本文长度20000字,约有300行python代码,建议阅读时间30分钟。
文章目录
一. 准备工作
1.1 注册账号
在kaggle 网站 https://www.kaggle.com/ 注册账号。
1.2 基础课程学习
在开始前,可以看看网站提供的快速数据科学入门课程。
课程内容包括:python基础,机器学习入门,数据可视化,pandas库,特征工程,深度学习,SQL等。都是在后续将要用到的工具,如果对这些不熟悉,建议学习一下基础课程。
在学完基础的课程后就可以尝试下titanic案例,这是一个入门的案例。
1.3 安装jupyter
使用vscode,pycharm这些也可以,但缺点是运行过程中中间变量不能看到。而jupyter,spyder类似于matlab,在一段程序运行完成后,变量仍然保存,这在vscode和pycharm中需要使用打断点的方式实现。
使用jupyter还有另外的好处,可以在代码中插入markdown格式的内容,可以做更加复杂的笔记。
Ubuntu jupyter 安装
sudo pip3 install jupyter
Windwos+VScode jupyter 安装

"C:/Program Files (x86)/Microsoft Visual Studio/Shared/Python37_64/python.exe" -m pip install -U jupyter --user
把python.exe路径替换为自己的安装路径
当然如果使用anaconda的话,在首页可以直接安装。
二. 准备开发环境和数据
一般来说,简单的机器学习算法案例需要用到的库有如下几个:
- numpy,scipy:基础的数值计算
- pandas:数据分析,数据清理,数据整合,处理大型数据和时序数据
- matplotlib,seaborn:数据可视化
- sklearn:提供大量机器学习工具,包括分类,回归,聚类,降维,模型选择,数据预处理等。
- tensorflow,pytorch,keras:深度学习工具。
安装这些python包。
还有titanic案例需要的CSV格式数据下载,根据网站指引可以看到下载地址。
三. 我的实现
首先放一个笔者自己的一个简单实现。
3.1 代码
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import lightgbm as lgb
data = pd.read_csv("data/titan/train.csv")
# print(data.head())
# 只取3列进行拟合
X = data[['Pclass', 'Age', 'Sex']]
Y = data['Survived']
# 对年龄列进行填充
X['Age'].fillna(X['Age'].mean(), inplace=True)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.25, random_state = 33)
# 使用LabelEncoder对性别列进行处理
label_encoder = LabelEncoder()
X_train['Sex'] = label_encoder.fit_transform(X_train['Sex'])
# 使用模型回归
dtrain = lgb.Dataset(X_train, Y_train)
dvalid = lgb.Dataset(X_test, Y_test)
param = {'num_leaves': 64, 'objective': 'binary'}
param['metric'] = 'auc'
num_round = 1000
bst = lgb.train(param,
dtrain,
num_round,
valid_sets=[dvalid],
early_stopping_rounds=10,
verbose_eval=False)
# Making predictions & evaluating the model
from sklearn import metrics
ypred = bst.predict(X_test)
score = metrics.roc_auc_score(Y_test, ypred)
print(f"Test AUC score: {score}")
# 对test进行同样的处理
newdata = pd.read_csv("data/titan/test.csv")
# print(data.head())
newX = newdata[['Pclass', 'Age', 'Sex']]
# 对年龄列进行填充
newX['Age'].fillna(newX['Age'].mean(), inplace=True)
# 对性别进行处理
newX['Sex'] = label_encoder.transform(newX['Sex'])
# 进行预测
ypred = bst.predict(newX)
yfinal = [int(i>0.5) for i in ypred]
# 将结果写入文件
savetemp = {'Survived':list(yfinal)}
save = pd.DataFrame(savetemp).join(newdata['PassengerId'])
