前言
一直对大名鼎鼎的Kaggle竞赛有所耳闻,加上之前选修了《机器学习》课程并看了一点Ensemble Learning,所以趁着假期比较闲便想去了解一下Kaggle与数据分析。而Titanic大概是Kaggle领域里的Hello World与MNIST,因此打算先从它开始。不过因为这个竞赛我个人觉得是有一定门槛的,尽管机器学习算法都可以使用sklearn实现,数据的处理也可以通过pandas进行,但是数据分析与特征工程的难度还是不小的,Titanic从头到尾比着教程看下来也用了一整天的时间。
由于只是为了去了解基本的竞赛步骤,最后几乎完全是使用了《Kaggle Titanic 生存预测 – 详细流程吐血梳理》这篇博客里的代码,所以有需要的同学可以去看这篇博客。本文只是简单地总结一点个人的心得体会。
Kaggle竞赛
Overview of How Kaggle’s Competitions Work
From:https://www.kaggle.com/c/titanic/overview
- Join the Competition
Read about the challenge description, accept the Competition Rules and gain access to the competition dataset.- Get to Work
Download the data, build models on it locally or on Kaggle Kernels (our no-setup, customizable Jupyter Notebooks environment with free GPUs) and generate a prediction file.- Make a Submission
Upload your prediction as a submission on Kaggle and receive an accuracy score.- Check the Leaderboard
See how your model ranks against other Kagglers on our leaderboard.- Improve Your Score
Check out the discussion forum to find lots of tutorials and insights from other competitors.
官网上其实说的挺清楚的,一般的步骤首先是选择一个比赛并阅读其Rule,里面可能涉及一些提交次数、组队限制的信息,然后下载数据并通过代码生成预测文件,提交预测文件系统会计算你的得分并且在Leaderboard上公布你的排名,最后我们可以进一步完善代码得到更好的预测刷新得分。不过一般来说,比赛过程中排名的验证只会用一半的测试用例,所以当前的排名其实不是你的最终排名,当比赛结束后会基于另外50%进行计算,得到最终排名。
简单的来说,步骤如下:
加入比赛→下载数据并通过代码获得预测→提交结果→查看排名→继续刷新得分
一般流程
这里基于上面提到的那篇博客,因为我的本次尝试也是基于它做的。
1. 数据总览
下载完数据后我们首先观察数据的基本组成,观察数据的基本结构,从而才能进行下面的步骤。
2. 缺失值处理
由于数据经常有残缺的属性,所以需要对缺失值进行处理。一般是通过pandas的info属性查看缺失值,通过合适的方法进行,比如删掉、均值、众数等等。
3. 分析数据关系
下面便可以开始分析数据之间的关系,能够粗略了解哪些特征会比较大程度的影响预测结果,这个过程还是挺麻烦的,需要大量的可视化操作,有利于数据特征的观察。
这样我们逐个分析与最终predict的属性的关系,在Titanic这个题目里是是否Survived,可以了解特征对于结果的影响。
划分
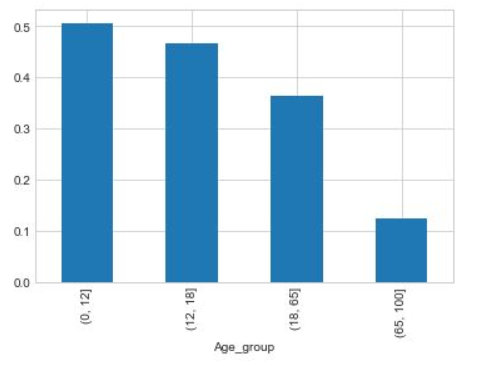
有的时候我们也经常需要查看一些数据本身的分布对数据进行划分,比如根据年龄将船上的人划分为儿童、少年、成年和老年,有点量化的感觉,这种思想在后面还会用到。

进一步剖析数据
对于一些数据分析过程中我们也要进行进一步剖析,比如名字可以转换为名字的长度,然后再与Survived与否寻找关联度。
对于缺失值
在Titanic例子里由于船舱的缺失值确实太多,有效值仅仅有204个,很难分析出不同的船舱和存活的关系,所以在做特征工程的时候,可以直接将该组特征丢弃。
当然,这里我们也可以对其进行一下分析,对于缺失的数据都分为一类。最后也能分析出一定的规律。
对于一些比较显然无关的特征可以选择性不进行分析。
4. 变量转换
这里我理解的可能也不是特别好,只是介绍下自己的心得吧。很多数据并不是数字,可能是字母或者字符串,例如Titanic里的登船地点和乘客姓名。
定性转换
常用的方法有通过Dummy Variables和Factorizing。
前者在我看来就是转换为onehot编码,比如下面这个图:

