文章目录
一、pyhton和anaconda的安装
具体过程直,详细请参考
python与anaconda安装(先安装了python后安装anaconda,基于python已存在的基础上安装anaconda)——逼死强迫症、超详解
二、创建虚拟环境,在虚拟环境下安装 numpy、pandas、sklearn包
这里使用的是用命令行创建exam1的虚拟环境
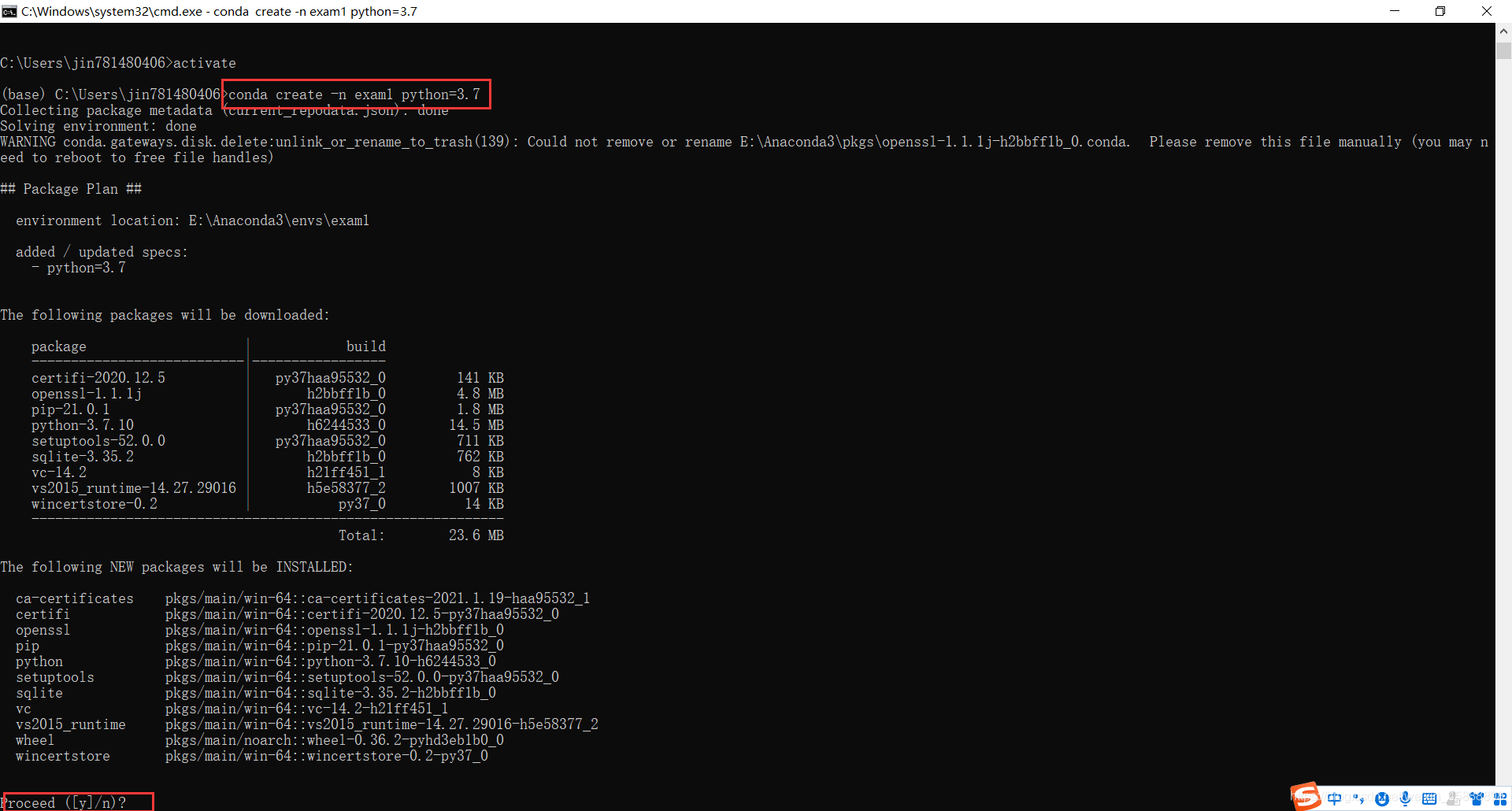
conda create -n exam1 python=3.7
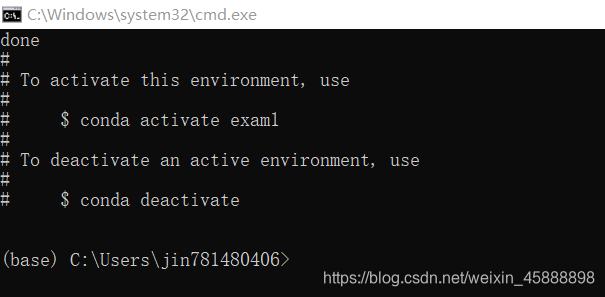
conda activate exam1

在虚拟环境下安装 numpy、pandas、sklearn包
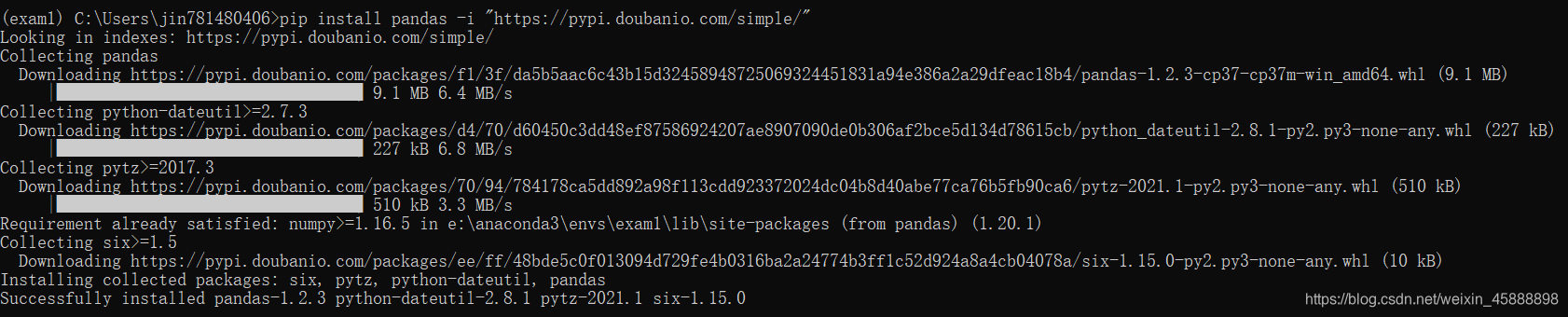
pip install numpy -i "https://pypi.doubanio.com/simple/"
pip install pandas -i "https://pypi.doubanio.com/simple/"
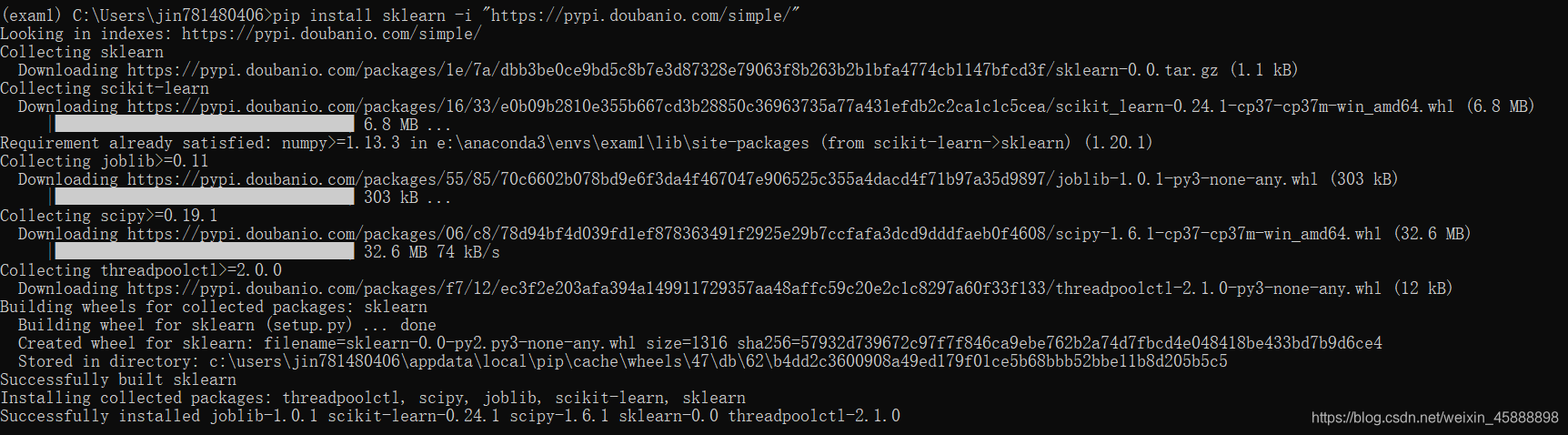
pip install sklearn -i "https://pypi.doubanio.com/simple/"

三、对鸢尾花Iris数据集进行SVM线性分类练习