save = save[['PassengerId','Survived']] #对调两列位置
file_name = 'data/titan/test1.csv'
save.to_csv(file_name,index = False)
3.2 具体思路
- 把train.csv分成train和test两部分,进行模型训练。
- 只取3个字段’Pclass’, ‘Age’, 'Sex’进行预测。
- 对缺失的的值用平均数填充
- 对类别字段’Sex’,使用LabelEncoder进行编码
最后得到的结果为74%。
四. 更好的实现(翻译)
后来在网站上找到一个对初学者比较友好的例子,基本上把前面入门课程介绍的内容都用上了。
https://www.kaggle.com/loyashoib/beginners-notebook-to-achieve-80-accuracy
以下是对这个教程的翻译:
4.1 前期准备
4.1.1 库的导入
#Machine Learning Packages
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV, cross_val_score, StratifiedKFold, learning_curve
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier, ExtraTreesClassifier, VotingClassifier
from sklearn import model_selection
#Data Processing Packages
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
from sklearn import feature_selection
#Data Visualization Packages
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
#Metrics
from sklearn import metrics
#Data Analysis Packages
import pandas as pd
import numpy as np
#Ignore Warnings
import warnings
warnings.filterwarnings('ignore')
4.1.2 数据导入
#Loading the data sets
gender_submission = pd.read_csv("../input/titanic/gender_submission.csv")
test = pd.read_csv("../input/titanic/test.csv")
train = pd.read_csv("../input/titanic/train.csv")
target = train["Survived"]
data = pd.concat([train.drop("Survived", axis=1),test], axis=0).reset_index(drop=True)
这里作者把train和test合到一起,一是便于查看整个数据的分布,二是因为每个字段间会有联系,在后续补全空值特征时可以用到整个数据的特征。
接下来对数据进行查看,看有多少行,那些字段,每个字段类型,是否有空值。
data.head() #查看数据前几行,默认是5行
data.info() # 查看数据每个字段的非空行数,总行数等信息
4.2 处理缺失数据
4.2.1 年龄
首先对年龄和其他字段分别进行关联分析
#Plotting the relations between Age and other features (Mean).
fig, ax = plt.subplots(nrows=2, ncols=3, figsize=(12,12))
#Age vs Pclass
sns.barplot(x="Pclass", y="Age", data=data, ax=ax[0,0])
#Age vs Sex
sns.barplot(x="Sex", y="Age", data=data, ax=ax[0,1])
#Age vs SibSp
sns.barplot(x="SibSp", y="Age", data=data, ax=ax[0,2])
#Age vs Parch
sns.barplot(x="Parch", y="Age", data=data, ax=ax[1,0])
#Age vs Family_size
sns.barplot(x=(data["Parch"] + data["SibSp"]), y="Age", data=data, ax=ax[1,1])
ax[1,1].set(xlabel='Family Size')
#Age vs Embarked
sns.barplot(x="Embarked", y="Age", data=data, ax=ax[1,2])
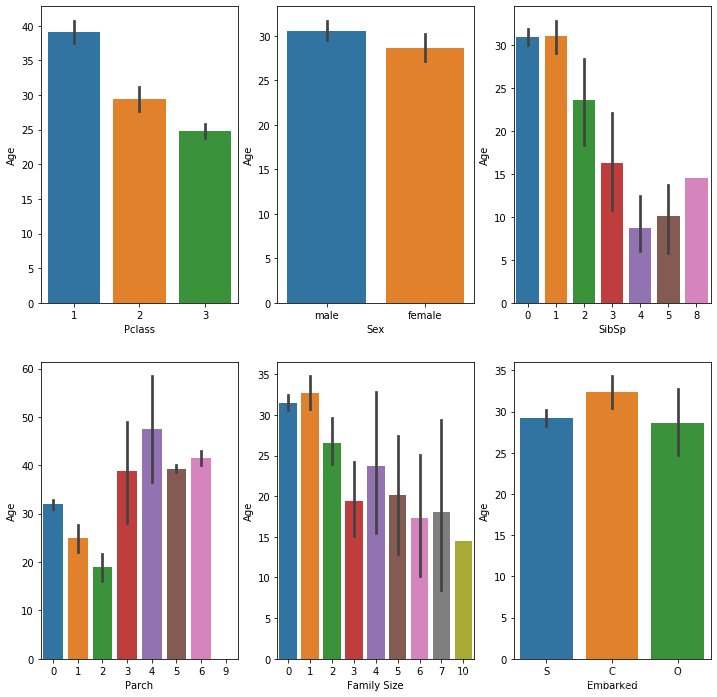
#Plotting relations between Age and other features (Median).
