https://www.youtube.com/watch?v=rTqmWlnwz_0
RNN(循环神经网络):存储隐藏层在上一层训练时的输出用于这一次的训练,因此训练的顺序就显得很重要。
看一个例子:
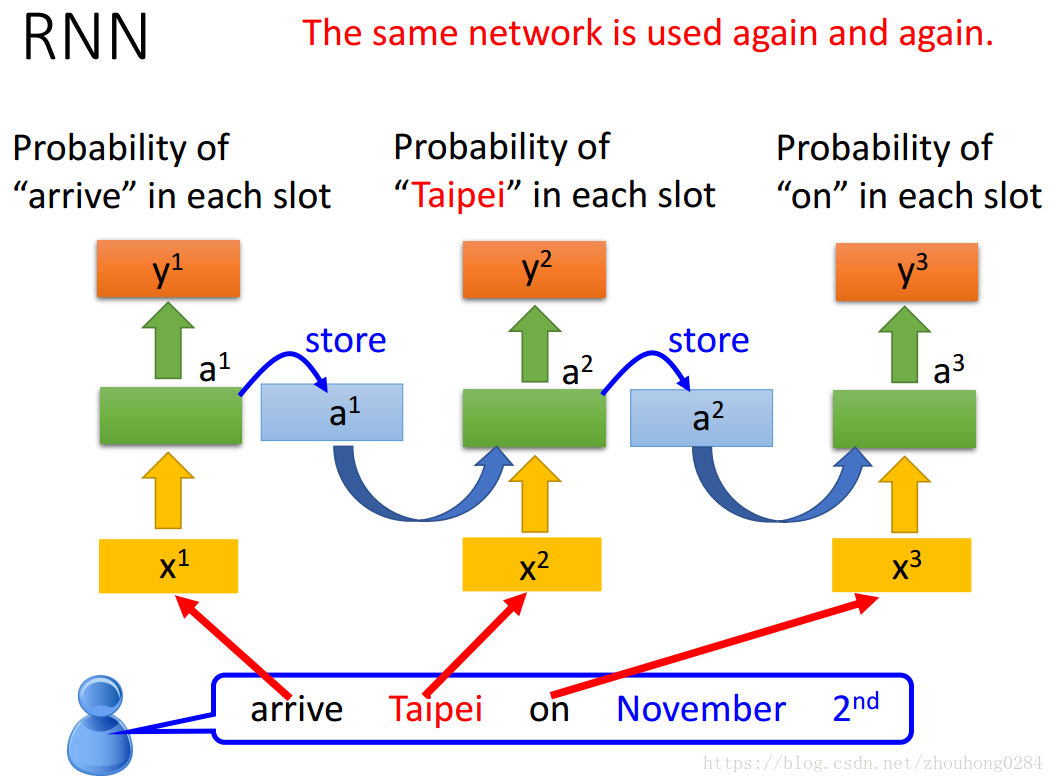
在进行语义分析的时候,这一点显得很有效。
RNN也有多种形式:
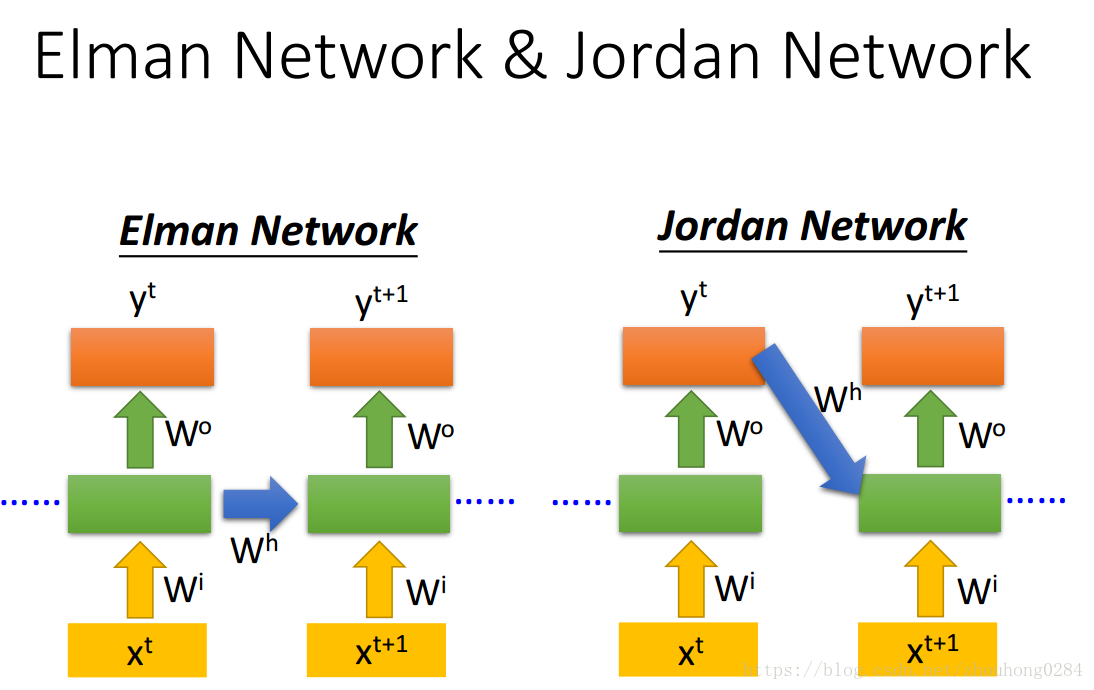
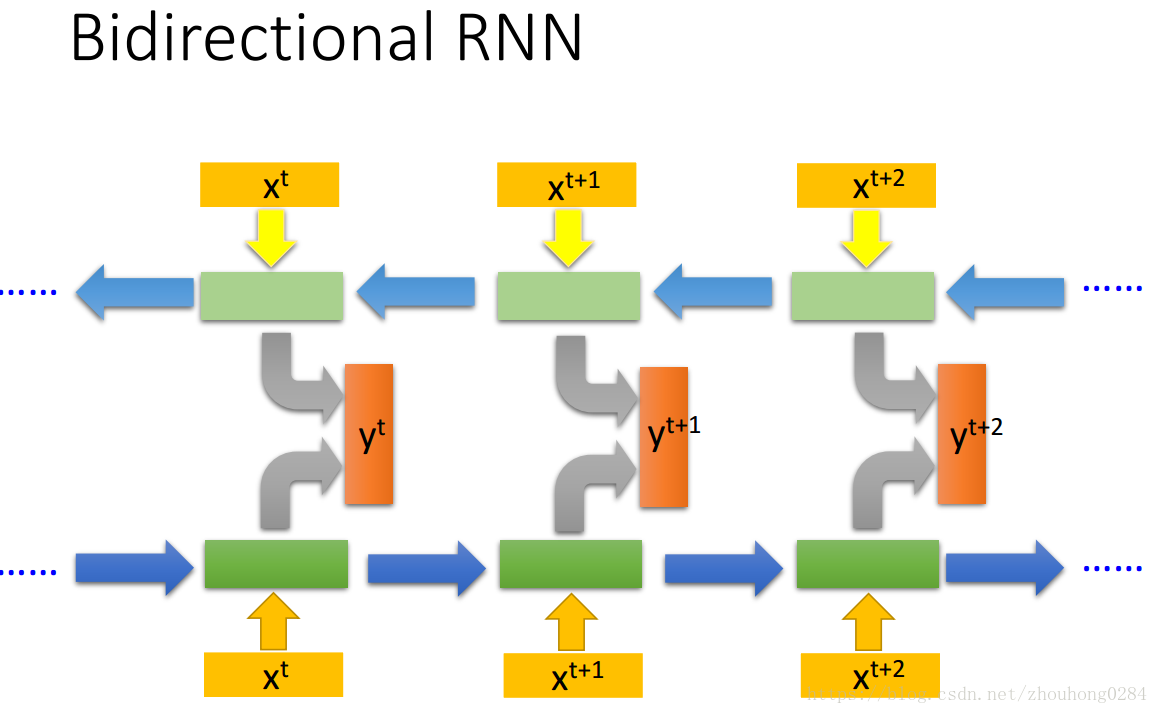
