版权声明:原创文章未经博主允许不得转载O(-_-)O!!! https://blog.csdn.net/u013894072/article/details/84502501
RNN简介
RNN(循环神经网络)是深度神经网络中,应用最广泛的两种神经网络架构之一。并且,作为一种时序结构的神经网络,RNN经常用于时序相关的问题中,且在NLP中应用广泛。还有一种RNN称为递归神经网络,虽然名字类似,但是却是不一样的架构。
RNN图示
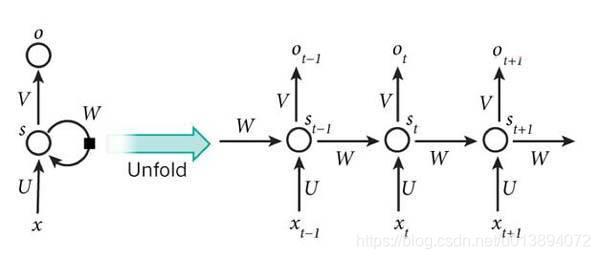
xt是输入层数据,
st是隐含层数据,
ot是输出层数据,我们令:每一个
yt是t时刻对应的真实输出,
ythat是对
ot进行softmax计算之后得到的估计值。
U是输入层到隐含层的权重,
W是上一时刻隐含层到当前时刻隐含层的权重,
V是隐含层到输出层的权重。
正向传播
由上图易知:
at=b+W∗st−1+U∗xt
st=tanh(at)
ot=c+U∗st
ythat=softmax(ot)
我们假设t时候的损失函数为
Lt(一般为交叉熵损失/负对数似然),则一次正向传播的损失
L=∑tLt
反向传播
反向传播中,还是使用链式推导方法,与传统的神经网络推导类似。但不一样的地方在于隐含层受到了前一时刻隐含层的影响,故
t时刻隐含层
st的误差传播源来自于
ot与
st+1两个方向。这里推导我是参考了很多博客文章,但是一直都没理解。后来看了文献1,多少有点明白的意思。有幸各位大牛们看了这篇文章,请指点。
我们首先看误差对
ot的影响
∇otL=∂ot∂L=∂ot∂Lt=yt∗ythat−Ii=j∗yt其中i是当前数据所属真实类别索引,j为所有类别的索引分量。当i=j时,
Ii=j是1,否则是0,参考了文献2。
假设总时刻长度为
t=τ,
∇stL=VT∗∇otL,t=τ
∇stL=(∂stL∂st+1L)∗∇st+1L+(∂stL∂otL)∗∇otL,t<τ
也就是说最后一个节点的隐含层误差只来源于他的输出层。其余各层除了本身输出层外,还会有上一层的误差来源。通过链式求导有
∇stL=WT∗st+1L∗diag(1−st+12)+VT∗∇otL,t<τ,diag是对角线矩阵
故各种变量的梯度值为所有时刻梯度值的和:
∇cL=t∑∇otL
∇bL=t∑diag(1−st2)∇otL
∇VL=t∑∇otL∗stT
∇WL=t∑diag(1−st2)∗∇stL∗st−1T
∇UL=t∑diag(1−st2)∗∇stL∗xtT
参考文献
1.深度学习(AI圣经) P327
2.softmax函数及其导数
3.RNN求解过程推导与实现