fig, ax = plt.subplots(nrows=2, ncols=3, figsize=(12,12))
#Age vs Pclass
sns.boxplot(x="Pclass", y="Age", data=data, ax=ax[0,0])
#Age vs Sex
sns.boxplot(x="Sex", y="Age", data=data, ax=ax[0,1])
#Age vs SibSp
sns.boxplot(x="SibSp", y="Age", data=data, ax=ax[0,2])
#Age vs Parch
sns.boxplot(x="Parch", y="Age", data=data, ax=ax[1,0])
#Age vs Family_size
sns.boxplot(x=(data["Parch"] + data["SibSp"]), y="Age", data=data, ax=ax[1,1])
ax[1,1].set(xlabel='Family Size')
#Age vs Embarked
sns.boxplot(x="Embarked", y="Age", data=data, ax=ax[1,2])
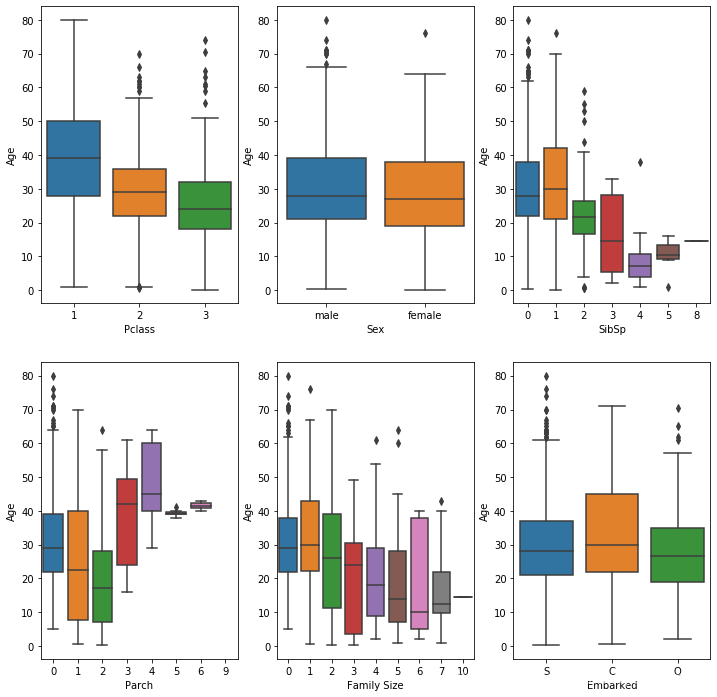
从图中分析出座位等级越高,平均年龄越大。
本教程使用Pclass, Family Size and Embarked 3个特征进行年龄填充,具体是找到和缺失年龄的列相同的Pclass, Family Size and Embarked的列所有年龄中位数进行填充,如果没有这样的行,则使用所有年龄中位数进行填充。
# First Lets create the feature Family_Size
data["Family_Size"] = data["SibSp"] + data["Parch"]
#Filling in the missing Age values
missing_age_value = data[data["Age"].isnull()]
for index, row in missing_age_value.iterrows():
median = data["Age"][(data["Pclass"] == row["Pclass"]) & (data["Embarked"] == row["Embarked"]) & (data["Family_Size"] == row["Family_Size"])].median()
if not np.isnan(median):
data["Age"][index] = median
else:
data["Age"][index] = np.median(data["Age"].dropna())
4.2.2 票价
绘制票价和舱位等级关系
#Relation Between Fare and Pclass
fig, ax = plt.subplots(figsize=(7,5))
sns.boxplot(x="Pclass", y="Fare", data=data)
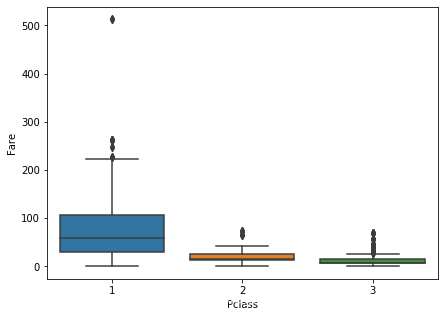
可以看出舱位等级越高,票价越高,所以用同等舱位的票价中位数进行填充
#Since we have only 1 missing value for Fare we can just fill it according to Pclass feature
print("Pclass of the data point with missing Fare value:", int(data[data["Fare"].isnull()]["Pclass"]))
median = data[data["Pclass"] == 3]["Fare"].median()
