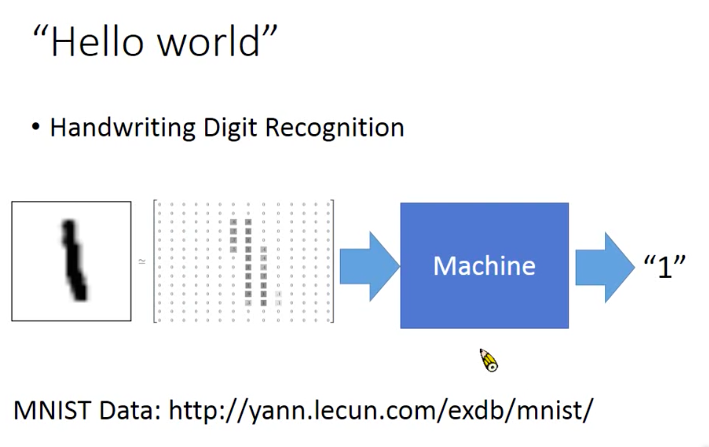
1. 深度学习基本结构
以手写数字识别为例
2. batch
sgd v.s. mini-batch
sgd(随机梯度下降)的训练方法是每次喂给模型单个的sample,而mini-batch的方法是每次给模型喂若干个sample(取决于batch size)。相同总量的sample,往往
mini-batch的方法训练消耗的时间要明显少于sgd,这是因为mini-batch的方法中,对于每一个batch的sample,可以利用gpu进行并行训练。
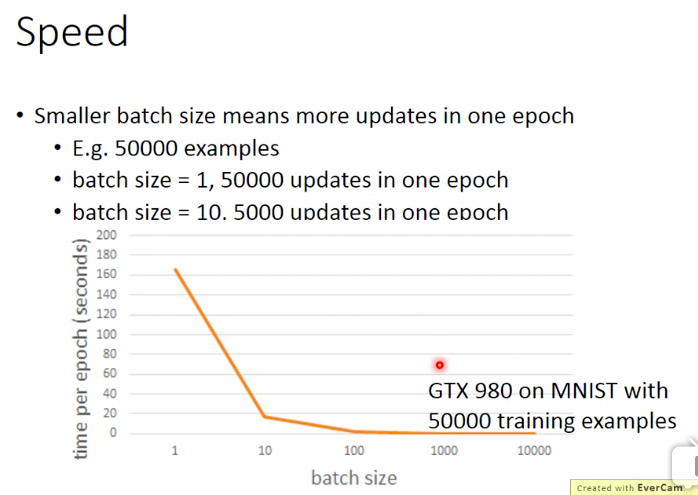
batch size的选取问题
batch size如果取全部数据集,即为Full Batch Learning,此方法的好处是每次迭代的方向大概率是极值点所在的方向,坏处是当数据集很大的时候每次需要加载全部的数据,往往会导致内存溢出(即使使用gpu也可能无法完全规避)。batch size如果取1,则为sgd,好处是内存占用很小,坏处是每次参数更新迭代的方向比较随机,经常不是朝着极值点方向更新,容易陷入local minimum。
增大batch size的好处:1)更好的利用gpu进行并行计算;2)每一个epoch所需要的迭代次数减少,所以跑完一个epoch 的时间减少。
增大batch size的坏处: 1 )内存压力增大 ;2)越大的batch size在每次更新的时候下降方向已经基本保持不变,导致要想达到相同的效果,所需要的epoch数量增加。
所以增大batch size有利有弊,可能存在一个比较合理的batch size。
参考知乎上一位程引大神基于mnist做的实验(https://www.zhihu.com/question/32673260)

3. dnn的训练、评价
注意,别看到模型在测试集上表现不好就说是过拟合了。

对于传统的机器学习方法,在训练集上是可以得到100%的正确率的(比如决策树,只要树够深,一定可以做到100%准取人的),所以对于
传统机器学习方法来说在traning set上的效果并不是一个issue。而对于深度学习来说,情况并不是这样,模型在训练集上的表现变得更重要。
1)深度学习在训练集上更难训练
更深的模型即便在训练集上也可能效果更差

2 )如果效果不好,怎么应对?

