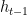资料
1.快速了解视频(bilibili莫凡视频)
https://www.bilibili.com/video/av15998703?from=search&seid=4200091979965196821
2. 详细介绍:
http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/
源起
没有十全十美的神经网络,每一个都有对应的特色。So,产生了各种各样的 Neural Network,来处理对应的各种各样的问题。从最基础的basic neural network(全链接),不考虑空间结构,且假设所有元素点或数据点独立,只是按照一定层次的结构组合成网络结构,就能实现常人感到不可思议的事情,如人工智能的Hello World——手写字识别。再看CNN,当人们开始思考,全链接神经网络虽然好,但却忽略了空间结构这一重要概念,全连接构造时,仅仅将所有像素点排成一列,而忽略了其他,这怎么可以,所以,CNN来了。思考并未停止,等到某一天,人们不在基于图片,开始围绕时间二字,开始冲击数据点独立二字,RNN的是时代来临了。
什么是RRN
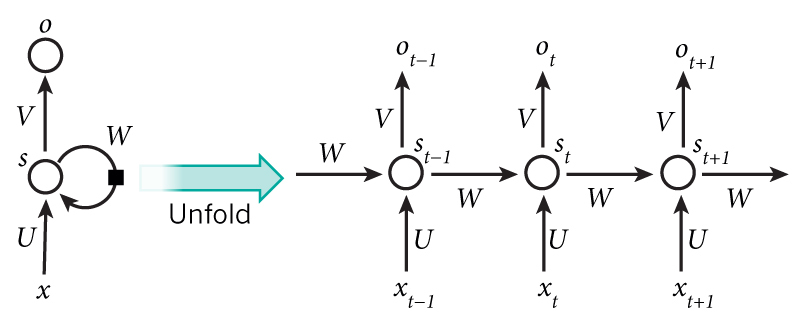
正如每种Neural Network都有一种结构,RNN的结构是这个样子。仅仅这个结构就有很多信息。此文为记录文(仅仅记录自己的所得和重要的东西),所以(http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/)
Note:
1.As briefly mentioned above, it’s a bit more complicated in practice because 
2.Unlike a traditional deep neural network, which uses different parameters at each layer, a RNN shares the same parameters (
没有尝试去翻译两句话,因为英文描述的很清楚里。RNN框架的特性,权重相同,不能记忆太多代。
RNN能干什么
1.语言建模与生成文本
在语言建模中,我们的输入通常是一系列单词(例如编码为单热矢量),我们的输出是预测单词的序列。在训练我们设置的网络时,

2.机器翻译
机器翻译类似于语言建模,因为我们的输入是源语言中的一系列单词(例如德语)。我们希望以目标语言输出一系列单词(例如英语)。一个关键的区别是我们的输出仅在我们看到完整输入后才开始,因为我们翻译的句子的第一个单词可能需要从完整的输入序列中捕获的信息。
3.语音识别
给定来自声波的声学信号的输入序列,我们可以预测一系列语音片段及其概率。
4.生成图像描述
与卷积神经网络一起,RNN已被用作模型的一部分,以生成未标记图像的描述。令人惊讶的是,这看起来有多好。组合模型甚至将生成的单词与图像中找到的特征对齐。
5.Training RNNs
in order to calculate the gradient at 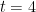
6.RNN扩展
双向RNN基于以下思想:时间上的输出
深度(双向)RNN类似于双向RNN,只是我们现在每个时间步长有多个层。在实践中,这为我们提供了更高的学习能力(但我们还需要大量的培训数据)。
LSTM网络 现在非常流行,我们在上面简要讨论了它们。LSTM与RNN没有根本不同的架构,但它们使用不同的函数来计算隐藏状态。LSTM中的内存称为单元格,您可以将它们视为黑框,将以前的状态