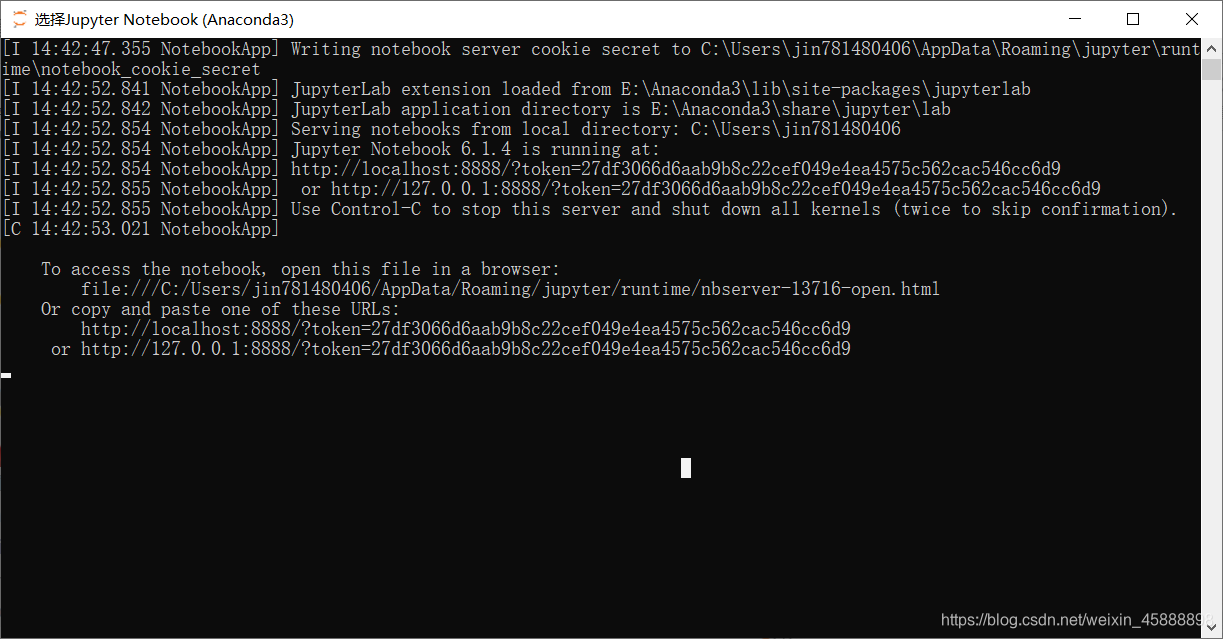
打开Jupyter Notebook
会打开一个cmd和一个网页
切记不要关闭这个cmd

线性分离
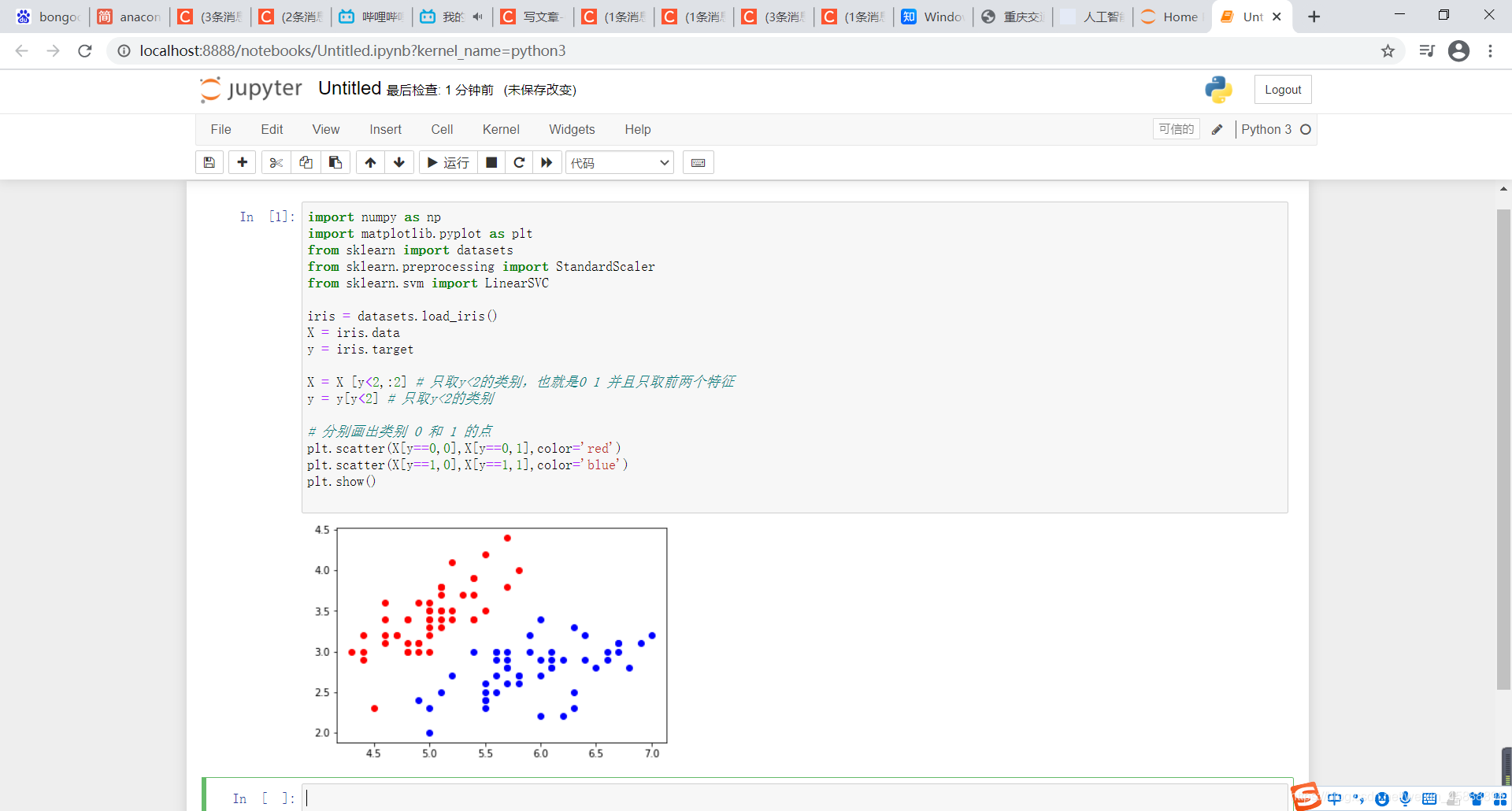
在编辑框输入如下代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
iris = datasets.load_iris()
X = iris.data
y = iris.target
X = X [y<2,:2] # 只取y<2的类别,也就是0 1 并且只取前两个特征
y = y[y<2] # 只取y<2的类别
# 分别画出类别 0 和 1 的点
plt.scatter(X[y==0,0],X[y==0,1],color='red')
plt.scatter(X[y==1,0],X[y==1,1],color='blue')
plt.show()
得到结果如下
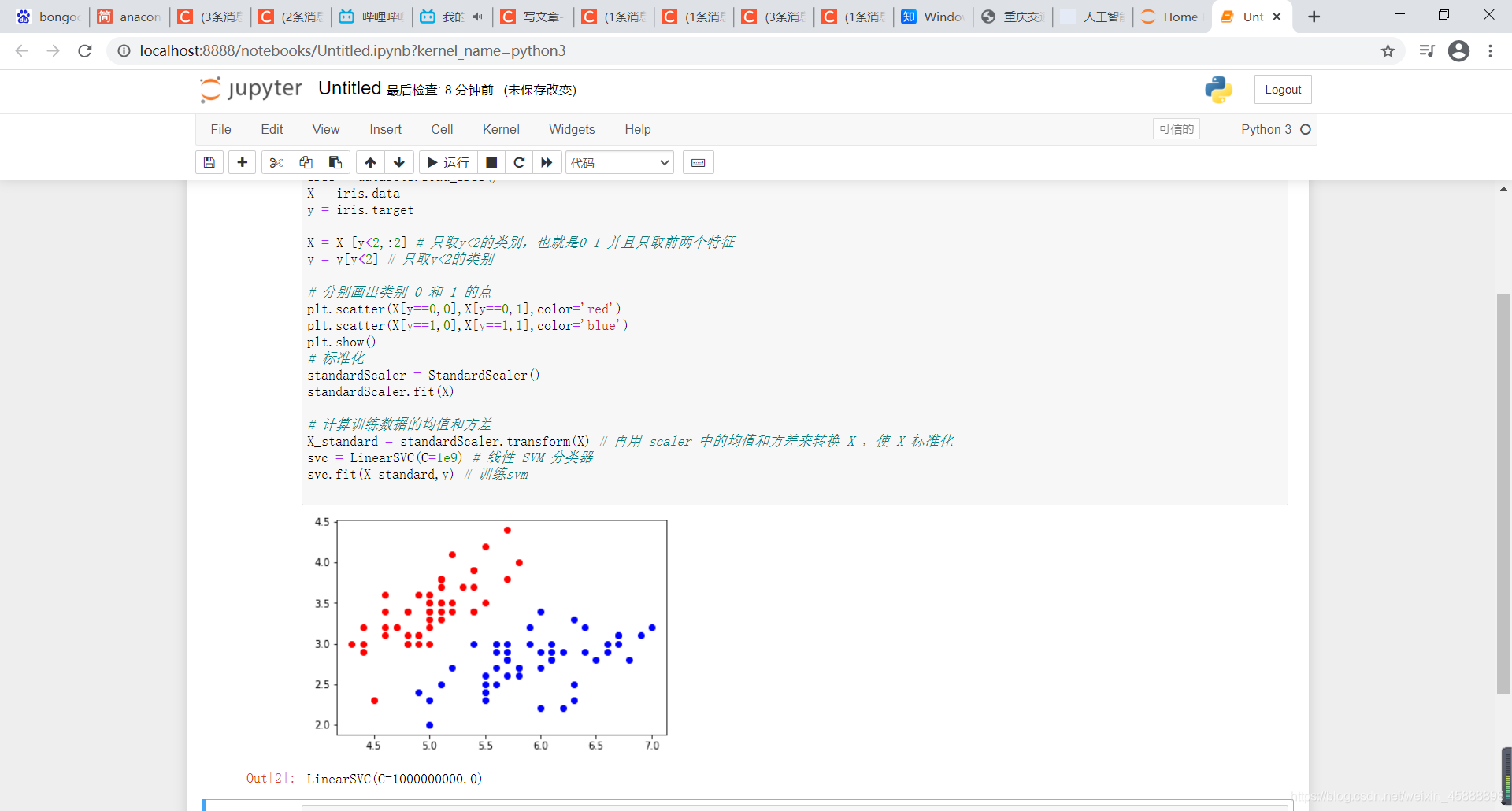
在原有代码下面黏贴以下代码
# 标准化
standardScaler = StandardScaler()
standardScaler.fit(X)
# 计算训练数据的均值和方差
X_standard = standardScaler.transform(X) # 再用 scaler 中的均值和方差来转换 X ,使 X 标准化