目前常说的RNN就是指的LSTM(Long short-term memory),GRU是少了一个gate,simpleRNN指的是最开始讲的简单的RNN。
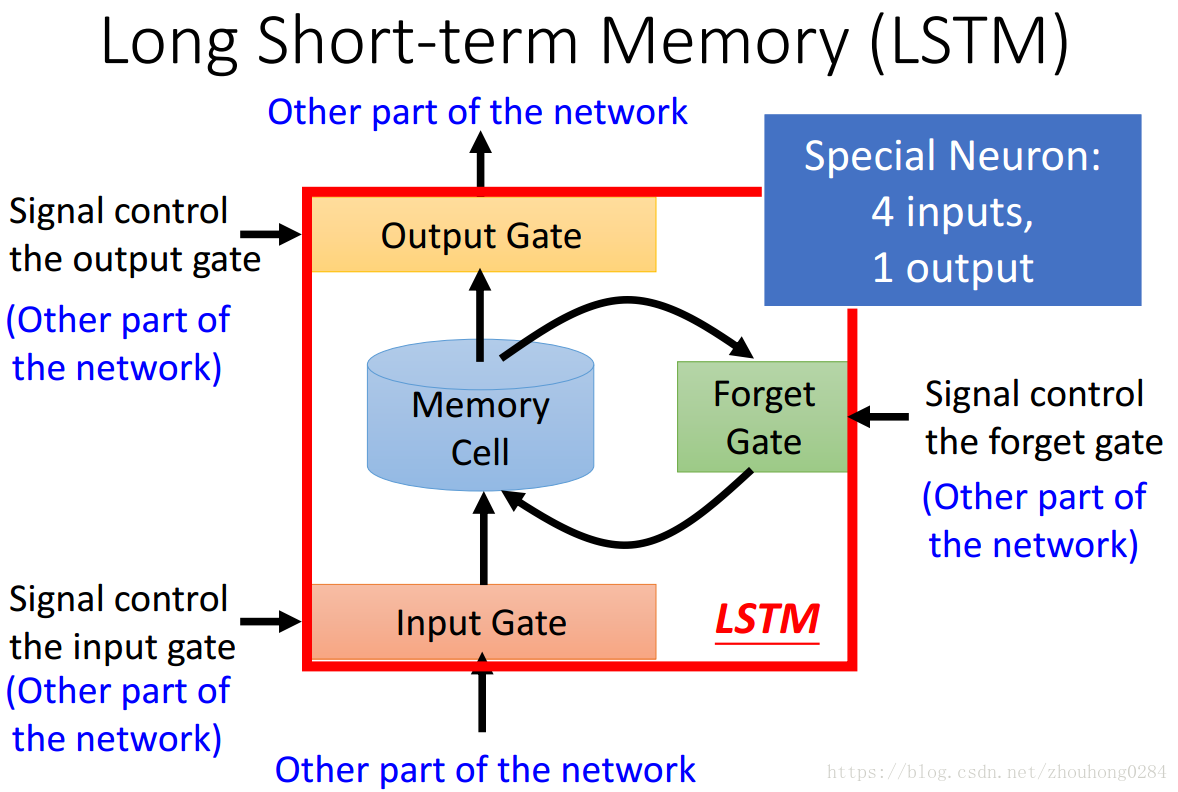
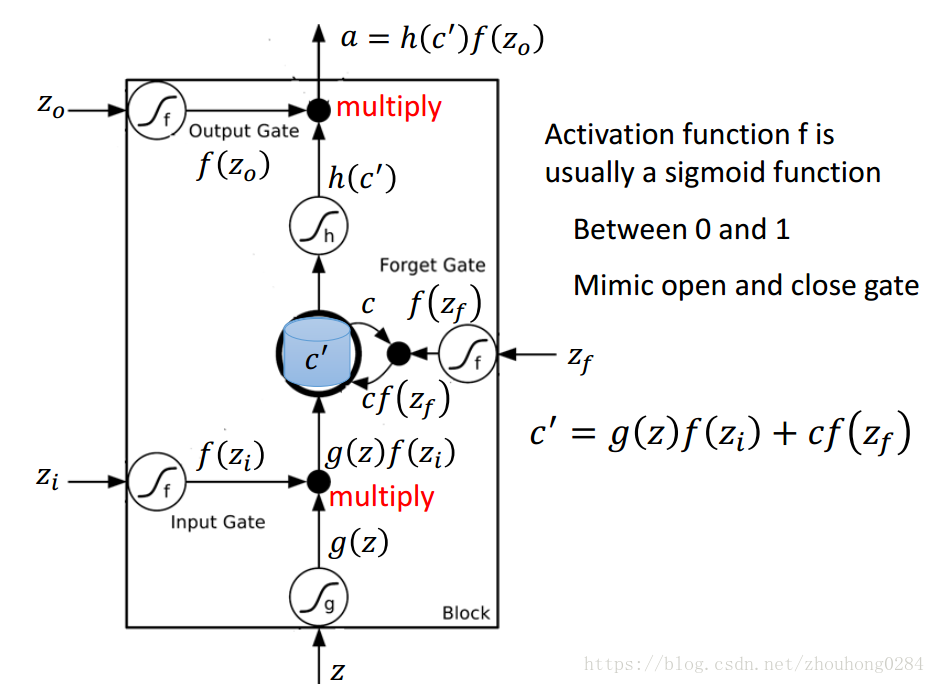
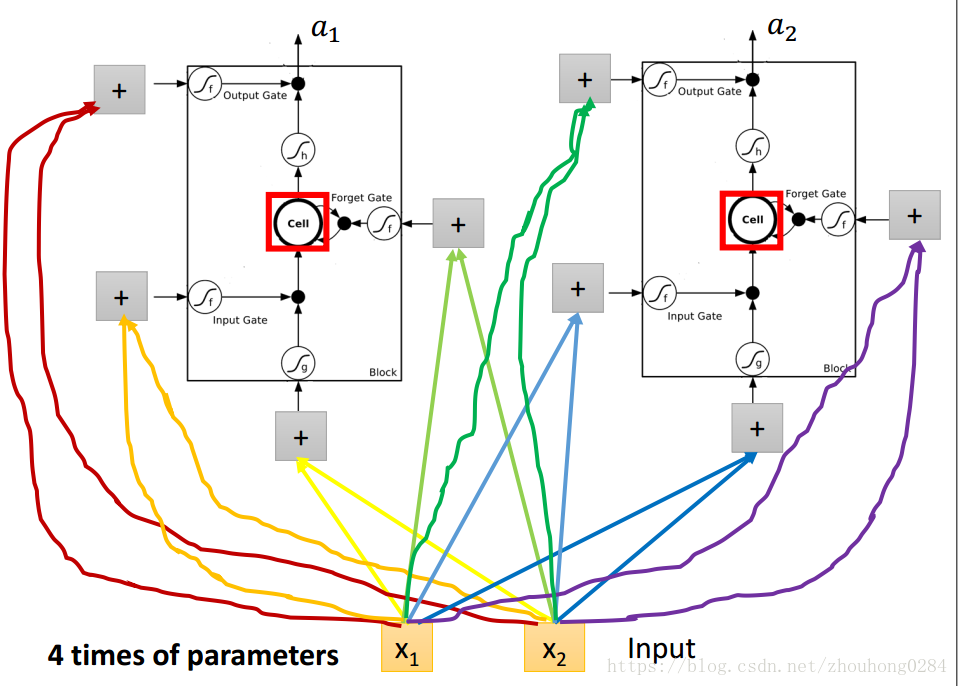
LSTM是如何存在于神经网络中的呢?实际上就是使用每一个LSTM单元替换原来的隐藏单元,此时对于每一个隐藏单元有4个输入,每个输入都是由上一层的输出线性组合得来的。因此在训练时的参数量也是很大的。
