文章目录
环境说明
Anaconda+python3.6+Jupyter Notebook
Anaconda创建虚拟环境及安装对应的包
创建虚拟环境
1.命令行创建
打开命令行
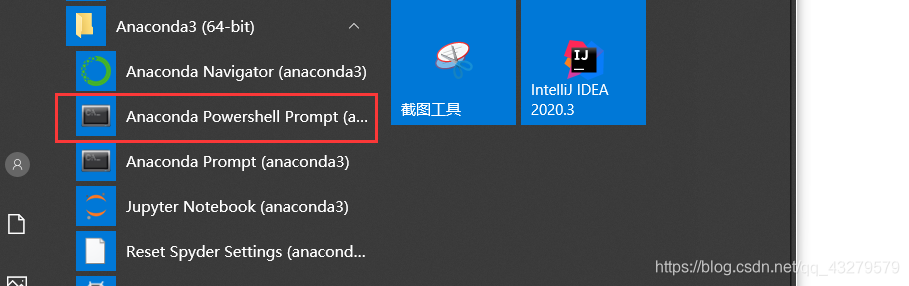
输入下面命令
conda create -n sklearn python=3.6
tf1是自己为创建虚拟环境取的名字,后面python的版本可以根据自己需求进行选择。
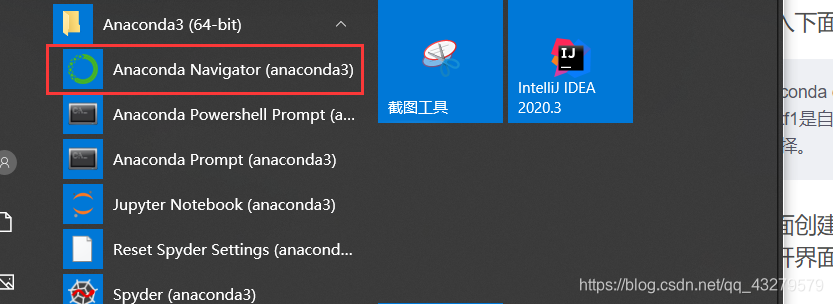
2.界面创建
打开界面
创建环境
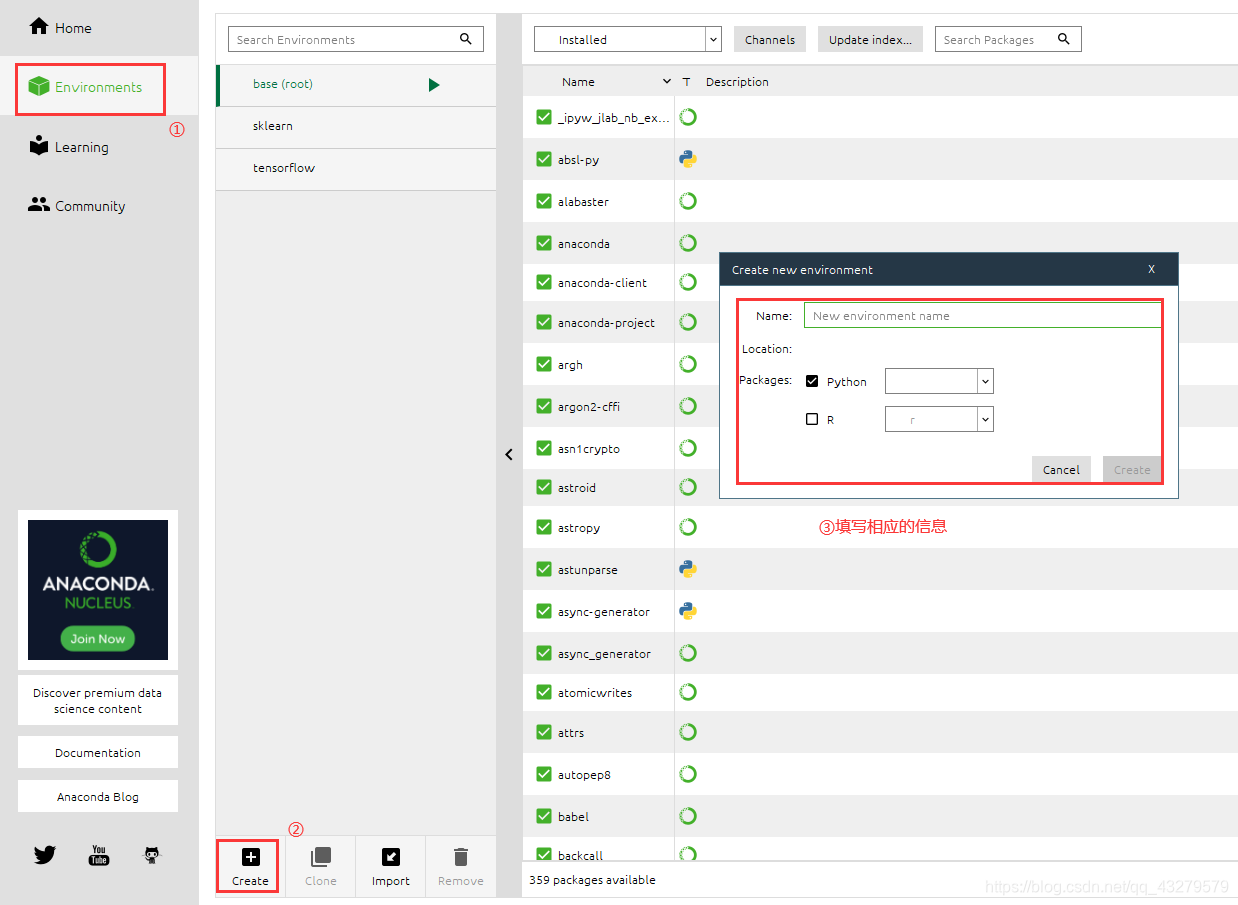
安装包
pip install 包名
直接这样安装可以由于网络的原因,安装失败或者安装很慢
解决方式:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名
此处安装的包包括numpy、pandas、sklearn、matplotlib
SVM(支持向量机)
SVM的介绍
Svm(support Vector Mac)又称为支持向量机,是一种二分类的模型。支持向量机可以分为线性和非线性两大类。其主要思想是找到空间中的一个更够将所有数据样本划开的直线(平面或者超平面),并且使得数据集中所有数据到这个超平面的距离最短。
鸢尾花数据集使用SVM线性分类
LinearSVC(Linear Support Vector Classification)线性支持向量机,核函数是 linear
相关参数说明:
- C:目标函数的惩罚系数C,默认C = 1.0;
- loss:指定损失函数. squared_hinge(默认), squared_hinge
- penalty : 惩罚方式,str类型,l1, l2
- dual :选择算法来解决对偶或原始优化问题。当nsamples>nfeatures时dual=false
- tol :svm结束标准的精度, 默认是 1e - 3
- multi_class:如果y输出类别包含多类,用来确定多类策略, ovr表示一对多,“crammer_singer”优化所有类别的一个共同的目标 。如果选择“crammer_singer”,损失、惩罚和优化将会被被忽略。
- max_iter : 要运行的最大迭代次数。int,默认1000
LinearSVC(C)方式实现分类
导入需要使用的包
#导入相应的包
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
获取数据
# 获取所需数据集
iris=datasets.load_iris()
#每行的数据,一共四列,每一列映射为feature_names中对应的值
X=iris.data
#每行数据对应的分类结果值(也就是每行数据的label值),取值为[0,1,2]
Y=iris.target
#通过Y=iris.target.size,可以得到一共150行数据,三个类别个50条数据,并且数据是按照0,1,2的顺序放的
对数据进行处理
#只取y<2的类别,也就是0 1并且只取前两个特征
X=X[:,:2]
#获取0 1类别的数据
Y1=Y[Y<2]
y1=len(Y1)
#获取0类别的数据
Y2=Y[Y<1]
y2=len(Y2)
X=X[:y1,:2]
未经标准化的原始数据点的绘制
#绘制出类别0和类别1
plt.scatter(X[0:y2,0],X[0:y2,1],color='red')
plt.scatter(X[y2+1:y1,0],X[y2+1:y1,1],color='blue')
plt.show()

