PS(写到一半发现把博客写成了在学校的报告的模样…)
相信看到这篇博客的读者们应该知道kaggle是什么,不然也不会看到我这篇博客。
titanic作为kaggle官方入门题目,其地位堪比a+b problem在各大算法竞赛(*cpc)中的地位。
废话不多说,我们直接开始。
首先,我们可以观看一下小姐姐的视频(官方教程),就是下面这个。

或者,我们可以直接开始。
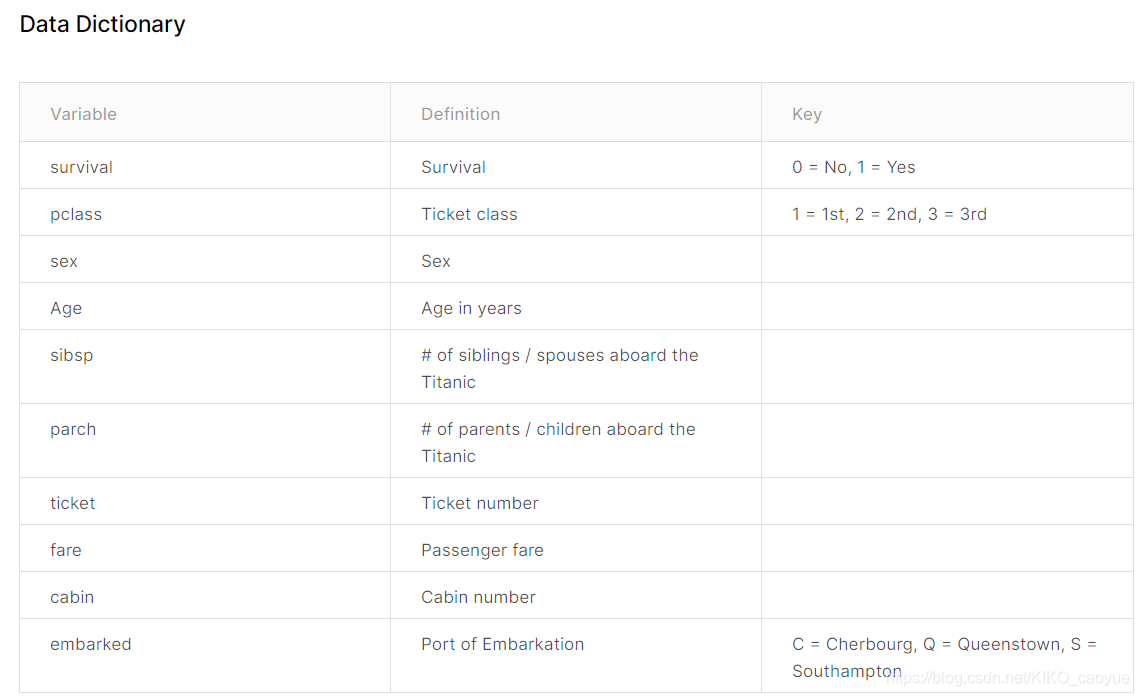
将data下载下来后,阅读数据说明。(就是下图这个)
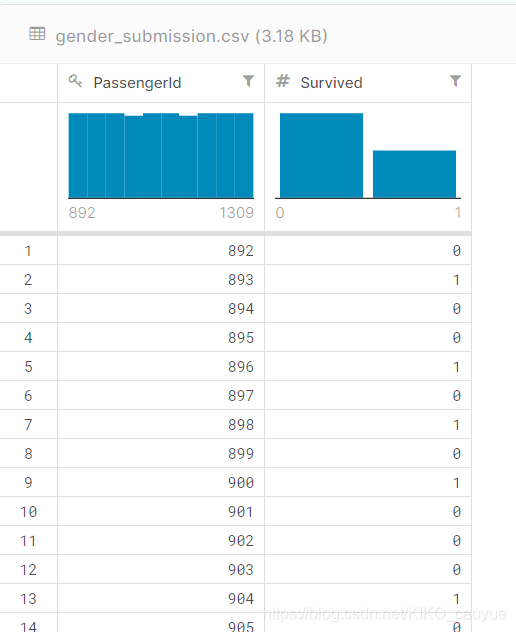
然后,观察一下提交的格式。(也就是下图这个)
查看完这些信息后,我们就可以开始做题了。
做题过程分为三部分:
- 读取数据,观察数据的格式。
- 分析数据,对数据进行处理。
- 选择合适的模型进行预测。
第一部分:读取数据,观察数据的格式