主要应对与类别比较少的情况。而后者产生了一种映射,计算字符串与数字本身的映射,主要应对与类别比较多的情况。可以想象,如果对于类别比较多的数据使用onehot编码,那么会得到一个巨大的稀疏矩阵。
定量转换
本文参考的博客中的介绍就很到位了,“Scaling可以将一个很大范围的数值映射到一个很小的范围(通常是-1 - 1,或则是0 - 1),很多情况下我们需要将数值做Scaling使其范围大小一样,否则大范围数值特征将会由更高的权重。比如:Age的范围可能只是0-100,而income的范围可能是0-10000000,在某些对数组大小敏感的模型中会影响其结果。”
还有一个方法是Binning,类似于直方图的bin将数据划分为很多块,类似于上面年龄划分,能够将连续的数据离散化。一般来说,在将数据Bining化后,要么将数据factorize化,要么dummies化。
5. 特征工程
特征工程大概是Kaggle比赛的核心,对最后的效果影响巨大,这里推荐一篇博客:《使用sklearn做单机特征工程》,里面介绍的挺清晰的。
要注意一点,做特征工程的时候别忘了同时也要对测试数据进行处理。对数据进行特征工程,也就是从各项参数中提取出对输出结果有或大或小的影响的特征,将这些特征作为训练模型的依据。一般来说都会从含缺失值的特征开始。
特征工程要基于数据分析的结果,以及上面介绍的变量转换方法与缺失值处理方法。
例如,姓名可以提取其称谓并且合并,从而形成新的特征,这里显然是基于上面对姓名内容与分布分析的结果。然后还可以为所以条目基于姓名增加姓名长度这一个属性,也就是做特征的扩展。
有的特征需要做一些填充,比如票价就少了一个值,然后再通过binning划分等级。
特征如果与结果有一定相关性则不需要丢弃,如果是数值型的则需要做一定的处理,例如dummy、factorize。
有的特征完全可以进行合并,比如Titanic题目中亲友的数量,这里不过多介绍。
Age这个特征需要比较多的考虑,因为其缺失值比较多,而且有众数或平均数也不怎么合适。既可以根据称谓信息来填充,也可以综合几项如Sex、Title、Pclass等其他没有缺失值的项,使用机器学习算法来预测Age,甚至同时进行也可以,相当于集成学习嵌套了集成学习,这种设计可能也是Kaggle比赛的一个区分度吧。
Ticket通过观察有字母和数字之分,意味着不同的位置,对Survived产生一定的影响,所以我们将Ticket中的字母分开,为数字的部分则分为一类。
像Cabin这样缺失值比较多可以直接扔掉,因为本身也很难去分析与预测。
总结一下,上面的过程涉及到了特征扩展、特征删除、缺失项预测、特征变量转换。
当然,这样的特征工程显然太过于独立,所以我们还要研究特征间的相关性,可以挑选一些主要的特征,生成特征之间的关联图,查看特征与特征之间的相关性。相关性较强的在一些情况中完全可以进行合并从而实现降维。
上面的步骤主要是对于特征本身进行处理,在宏观层面进行优化,对于抛开特征本身,我们也要做一些与之没有直接关系的基本处理,或者说“善后工作”。比如数值正则化、训练数据与测试数据再次分开。
6. 模型融合及预测
完成了上面的特征工程便可以进行模型的组装了,也就是集成学习部分。一般的步骤如下:
选出较为重要的特征
这个过程利用不同的模型来对特征进行筛选,对特征的重要性进行排序。
构建训练集和测试集
在进行特征工程的过程中,产生了大量的特征,而特征与特征之间会存在一定的相关性。太多的特征一方面会影响模型训练的速度,另一方面也可能会使得模型过拟合。所以在特征太多的情况下,我们可以利用不同的模型对特征进行筛选,选取出我们想要的前n个特征。这样的结果同样可以进行可视化。
模型融合
参考博文中提到常见的模型融合方法有:Bagging(Random Forest使用了该思想)、Boosting(AdaBoost,Gradient Boost)、Stacking、Blending。
这个划分与西瓜书中稍有不同,如果我的理解没错的话,西瓜书的思路是将集成学习划分为串行式的Boosting和并行式的Bagging与Random Forest,然后对于基学习器结合时有平均法、投票法和学习法(Stacking),这个思路我觉得可能更好理解一些。
这里面Stacking用的应该比较多,比如对于这个问题,参考博客中使用的便是Stacking。它的结构Level 1使用了:RandomForest、AdaBoost、ExtraTrees、GBDT、DecisionTree、KNN、SVM ,一共7个模型,Level 2通过XGBoost第一层预测的结果作为特征对最终的结果进行预测。
验证:学习曲线
在测试集上表现不好可能是因为训练集的欠拟合,也可能是因为过拟合而失去泛化能力。所以我们要通过学习曲线来观察模型当前处于什么状态。这个过程对于Stacking框架中第一层的各个基学习器我们都应该对其学习曲线进行观察,从而去更好地调节超参数,进而得到更好的最终结果。
预测并生成提交文件
通过上面的模型便可以得到最终结果,提交到Kaggle平台即可。整个过程对代码能力的考验也是巨大的。别看是Kaggle里入门级的Titanic,它最终完成代码量还是不小的。
7. 进一步优化
有了baseline便要进行不断的优化,比如在一定程度上修改结构,或者进行合理的调参,这可能也是比赛过程中最耗时的阶段,只有合理的优化的才能取得较高的分数。
Titanic结果
根据上面提到的那篇博客的代码,最终得分和排名如下:

这里也有个比较有趣的现象,很多人达到了1.0的准确率,我开始还是很奇怪的,不敢想象有效果这么完美的模型。后来发现因为Titanic的信息本身就是公开的,所以能够采取一些作弊的方法映射过去。不过这也就失去了比赛本身的意义了,只是得到了一个比较好看的分数。
另外Kaggle比赛中从论坛中学习也是很重要的,里面会分享很多好的方法甚至比较新奇的思路,比如我看到有人说从姓氏入手,如果一个家庭男人活下来了那么妻子和孩子活下来的可能性也很高,不过这只针题目中对这些数据了,泛化能力自然不会很高。
结语
虽然完全是照搬别人的代码,但本次尝试还是挺有艰难的,花了比想象中长很多的时间。不过收获也不少,比如Kaggle比赛的基本规则与步骤、特征工程、集成学习、sklearn和Pandas的使用甚至是jupyter notebook的使用。有时间还会再学习下别的题目,这种刷榜的比赛个人觉得还是挺有趣的。
