训练策略:
无参模型:KNN
生成模型:naive bayes
判别模型:线性模型和SVM
KNN(k的选择和距离公式选择很重要):
将测试样本与训练集中的样本做距离运算,找到最近的k个样本,记录最多的标注结果。
实际的问题来了,如果把测试样本与所有训练集样本做距离运算,计算量太大了,能不能找到一种方法减少计算量?
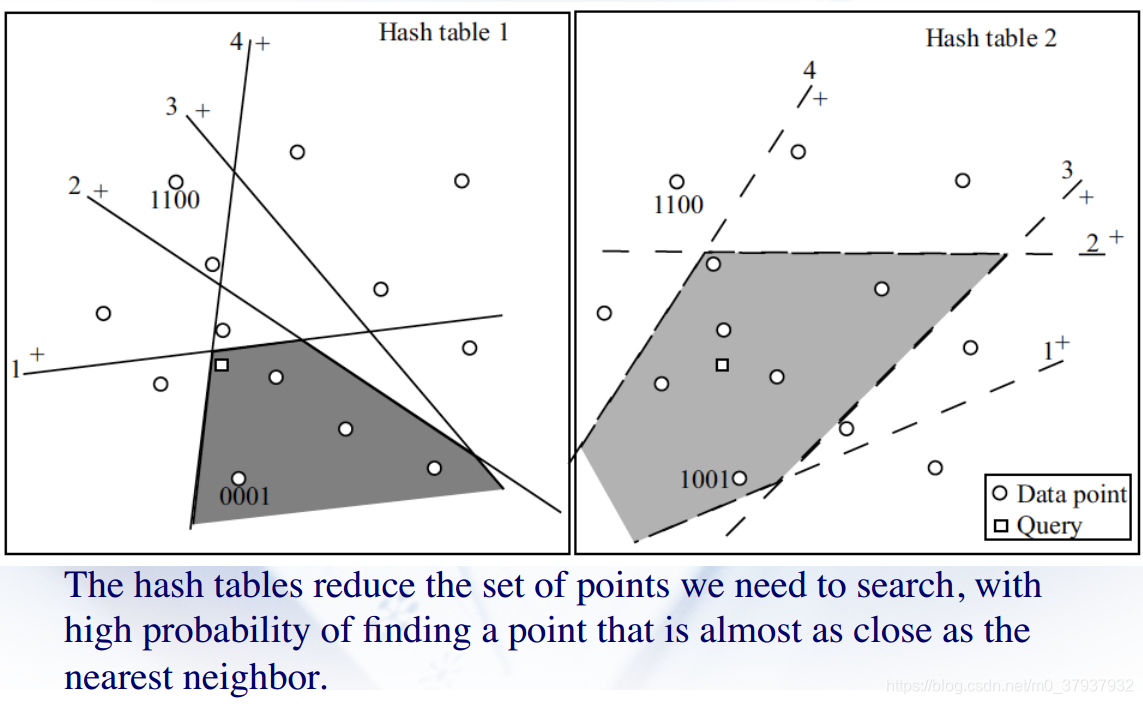
解决方案1:Locality Sensitive Hashing
通过构建hash table 可以使得原本距离很近的样本分在同一个bucket,这样在找k个相近的样本时,就只要考虑同一个bucket中的样本,无需测试所有样本。
随机选择多个投影向量,与数据向量做点积得到部分索引值,所有索引号相同的数据项在一个bucket中。由于所选的投影向量是随机的,可能实际相邻的样本hash之后不在同一个bucket中,没有关系,重新选择投影向量相邻数据项就有可能在同一个bucket中。
解决方案2:K-D 树
朴素贝叶斯:
p(y=1|x)=p(x|y=1)p(y=1)/p(x)
假设特征无关,根据训练集中相应特征出现的概率乘积来训练分类器。
linear 分类器、SVM思想找到一个判别平面来分离不同类型的数据。
多分类问题:
one vs one:训练集中每两个类生成一个分类器
one vs all :训练集中以一个类为正样本,其余所有样本作为负样本
分类器性能指标:
ROC和AOC