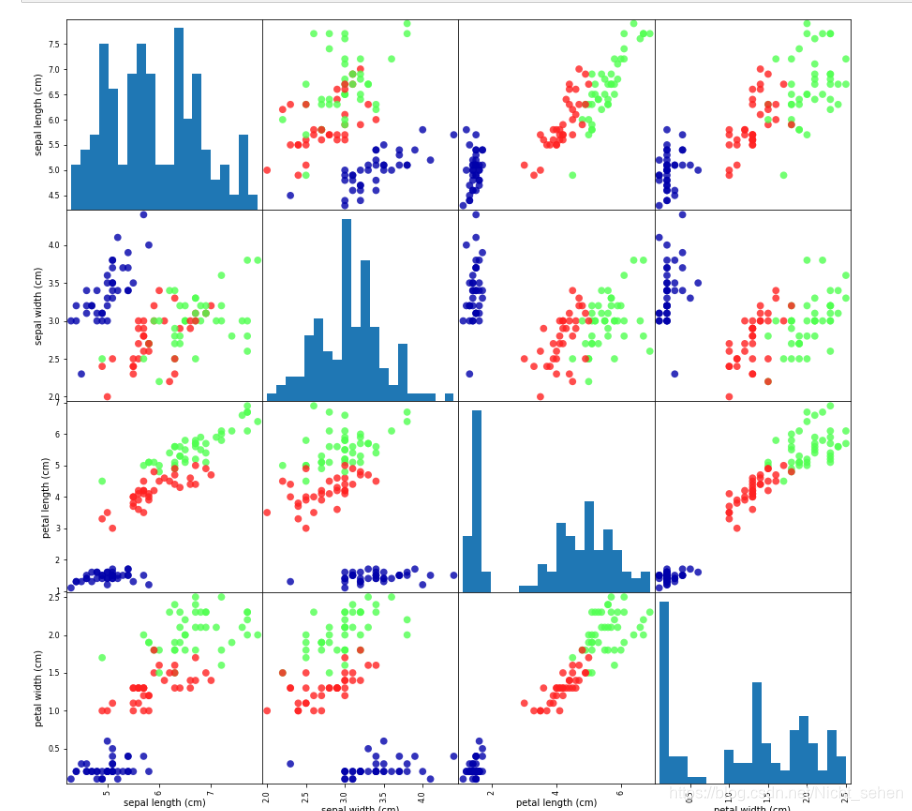
首先我们来看一下数据集:
import pandas as pd
import mglearn
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris_dataset = load_iris()
# 随机划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'],iris_dataset['target'], random_state=0)
# 将训练集转化为dataframe 使用pandas画图
iris_dataframe = pd.DataFrame(X_train, columns = iris_dataset.feature_names)
g = pd.plotting.scatter_matrix(iris_dataframe, c = y_train,figsize = (15,15),marker = 'o',hist_kwds = {'bins':20},s=60,alpha=0.8,cmap=mglearn.cm3)
训练模型
knn = KNeighborsClassifier(n_neighbors = 1) # "邻居"的数目,设为1
knn.fit(X_train,y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=30,metric='minkowski',metric_params=None,n_jobs=1,n_neighbors=1,p=2,weights='uniform')
预测类别
预测花萼长5cm宽3cm 花瓣长1cm宽0.5cm的品种
X_new = np.array([[5,3,1,0.5]])
prediction = knn.predict(X_new)
print("这个鸢尾花的品种为:{}".format(iris_dataset['target_names'][prediction]))
输出:
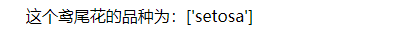
但是我们也不知道这个预测结果是不是正确的,这时候需要对模型进行评估
评估模型
对测试集中每朵鸢尾花进行预测,并将结果与target进行对比,计算准确度
y_pred = knn.predict(X_test)
print("准确度为:{:.3f}".format(np.mean(y_pred == y_test)))
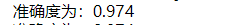
可知精确度为97.4%
注:也可以用knn对象的score方法计算
print("准确度为:{:.3f}".format(knn.score(X_test,y_test )))

全部代码
import pandas as pd
import numpy as np
import mglearn
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris_dataset = load_iris()
# 随机划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'],iris_dataset['target'], random_state=0)
# 将训练集转化为dataframe 使用pandas画图
iris_dataframe = pd.DataFrame(X_train, columns = iris_dataset.feature_names)
g = pd.plotting.scatter_matrix(iris_dataframe, c = y_train,figsize = (15,15),marker = 'o',hist_kwds = {'bins':20},s=60,alpha=0.8,cmap=mglearn.cm3)
knn = KNeighborsClassifier(n_neighbors=1) # "邻居"的数目,设为1
knn.fit(X_train,y_train)
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=1, p=2, weights='uniform')
# 预测花萼长5cm宽3cm 花瓣长1cm宽0.5cm品种
X_new = np.array([[5,3,1,0.5]])
prediction = knn.predict(X_new)
print("这个鸢尾花的品种为:{}".format(iris_dataset['target_names'][prediction]))
# 对测试集中每朵鸢尾花进行预测,并将结果与label进行对比,计算准确度
y_pred = knn.predict(X_test)
print("准确度为:{:.3f}".format(np.mean(y_pred == y_test)))
print("准确度为:{:.3f}".format(knn.score(X_test, y_test)))