更改激活函数。
过去发现,网络越深,效果可能越差(是在训练集上,所以不是过拟合),原因在于激活函数用的是sigmoid function,导致gradient vanish

那么梯度消失是怎么产生的?梯度消失为什么会导致效果变差呢?
如下图,结合反向传播的特点,接近output的几层layer的gradient较大,而接近input的几层layer的gradient较小,所以前面几层的参数
更新很慢,而后面几层的参数更新较快,所以在前面几层的参数还处在初始化数据附近时,后面几层的参数已经收敛了,而这时后面的layer
只是从前面的layer中学到了一些random的东西!所以最终的效果很差。
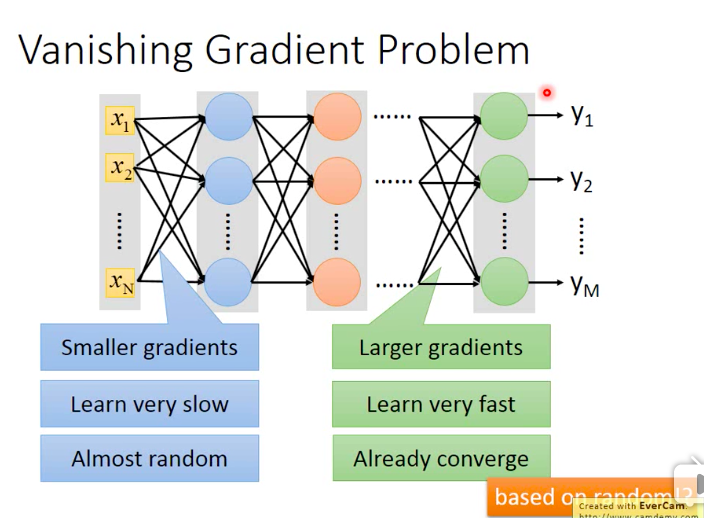
也是说是梯度消失导致了上述问题,解决办法有两个,一种是更换激活函数,通常将sigmoid func 换作relu,另外一种方法是将固定的learning
rate换成adaptive learning rate。前一种方法更直接暴力。
relu
relu函数形式如下。relu的优点主要在于 计算更快;生物学意义;解决gradient vanish问题

relu为什么可以解决gradient vanish问题呢?
由relu的函数形式,relu可以视为分段函数,在纵轴左侧,input < 0,则output为0,在纵轴右侧,input > 0,则output = input
如下图,有一些neuron的input < 0,经过relu后output为0,所以可以把这些neuron去掉,使得整个网络变得更瘦


你会发现整个network里面所有的neuron都是linear的,每个neuron的input和output都是相等的,这样梯度反向传播的时候就不会出现vanish
但是有一个问题,上图看起来就成了一个线性网络,而线性网络不是很弱吗?其实这个网络并不是真正的线性网络,当input变动很小时, neuron的upper region不变,而当input变化很大时,neuron的upper region就会变成另外一段,所以严格来说这个网络并不是一个线性网络。
neuron的变形

maxout
maxout的基本思想是自己学出activation function,基本架构如下

为什么说relu是maxout的特例?

当然了,maxout不只是relu一种形式,它可以包含很多不同的折线式分段函数形式

maxout只可以学习那种分段折线式的actication function,具体分成几段取决于每个group里包含几个element(自己设定)

变化的learning rate
最常见的是adagrad

以上总结了模型在训练集上的优化方法,下面介绍提高模型在测试集上表现上的三种方法:early stoping,regularization,dropout
early stoping

l2正则

l1正则

某种意义上,early stoping和regularization有相似之处,二者都是使得参数更接近0(初始值,一般情况下随机初始值在0附近)
第三种方法是dropout
每次迭代的时候都对neuron做subsampling(也可以对input做subsampling)

dropout可以视为一种ensemble的方法

注意,如果你用dropout训练,每一个neuron有p的概率被dropout掉,那么把模型用在测试数据上的时候需要把学到的参数乘以p
