开始学习机器学习的内容,对大数据处理很有兴趣,希望以此为鉴好好学习。
Kaggle竞赛项目的全国过程:
- 了解问题背景:对竞赛的背景进行了解
- 下载数据
- 分析数据:expolre data analysis
- 数据处理和特征工程:data process and featureEngineering
- 模型选择:model select
- 提交结果:Submission
了解问题背景
下载数据
下载的数据分为三类:
gender_submission.csv:我们需要提交的实例
test.csv:测试数据集
train.csv:训练数据集
读取数据,分析数据
利用python强大的数据分析库pandas import pandas as pd
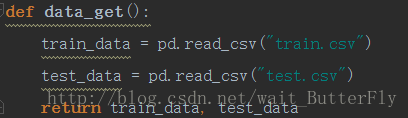
读取数据,其中type类型为dataframe
.info()函数查看当前dataframe的信息 ,常用还有.head()
训练数据集有891行12列。各列代表的信息:
· PassengerId:一个用以标记每个乘客的数字id
· Survived:标记乘客是否幸存——幸存(1)、死亡(0)。我们将预测这一列。
· Pclass:标记乘客所属船层——第一层(1),第二层(2),第三层(3)。
· Name:乘客名字。
· Sex:乘客性别——男male、女female
· Age:乘客年龄。部分。
· SibSp:船上兄弟姐妹和配偶的数量。
· Parch:船上父母和孩子的数量。
· Ticket:乘客的船票号码。
· Fare:乘客为船票付了多少钱。
· Cabin:乘客住在哪个船舱。
· Embarked:乘客从哪个地方登上泰坦尼克号数据处理和特征工程
数据分析过程中,了解业务背景是非常重要的。
age的缺失值处理(数据预处理)

sex处理,属性变换(可以用到上图中的特征提取)
Sex有两个属性:male和female,代表男性和女性。为了方便分类器处理,我们用1和0来代替。

模型选择
我们的任务是预测乘客是否能幸存,是一个基本的二分类问题。可以用来处理二分类问题的模型主要有:感知机,Logistic回归,决策树,svm和随机森林,可选的模型非常多
这里我们利用sciket-learn提供的决策树模型(DecisionTreeClassifier)
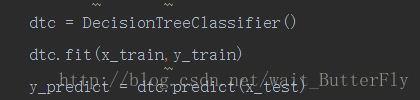
预测结果并提交
将我们训练好的模型在测试集上进行测试,将结果按照要求保存下来。将结果提交到kaggle网站,计算得分。

加入比赛就是了解比赛背景,获取数据,数据分许,特征工程,模型训练,提交结果。通过特征工程,调参,模型融合等手段提高分数。