svc = LinearSVC(C=1e9) # 线性 SVM 分类器
svc.fit(X_standard,y) # 训练svm
得到结果如下
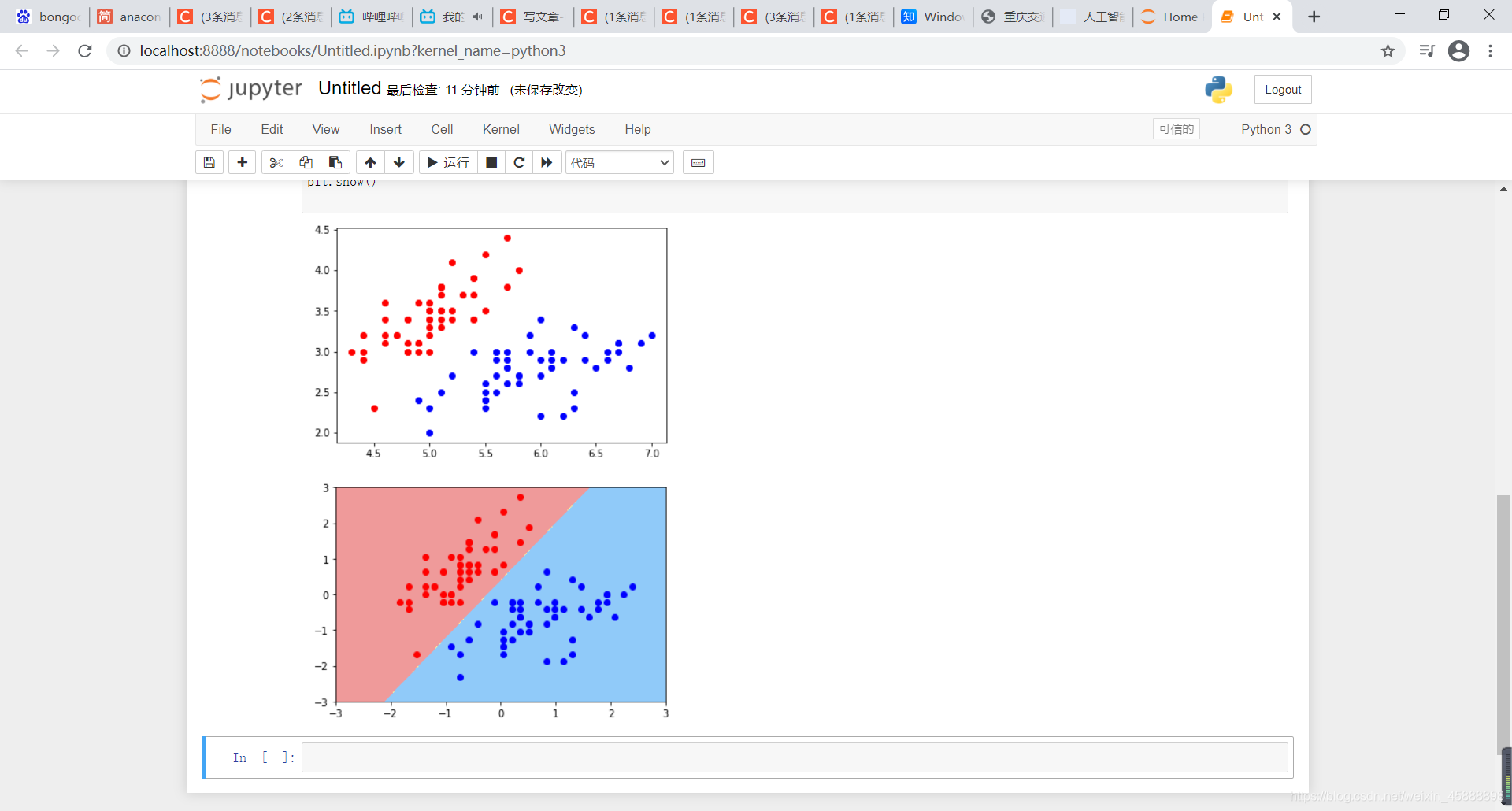
在最开始导入包,然后在刚刚代码最下方黏贴以下代码
from matplotlib.colors import ListedColormap # 导入 ListedColormap 包
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid( np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1)
)
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, cmap=custom_cmap) #绘制决策边界
plot_decision_boundary(svc,axis=[-3,3,-3,3]) # x,y轴都在-3到3之间
# 绘制原始数据
plt.scatter(X_standard[y==0,0],X_standard[y==0,1],color='red')
plt.scatter(X_standard[y==1,0],X_standard[y==1,1],color='blue')
