1.softmax回归实现鸢尾花数据集的分类
鸢尾花数据集
鸢尾花数据集包含3类、共150条记录(每类各50条记录)。每条记录都有4项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度。可以通过这4个特征预测鸢尾花卉属于iris-setosa, iris-versicolour, iris-virginica中的哪一品种。
获得鸢尾花数据集
可以通过python的第三方机器学习库sklearn得到;
任务
设计一个softmax回归模型,通过鸢尾花数据集训练该模型,并将训练过程的训练误差可视化。训练集、测试集可按一定比例划分。计算测试集的预测准确率。
代码:
1.导入鸢尾花数据集和第三方库
from sklearn.datasets import load_iris
import numpy as np
import matplotlib.pyplot as plt
iris = load_iris()
X = iris.data
y = iris.target
2.划分训练集和测试集
np.random.seed(42)
indices = np.random.permutation(len(X))
train_ind, test_ind = indices[:int(0.8*len(X))], indices[int(0.8*len(X)):]
X_train, X_test = X[train_ind], X[test_ind]
y_train, y_test = y[train_ind], y[test_ind]
3.对特征进行归一化处理
mean = np.mean(X_train, axis=0)
std = np.std(X_train, axis=0)
X_train = (X_train - mean) / std
X_test = (X_test - mean) / std
4. 定义softmax函数
def softmax(z):
exp_z = np.exp(z)
return exp_z / np.sum(exp_z, axis=1, keepdims=True)
# 定义softmax回归器
class SoftmaxRegressor(object):
def __init__(self, num_classes, input_dim):
# 初始化权重和偏置
self.W = np.random.randn(input_dim, num_classes) * 0.01
self.b = np.zeros((1, num_classes))
def forward(self, X):
# 前向传播计算预测值
return softmax(np.dot(X, self.W) + self.b)
def compute_loss(self, y_pred, y_true):
# 计算损失值
num_samples = y_true.shape[0]
loss = -np.log(y_pred[range(num_samples), y_true])
data_loss = np.sum(loss)
return 1./num_samples * data_loss
def predict(self, X):
# 预测标签
y_pred = self.forward(X)
return np.argmax(y_pred, axis=1)
def train(self, X, y, learning_rate, num_epochs, verbose=True):
# 训练模型
for i in range(num_epochs):
# 正向传播计算损失
y_pred = self.forward(X)
loss = self.compute_loss(y_pred, y)
# 反向传播计算梯度
num_samples = y.shape[0]
d_y_pred = y_pred
d_y_pred[range(num_samples), y] -= 1
d_y_pred /= num_samples
dW = np.dot(X.T, d_y_pred)
db = np.sum(d_y_pred, axis=0, keepdims=True)
# 更新参数
self.W -= learning_rate * dW
self.b -= learning_rate * db
# 打印损失
if verbose and i % 1000 == 0:
print("Epoch %d: loss = %.4f" % (i, loss))
# 设置模型参数并训练模型
num_classes = 3
input_dim = X_train.shape[1]
softmax_regressor = SoftmaxRegressor(num_classes, input_dim)
learning_rate = 0.1
num_epochs = 5000

softmax_regressor.train(X_train, y_train, learning_rate, num_epochs)
# 在测试集上进行预测并计算测试准确率
y_pred_test = softmax_regressor.predict(X_test)
accuracy = np.mean(y_pred_test == y_test)
print("Test Accuracy: %.2f%%" % (accuracy * 100))

# 绘制训练过程中损失值的变化曲线
# 定义训练迭代的次数
num_epochs = 5000
# 定义学习率
learning_rate = 0.1
# 初始化softmax回归器
softmax_regressor = SoftmaxRegressor(num_classes, input_dim)
# 定义损失值的数组
losses = []
# 迭代训练模型
for i in range(num_epochs):
# 前向传播计算预测值,并将损失值添加到数组中
y_pred = softmax_regressor.forward(X_train)
losses.append(softmax_regressor.compute_loss(y_pred, y_train))
# 反向传播计算梯度,更新参数
num_samples = y_train.shape[0]
d_y_pred = y_pred
d_y_pred[range(num_samples), y_train] -= 1
d_y_pred /= num_samples
dW = np.dot(X_train.T, d_y_pred)
db = np.sum(d_y_pred, axis=0, keepdims=True)
softmax_regressor.W -= learning_rate * dW
softmax_regressor.b -= learning_rate * db
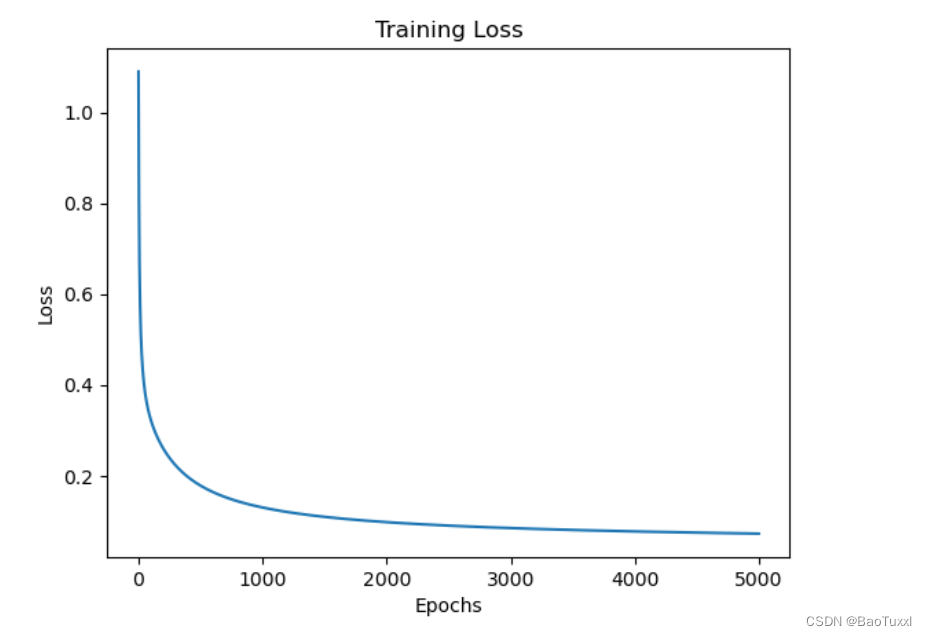
# 绘制训练过程中损失值的变化曲线
plt.plot(losses)
plt.title("Training Loss")
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.show()
问题:
- 出现了过拟合的现象,迭代次数过多导致在训练集上出现了过拟合的现象,导致在数据集的泛化能力较差
- 学习率需要不断调整,如果学习率过大可能会导致模型无法收敛或在最小值附近震荡,如果学习率过小可能会导致模型收敛速度过慢。
- 数据集分布不均:如果训练集中的样本分布与测试集中的样本分布不同,可能会导致模型在测试集上表现较差,因为模型没有学习到所有的数据分布情况。