data["Fare"].fillna(median, inplace=True)
4.2.3 船舱
先查看Cabin字段有那些取值
data.Cabin.unique()
对非空字段,取第一个字母。空字段,取’X’
# 用首字母替换,null替换为’X‘
for index, rows in data.iterrows():
if pd.isnull(rows["Cabin"]):
data["Cabin"][index] = 'X'
else:
data["Cabin"][index] = str(rows["Cabin"])[0]
4.2.4 上船港口
只有两个缺失,使用众数填充
#Since we only have 2 missing Embarked values we will just fill the missing values with mode.众数
data["Embarked"].fillna(data["Embarked"].mode()[0], inplace=True)
4.3 特征工程
对数据进行清洗后,需要决定那些特征对预测比较重要,从而把它们转为及机器学习模型可以识别的形式。
4.3.1 分析存活和舱位等级,性别的关系
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(12,5))
#Survived vs Pclass
sns.barplot(x="Pclass", y=target, data=data[:891], ax=ax[0])
#Survived vs Sex
sns.barplot(x="Sex", y=target, data=data[:891], ax=ax[1])
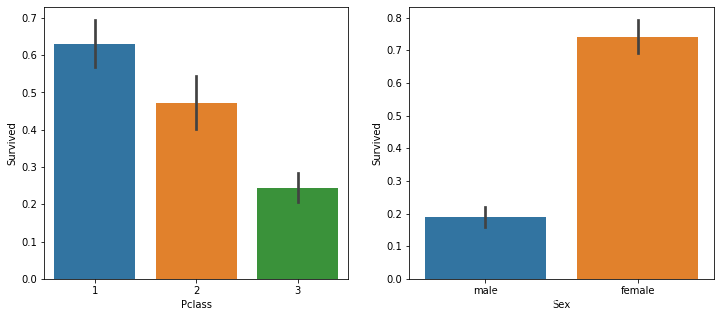
从图中看出,舱位等级越高,存活率越高,女性存活率远高于男性
4.3.2 分析存活和Family_Size的关系
Family_Size不是原始数据中的字段,而是从原始数据父母/子女,配偶/兄弟姐妹相加得到。
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(14,5))
#Survived vs Family_Size
sns.barplot(x="Family_Size", y=target, data=data[:891], ax=ax[0])
#Sex vs Single Passengers
sns.countplot(x="Sex", data=data[data["Family_Size"] == 0], ax=ax[1])
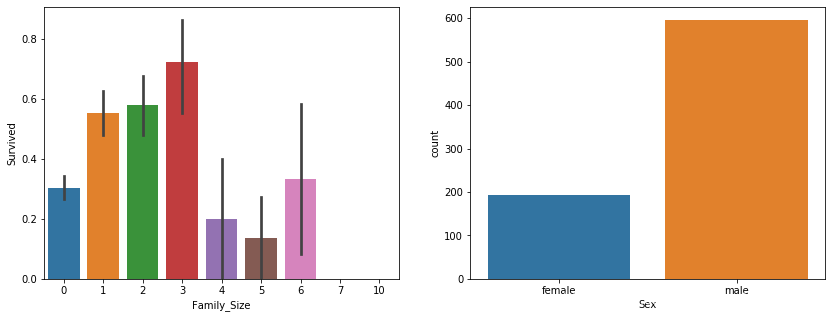
从图中看出:
1.从左图看出,单独登船的人有更低的机会存活,这可从右图得到证明:乘客中单身男性多于单身女性。
(原文:Singles have a lower chance of survival. This can be verified by the fact that there are more ‘male single’ passengers than ‘female single’ passsengers)
(译者认为此处是作者失误,从右图得到:看到单身男性加女性共有近800人,而数据总共约1300。这个结论更能证明单独登船存活机会小。)
2.家庭人数在1,2,3有更高的几率存活,这是因为女性和孩子优先逃生的事实。
3.家庭人口大于等于4,存活率反而下降,作者也不知道是什么原因。
基于此分析,可以把家庭人口分成3个等级,分别是单身,家庭人口大于等于4,家庭人口在1到3之间。
#Dividing Family_Size into 3 groups