plt.show()
得到结果如下
svc2 = LinearSVC(C=0.01)
svc2.fit(X_standard,y)
plot_decision_boundary(svc2,axis=[-3,3,-3,3]) # x,y轴都在-3到3之间
# 绘制原始数据
plt.scatter(X_standard[y==0,0],X_standard[y==0,1],color='red')
plt.scatter(X_standard[y==1,0],X_standard[y==1,1],color='blue')
plt.show()
得到结果如下
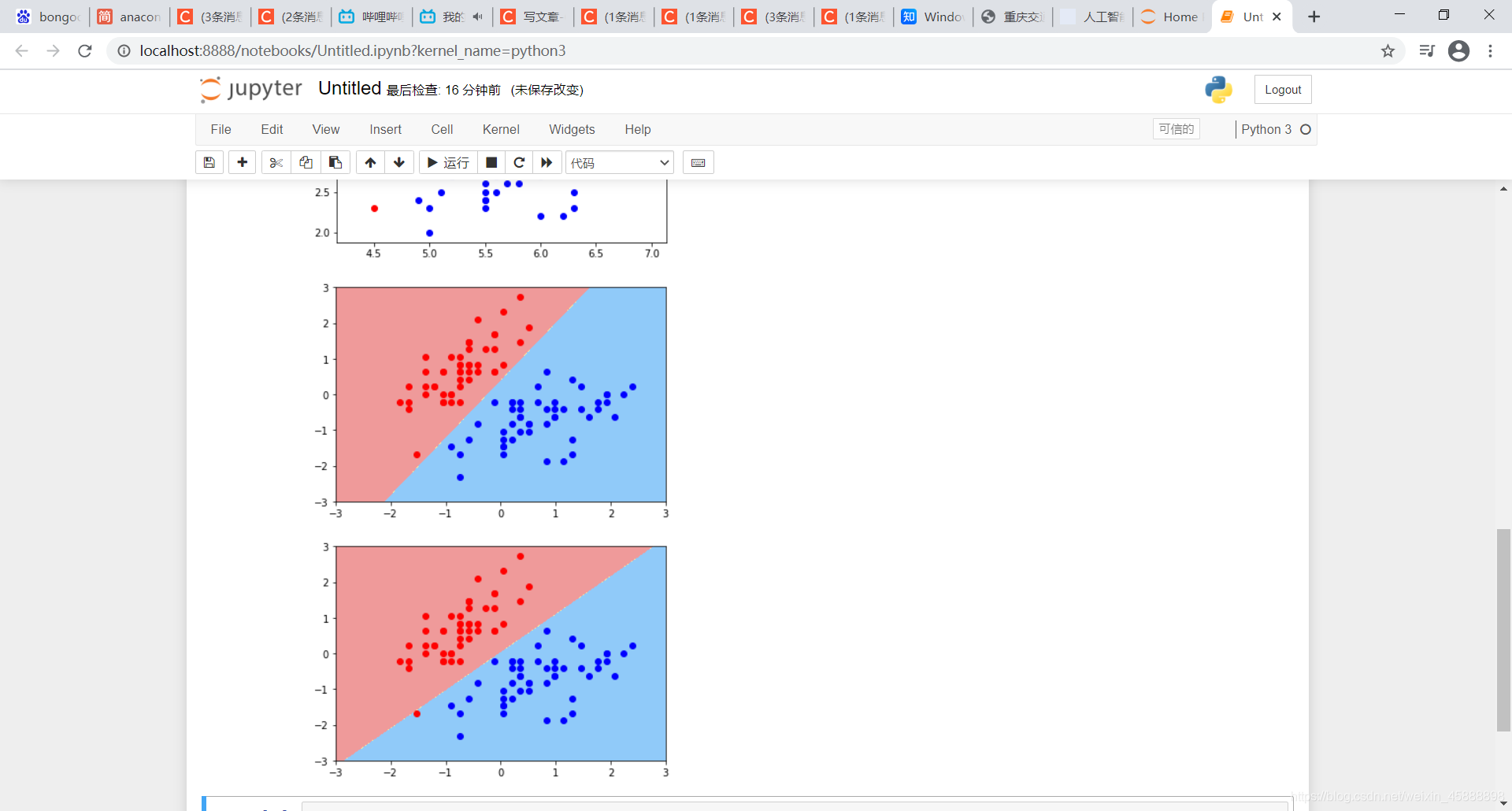
非线性数据分类
多项式特征
在上面代码后面添加如下代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
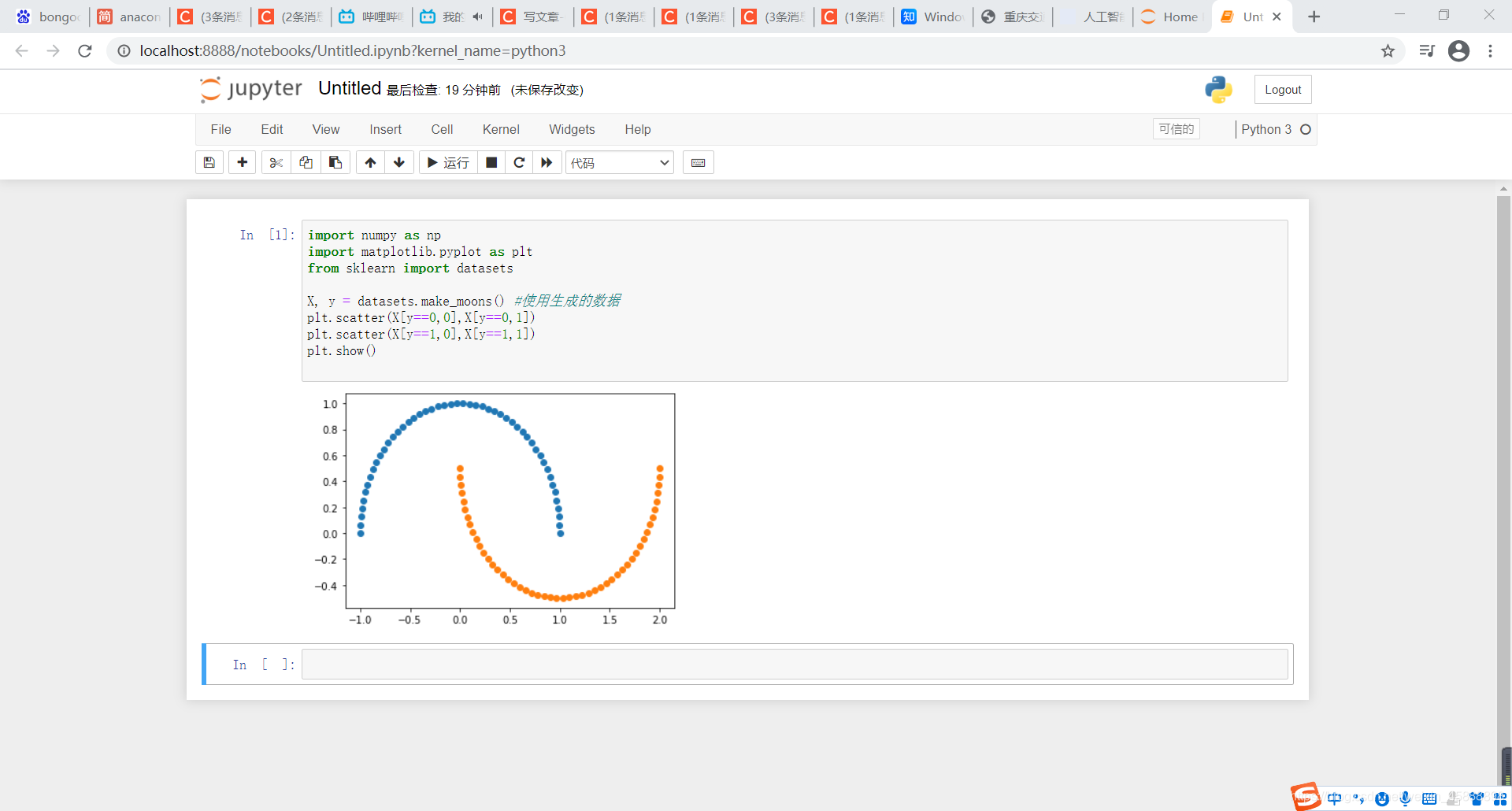
X, y = datasets.make_moons() #使用生成的数据
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
得到结果如下
在上面代码后面添加如下代码
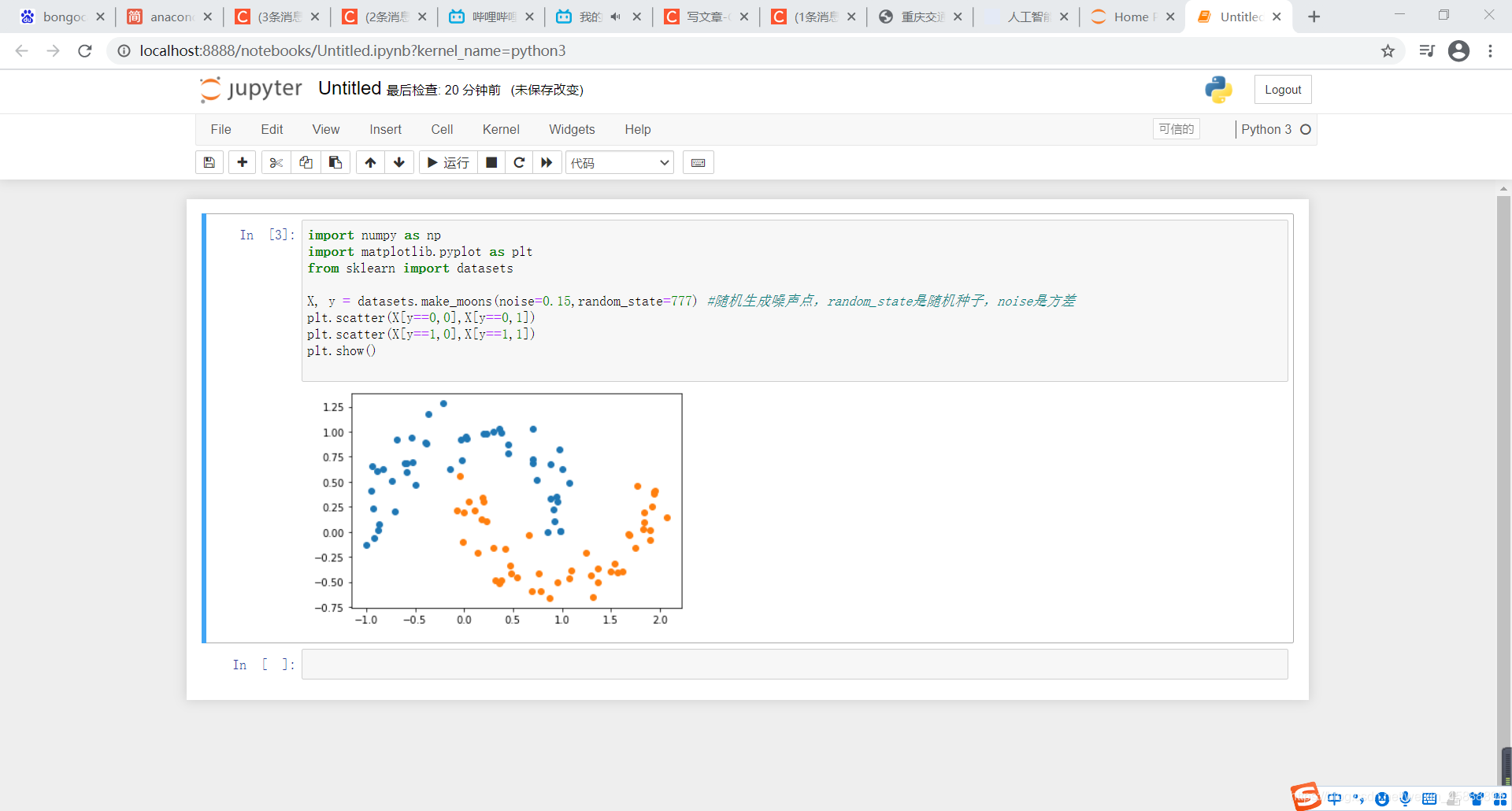
X, y = datasets.make_moons() #使用生成的数据