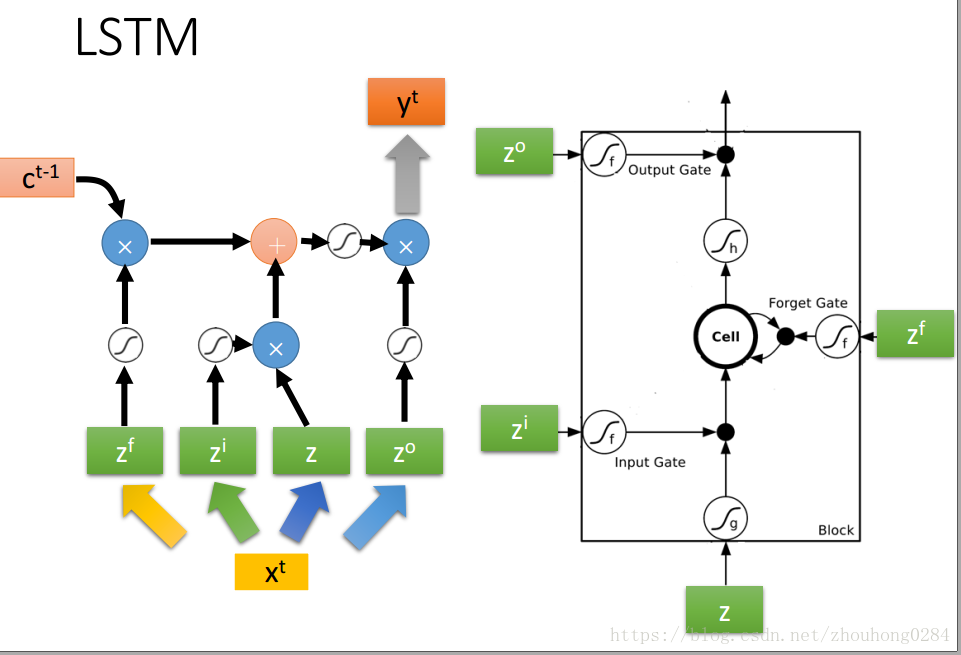
有时候,会将输出+memory当前值+下一次的输入一起作为输入进入下一次训练,那么:
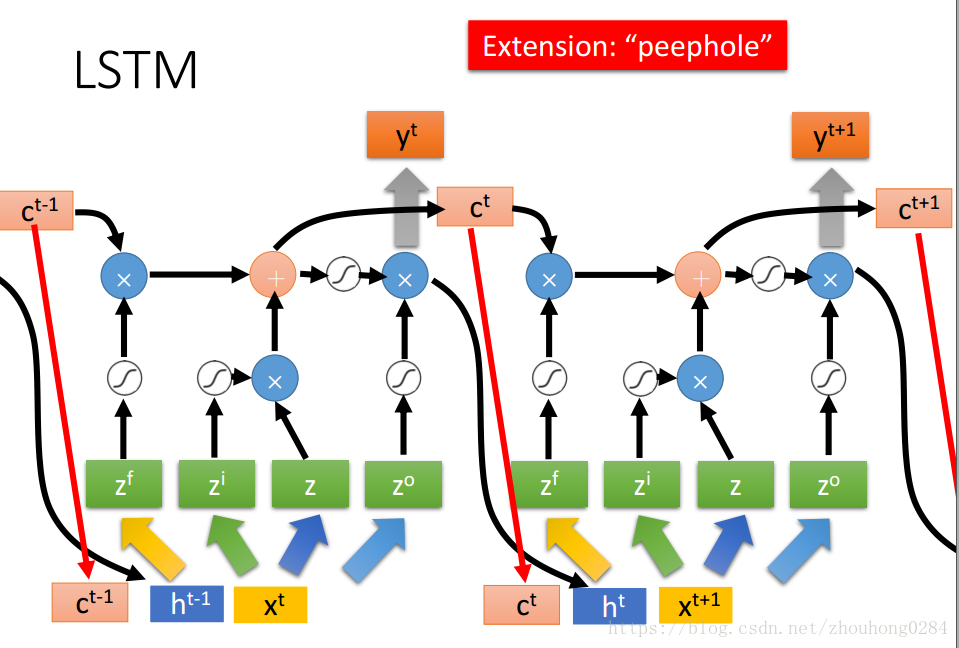
在这种情况下,RNN的训练变得十分复杂,在训练时,可能会出现损失函数时大时小的情况,这是因为RNN下的损失函数的曲线要不十分平坦,要不非常陡峭,在进行梯度训练时一不小心梯度就可能上一个陡峰,因此需要进行clipping在梯度到达一定值的时候及时停止对梯度的训练。