数据归一化处理
#标准化
standardScaler=StandardScaler()
standardScaler.fit(X)
#计算训练数据的均值和方差
X_standard=standardScaler.transform(X)
#用scaler中的均值和方差来转换X,使X标准化
svc=LinearSVC(C=1e9)
svc.fit(X_standard,Y1)
画出决策边界
相关函数的说明:
- meshgrid() 返回了有两个向量定义的方形空间中的所有点的集合。x0是x值,x1是y的值
- ravel() 将向量拉成一行
- c_[] 将向量排列在一起
- contourf() 等高线
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1),# 600个,影响列数
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1),# 600个,影响行数
)
# x0 和 x1 被拉成一列,然后拼接成360000行2列的矩阵,表示所有点
X_new = np.c_[x0.ravel(), x1.ravel()] # 变成 600 * 600行, 2列的矩阵
y_predict = model.predict(X_new) # 二维点集才可以用来预测
zz = y_predict.reshape(x0.shape) # (600, 600)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
#print(X_new)
plot_decision_boundary(svc, axis=[-3, 3, -3, 3])
plt.scatter(X_standard[0:y2,0], X_standard[0:y2,1],color='red')
plt.scatter(X_standard[y2:y1,0], X_standard[y2:y1,1],color='blue')
plt.show()