更改为:
X, y = datasets.make_moons(noise=0.15,random_state=777) #随机生成噪声点,random_state是随机种子,noise是方差
得到结果如下
在上面代码后面添加如下代码
from sklearn.preprocessing import PolynomialFeatures,StandardScaler
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline
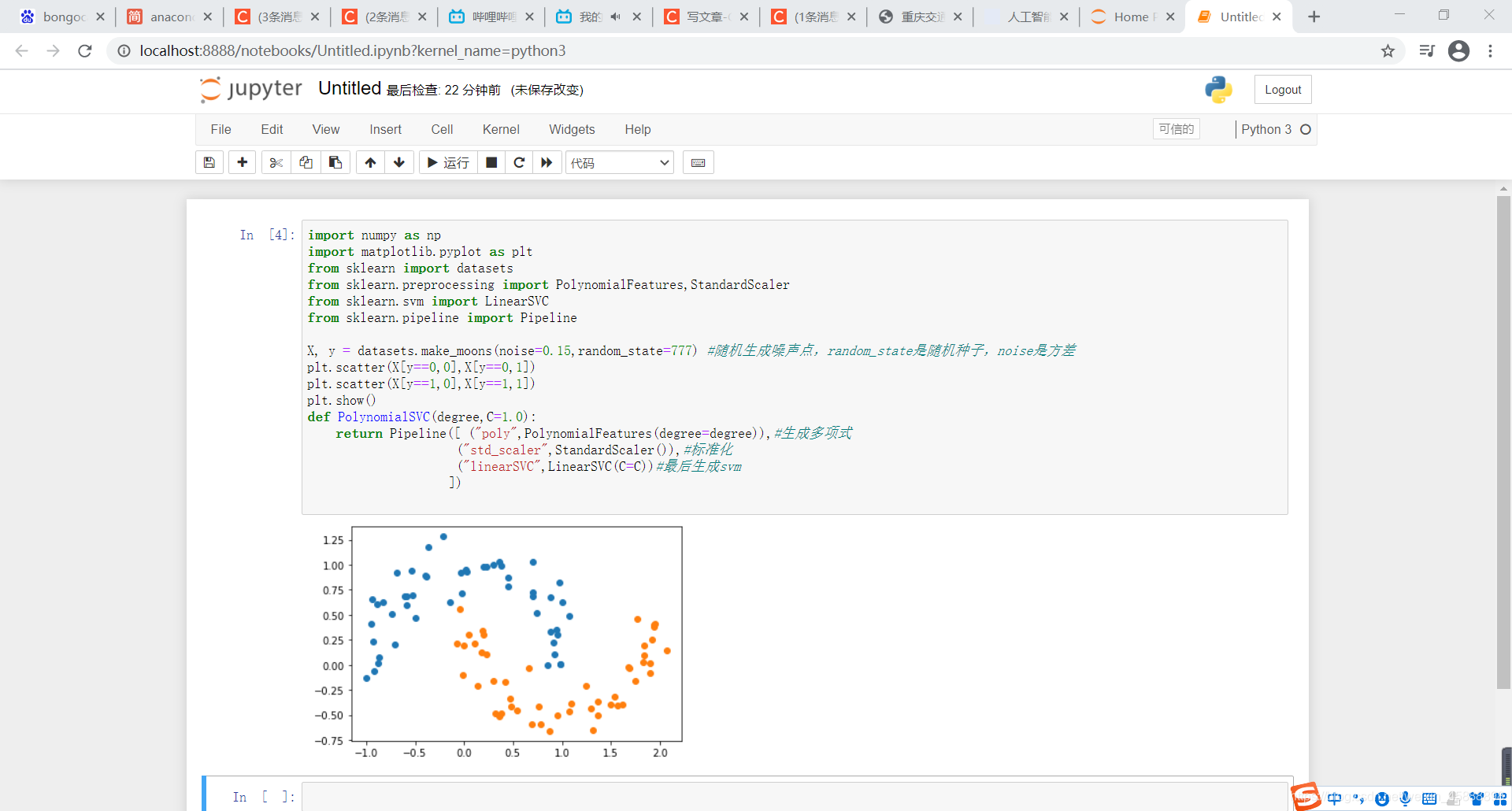
def PolynomialSVC(degree,C=1.0):
return Pipeline([ ("poly",PolynomialFeatures(degree=degree)),#生成多项式
("std_scaler",StandardScaler()),#标准化
("linearSVC",LinearSVC(C=C))#最后生成svm
])
得到结果如下
在上面代码后面添加如下代码
from sklearn.svm import SVC
def PolynomialKernelSVC(degree,C=1.0):
return Pipeline([ ("std_scaler",StandardScaler()),
("kernelSVC",SVC(kernel="poly")) # poly代表多项式特征
