鸢尾花数据集介绍以及随机森林算法
https://blog.csdn.net/weixin_42567027/article/details/107488666
GBDT/XGboost/Adaboost原理解析
https://blog.csdn.net/weixin_42567027/article/details/107551175
集成学习
构建多个分类器(弱分类器)对数据集进行预测,然后用某种策略将多个分类器预测的结果集成起来,作为最终预测结果。算法要求每个弱分类器具备一定的“准确性”,分类器之间具备“差异性”。
XGBoost属于Boosting 集成算法。
集成学习分类
根据各个弱分类器之间是否存在有依赖关系,分为Boosting和Bagging两类。
Boosting:各分类器之间有依赖关系,必须串行,比如Adaboost、GBDT(Gradient Boosting Decision Tree)、Xgboost
Bagging:各分类器之间没有依赖关系,可各自并行,比如随机森林(Random Forest)
Boosting和Bagging代码对比
随机森林
基于softmax分类器的XGBoost
基于决策树分类器的AdaBoost
// An highlighted block
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import train_test_split # cross_validation
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
#去忽略warnings警告
import warnings
warnings.filterwarnings("ignore")
'''基于softmax分类器的XGBoost'''
#鸢尾花数据
if __name__ == "__main__":
'''加载数据'''
path = u'F:\pythonlianxi\shuju\\iris.data' # 数据文件路径
data = pd.read_csv(path, header=None)
print(data)
#样本数据和标签数据
x, y = data[range(4)], data[4]
#由字符串改为编码
y = pd.Categorical(y).codes
#训练集,测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1, test_size=50)
data_train = xgb.DMatrix(x_train, label=y_train)
data_test = xgb.DMatrix(x_test, label=y_test)
watch_list = [(data_test, 'eval'), (data_train, 'train')]
#深度为3,objective': 'multi:softmax':使用softmax;'num_class': 3:使用三分类
param = {
'max_depth': 3, 'eta': 0.3, 'silent': 1, 'objective': 'multi:softmax', 'num_class': 3}
'''训练模型'''
#建立六棵树,每建立一次,更新一次模型
bst = xgb.train(param, data_train, num_boost_round=6, evals=watch_list)
'''测试模型'''
#测试集上计算
y_hat = bst.predict(data_test)
#手动计算正确率
result = y_test.reshape(1, -1) == y_hat
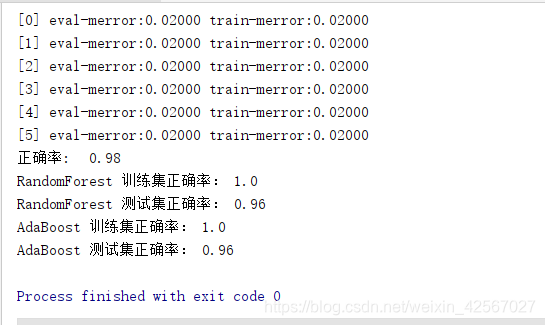
print ('正确率:\t', float(np.sum(result)) / len(y_hat))
'''AdaBoost+随机森林'''
models=[
#n_estimators:树的数目 criterion='entropy'使用“ID3”方式划分节点数据集
('RandomForest',RandomForestClassifier(n_estimators=200,criterion='entropy')),
#n_estimators:树的数目 min_samples_split:内部节点再划分所需最小样本数,可选参数,默认是2.
#algorithm="SAMME":用于多分类 learning_rate=0.5:学习率
('AdaBoost',AdaBoostClassifier(DecisionTreeClassifier(
max_depth=3, min_samples_split=2),algorithm="SAMME",n_estimators=30,learning_rate=0.8))]
for name,model in models:
model.fit(x_train,y_train)
print(name,'训练集正确率:',accuracy_score(y_train,model.predict(x_train)))
print(name, '测试集正确率:', accuracy_score(y_test, model.predict(x_test)))
实验分析
随机森林:正确率为0.96
Adaboost:正确率为0.96
XGBoost:正确率为0.98
XGBoost的速度和性能优于Sklearn.ensemble.GradientBoostingClassifier类