例化一个svc2(主要是LinearSVC(C)中C的修改)
svc2=LinearSVC(C=0.01)
svc2.fit(X_standard,Y1)
print(svc2.coef_)
print(svc2.intercept_)
plot_decision_boundary(svc2, axis=[-3, 3, -3, 3])
plt.scatter(X_standard[0:y2,0], X_standard[0:y2,1],color='red')
plt.scatter(X_standard[y2:y1,0], X_standard[y2:y1,1],color='blue')
plt.show()

通过两个绘制得到的图表可以很明显的看到决策边界的不同,表面C C 越小容错空间越大。
分类后的内容基础上添加上下边界
def plot_svc_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1),# 600个,影响列数
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1),# 600个,影响行数
)
# x0 和 x1 被拉成一列,然后拼接成360000行2列的矩阵,表示所有点
X_new = np.c_[x0.ravel(), x1.ravel()] # 变成 600 * 600行, 2列的矩阵
y_predict = model.predict(X_new) # 二维点集才可以用来预测
zz = y_predict.reshape(x0.shape) # (600, 600)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
w = model.coef_[0]
b = model.intercept_[0]
index_x = np.linspace(axis[0], axis[1], 100)
# f(x,y) = w[0]x1 + w[1]x2 + b
# 1 = w[0]x1 + w[1]x2 + b 上边界
# -1 = w[0]x1 + w[1]x2 + b 下边界
y_up = (1-w[0]*index_x - b) / w[1]
y_down = (-1-w[0]*index_x - b) / w[1]
x_index_up = index_x[(y_up<=axis[3]) & (y_up>=axis[2])]
x_index_down = index_x[(y_down<=axis[3]) & (y_down>=axis[2])]
y_up = y_up[(y_up<=axis[3]) & (y_up>=axis[2])]
y_down = y_down[(y_down<=axis[3]) & (y_down>=axis[2])]
plt.plot(x_index_up, y_up, color="black")
plt.plot(x_index_down, y_down, color="black")
plot_svc_decision_boundary(svc, axis=[-3, 3, -3, 3])
plt.scatter(X_standard[0:y2,0], X_standard[0:y2,1],color='red')
plt.scatter(X_standard[y2:y1,0], X_standard[y2:y1,1],color='blue')
plt.show()

修改C的值
plot_svc_decision_boundary(svc2, axis=[-3, 3, -3, 3])
plt.scatter(X_standard[0:y2,0], X_standard[0:y2,1],color='red')
plt.scatter(X_standard[y2:y1,0], X_standard[y2:y1,1],color='blue')
plt.show()

结论:
常数C越大,容错空间越小,上下边界较近;常数C越小,容错空间越大,上下边界越远。