])
poly_kernel_svc = PolynomialKernelSVC(degree=3)
poly_kernel_svc.fit(X,y)
plot_decision_boundary(poly_kernel_svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
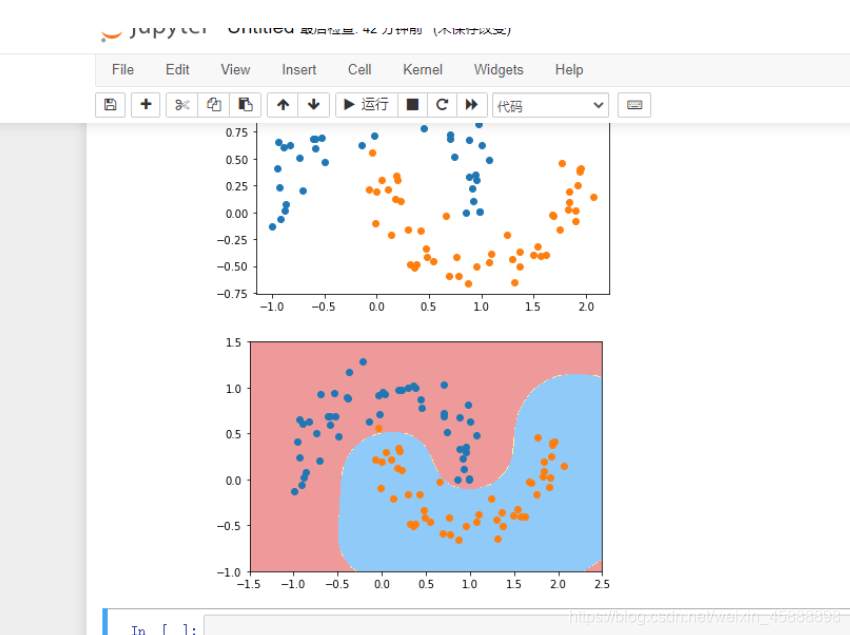
得到结果如下
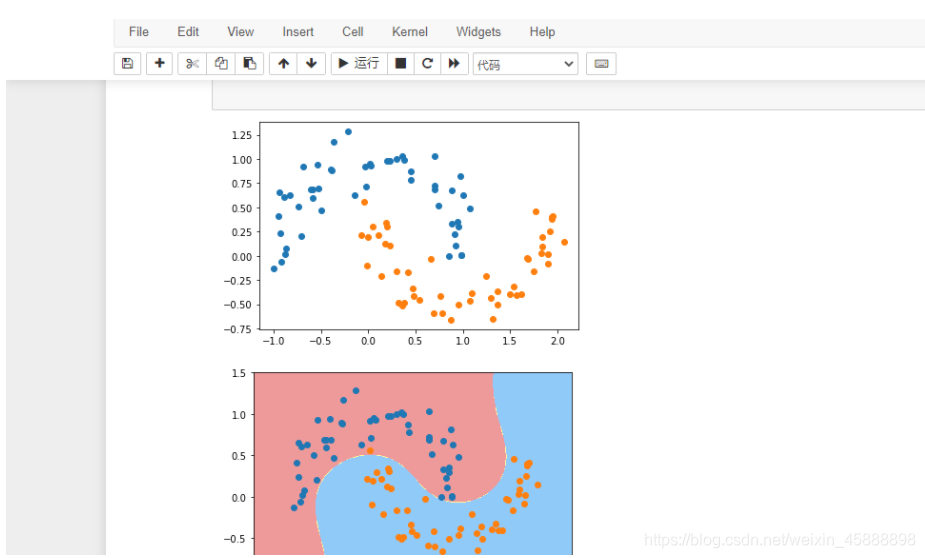
在上面代码后面添加如下代码
from sklearn.svm import SVC
def PolynomialKernelSVC(degree,C=1.0):
return Pipeline([ ("std_scaler",StandardScaler()),
("kernelSVC",SVC(kernel="poly")) # poly代表多项式特征
])
poly_kernel_svc = PolynomialKernelSVC(degree=3)
poly_kernel_svc.fit(X,y)
plot_decision_boundary(poly_kernel_svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
得到结果如下