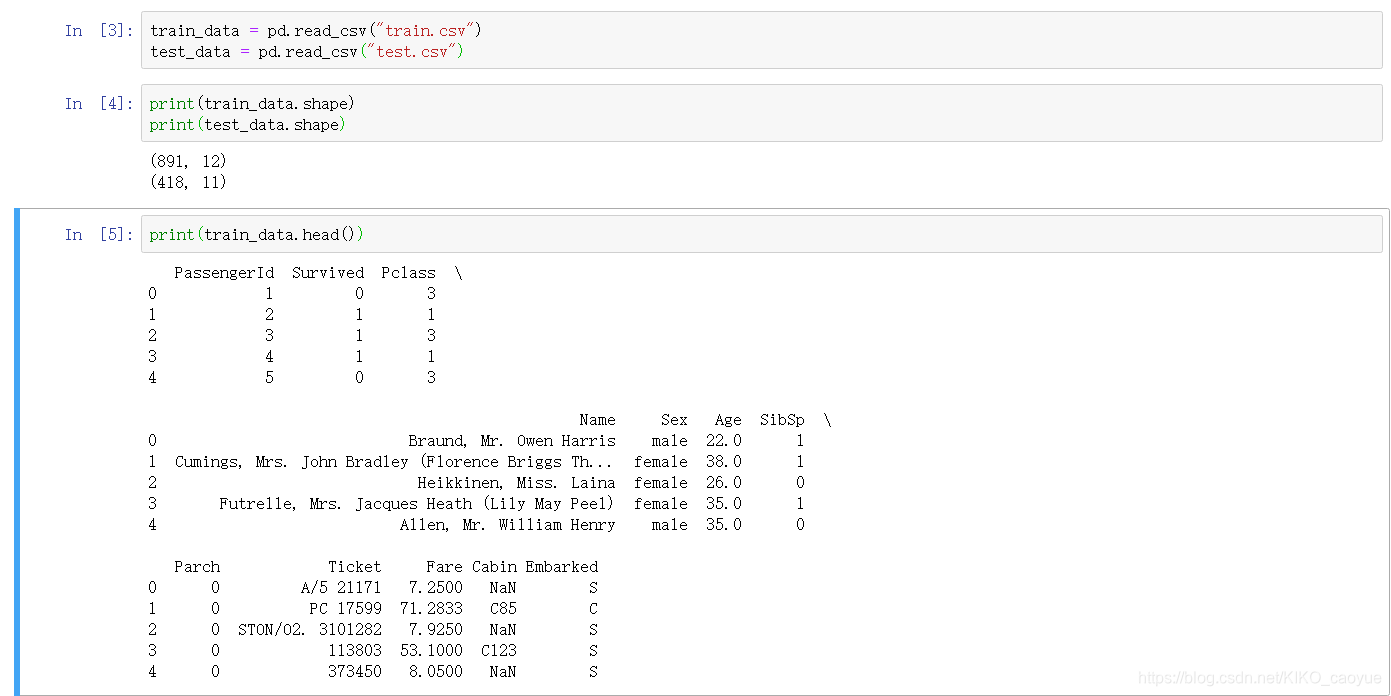
通过上图可以发现,数据中有不同类型的数据。
第二部分:分析数据,对数据进行处理
通过上图可以发现,训练集中有结果,也就是Survived列,(下文中称其为y值),将y抽取出来作为结果集。
训练集中还有不是数值类型的数据,比如Name, Cabin, Ticket, Sex等等 ,需要对他们进行分析,并且处理,简单举个例子,对Sex这类数据,用数据标号就可以,对于Name这种数据,可以观察其称呼,将称呼抽取出,或者将名称长度做成新的属性。
第三部分:选择合适的模型进行预测
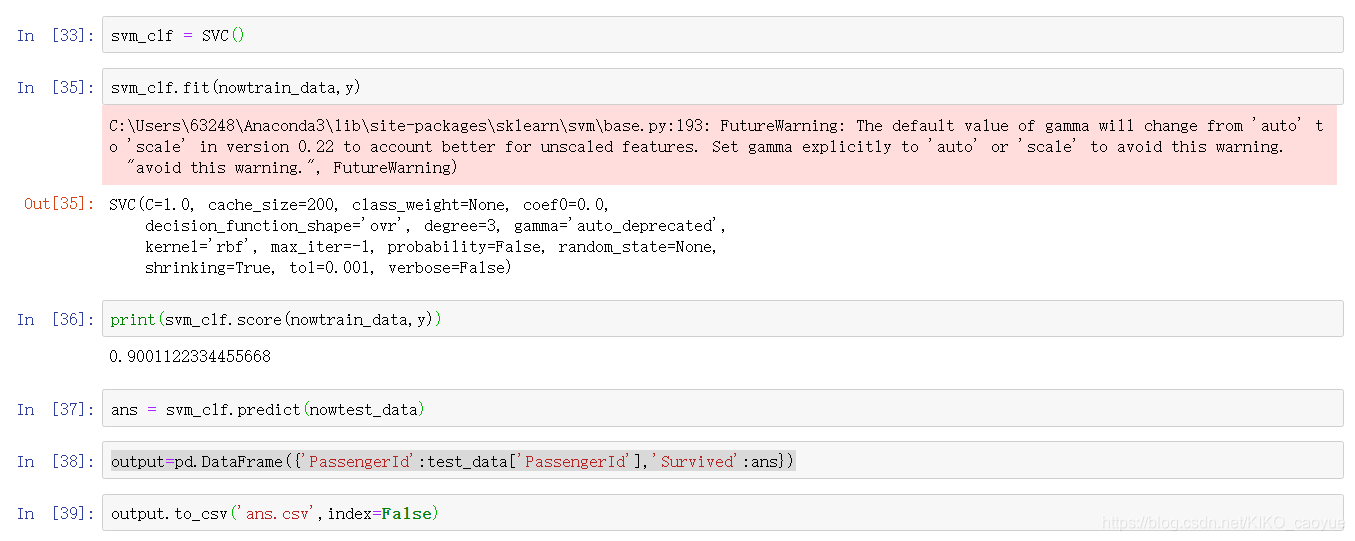
因为这个是入门题目,所以我们就用最简单的方法进行分类,直接用sklearn中的SVM对数据进行fit并预测。
最后提交数据即可。

发现直接随机的结果有43%的正确率,随便写的预测模型有59%的正确率。
以上就是kaggle入门的最简单的教程。