那为什么梯度的会时大时小呢?这是因为RNN的结构是被循环利用的,因此传播参数也经常是被循环利用多次的,当一个参数w>1时容易发生梯度爆炸,w<1时容易出现梯度消失,因此梯度要么很大要么很小。
有效的方法:LSTM可以解决梯度消失,却不能解决梯度爆炸的问题。Why?
传统的RNN每一次memory会被覆盖掉,而LSTM是在原来的基础上加上输入,因此就算是小的影响也不会被去除。
GRU是将LSTM中的input gate 和 forget gate互异,因此只需要两个门进行训练,总体来说训练模型会简单的多。
激活函数:一般情况下使用sigmoid效果会好,但是在参数使用identity matrix的时候,使用Relu会好一些。
应用:
1.输入为一个矢量,输出为一个标量
实例:语义分析
比如输入为:好看的电影; 输出为:正类
2.输入为一个矢量,输出为一个比输入短的矢量
比如语音识别
输入的语音在很短的时间内转换为一个输入元素,有可能几个输入元素指的是同一个意思,这时候采用CTC网络去重,且加入一个Null的输出表示两个词语之间的空白。
3.输入与输出不确定长短
实例:翻译
翻译时并不知道哪种语言会比较长,因此在输出时是将上一次的输出作为下一次的输入来不断训练,再加入一个字符“断”表示停止。