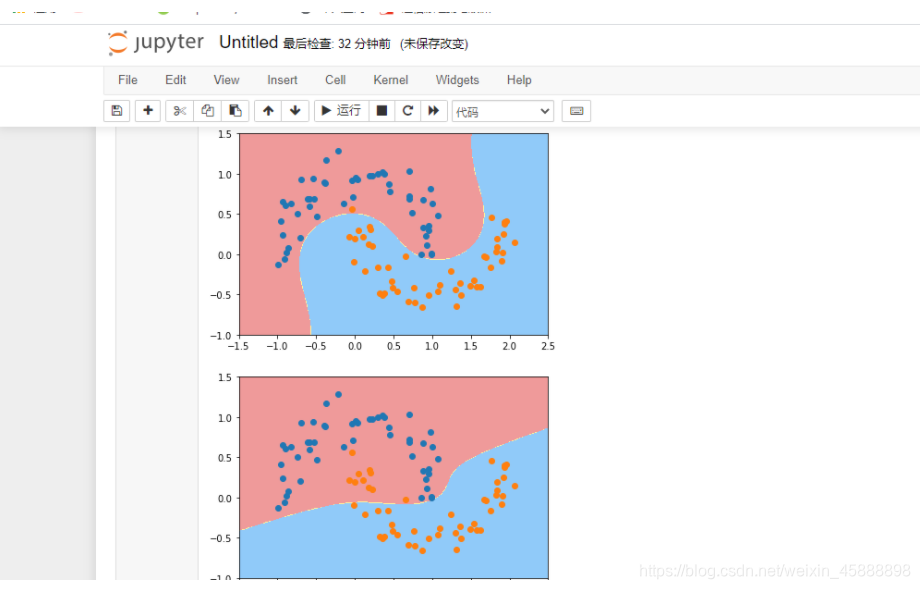
RBF核函数
在上面代码后面添加如下代码
import numpy as np
import matplotlib.pyplot as plt
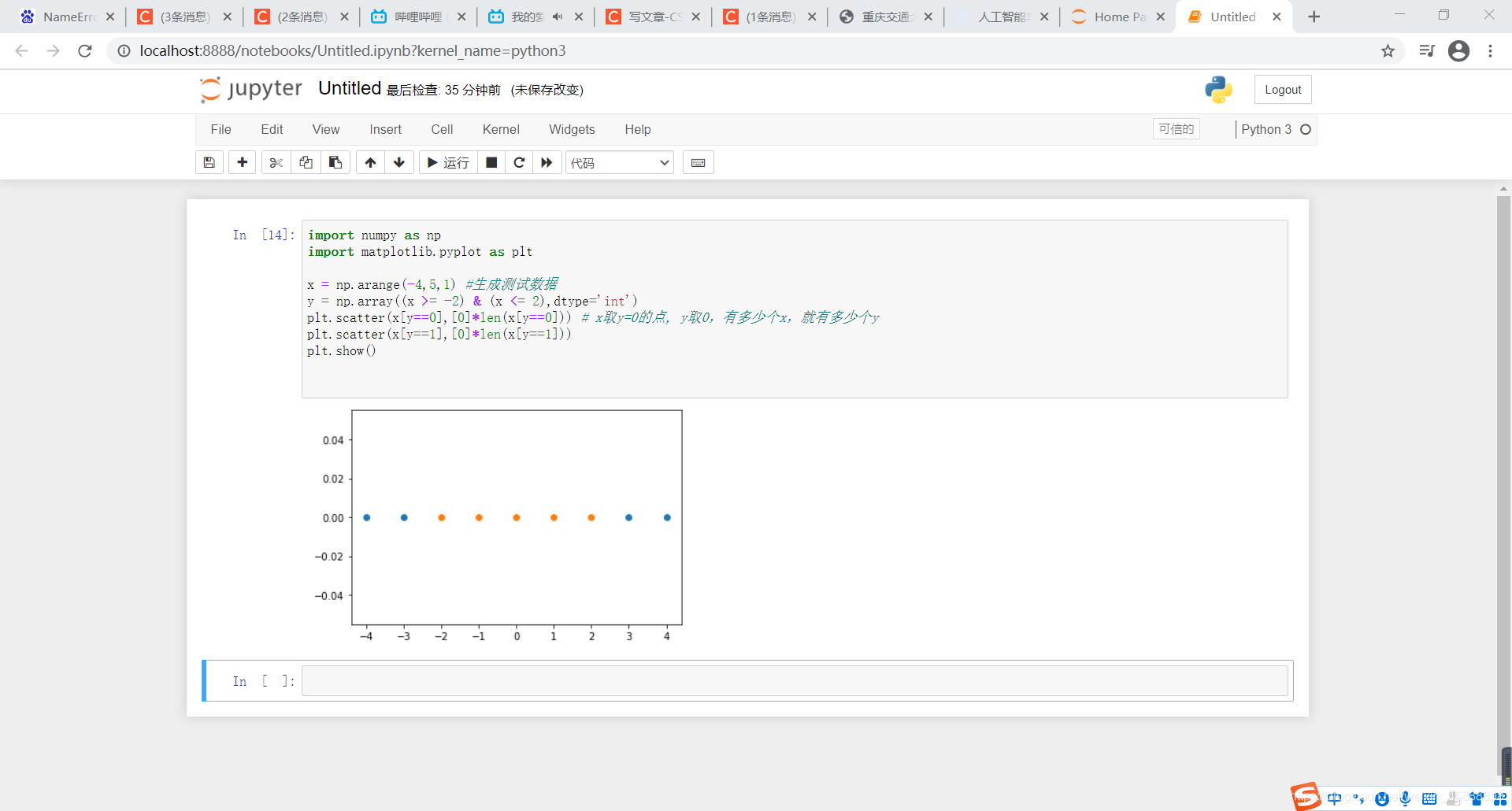
x = np.arange(-4,5,1) #生成测试数据
y = np.array((x >= -2) & (x <= 2),dtype='int')
plt.scatter(x[y==0],[0]*len(x[y==0])) # x取y=0的点, y取0,有多少个x,就有多少个y
plt.scatter(x[y==1],[0]*len(x[y==1]))
plt.show()
得到结果如下
在上面代码后面添加如下代码
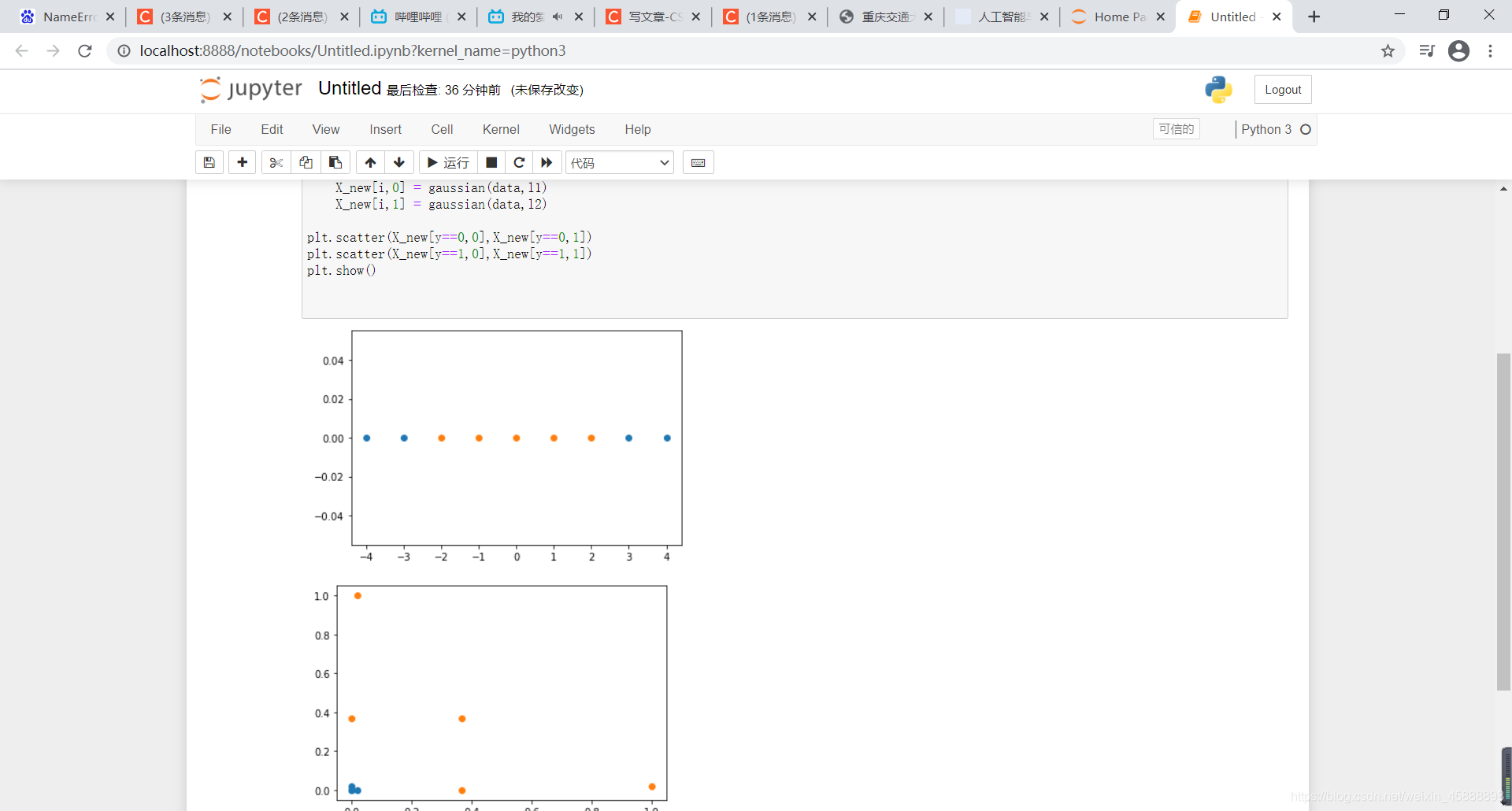
def gaussian(x,l):
gamma = 1.0
return np.exp(-gamma*(x-l)**2)
l1,l2 = -1,1
X_new = np.empty((len(x),2)) #len(x) ,2
for i,data in enumerate(x):
X_new[i,0] = gaussian(data,l1)
X_new[i,1] = gaussian(data,l2)
plt.scatter(X_new[y==0,0],X_new[y==0,1])
plt.scatter(X_new[y==1,0],X_new[y==1,1])
plt.show()
得到结果如下
超参数\gamma γ
在上面代码后面添加如下代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
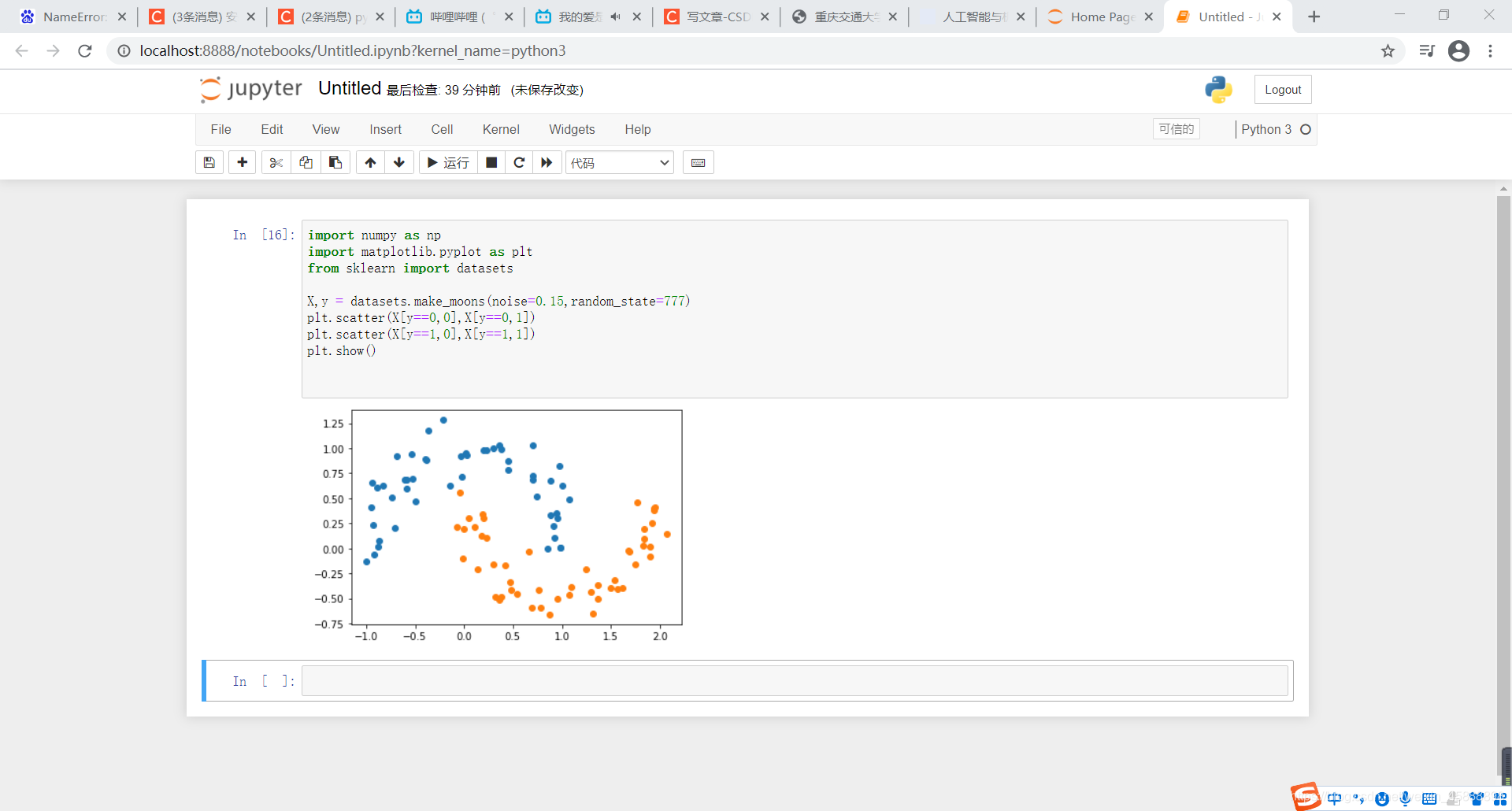
X,y = datasets.make_moons(noise=0.15,random_state=777)
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
得到结果如下
在上面代码后面添加如下代码
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
def RBFKernelSVC(gamma=1.0):
return Pipeline([ ('std_scaler',StandardScaler()),
('svc',SVC(kernel='rbf',gamma=gamma))
])
svc = RBFKernelSVC()
svc.fit(X,y)
plot_decision_boundary(svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
得到结果如下