data["Family_Size"] = data["Family_Size"].map({0:0, 1:1, 2:1, 3:1, 4:2, 5:2, 6:2, 7:2, 8:2, 9:2, 10:2})
4.3.3 分析登船港口和舱位
plt.figure(figsize=(12,7))
#Survived vs Cabin
plt.subplot(121)
sns.barplot(x="Cabin", y=target, data=data[:891])
#Survived vs Embarked
plt.subplot(122)
sns.barplot(x="Embarked", y=target, data=data[:891])
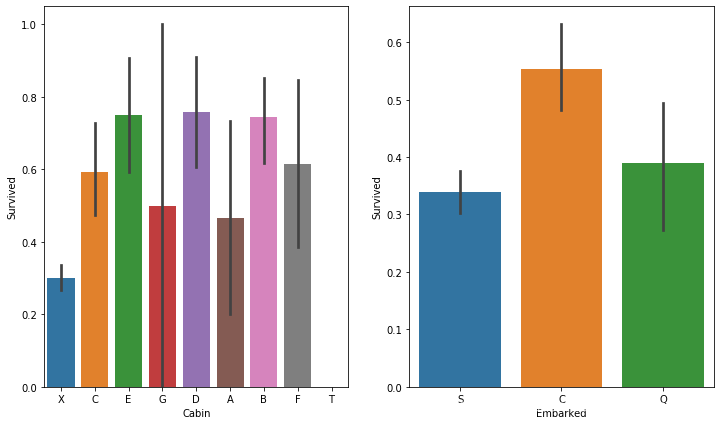
从图中看出,登船港口和舱位影响存活。先前舱位信息缺失填充为X,因此舱位缺失有更小的几率存活。
4.3.4 分析票价特征
plt.figure(figsize=(12,7))
#Plotting Kde for Fare
plt.subplot(121)
sns.kdeplot(data["Fare"])
#Plotting Kde for Fare with Survived as hue
plt.subplot(122)
sns.kdeplot(np.log(data[:891][target == 1]["Fare"]), color='blue', shade=True)
sns.kdeplot(np.log(data[:891][target == 0]["Fare"]), color='red', shade=True)
plt.legend(["Survived", "Not Survived"])
#Since skewness can result in false conclusions we reduce skew for fare by taking log.
data["Fare"] = np.log(data["Fare"])
#Dividing Fare into different categories
data["Fare"] = pd.qcut(data["Fare"], 5)
票价越高,越可能存活。这与先前结论相关印证,头等舱越有可能存活。因此票价也是一个重要的特征
4.3.5分析年龄特征
不同年龄段存活率不同,可以对年龄进行分段
label = LabelEncoder()
data["Age"] = label.fit_transform(pd.cut(data["Age"].astype(int), 5))
sns.barplot(x="Age", y=target, data=data[0:891])
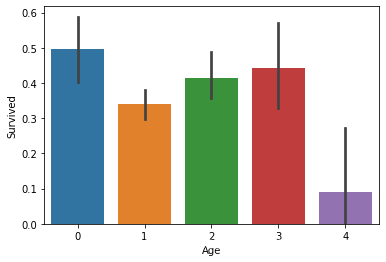
4.3.6 分析姓名特征
得到姓名中反应身份地位的字段
data["Name"] = data["Name"].apply(lambda x: x.split(",")[1].split(".")[0].strip())
得到unique值,看看这些字段包括什么
data.Name.unique()
对这些字段根据身份等级进行重映射
data["Name"] = data["Name"].map({'Mr':1, 'Miss':2, 'Mrs':3, 'Ms':3, 'Mlle':3, 'Mme':3, 'Master':4, 'Dr':5, 'Rev':5, 'Col':5, "Major":5, "Dona":5, "Sir":5, "Lady":5, "Jonkheer":5, "Don":5, "the Countess":5, "Capt":5})
sns.barplot(x="Name", y=target, data=data[0:891])
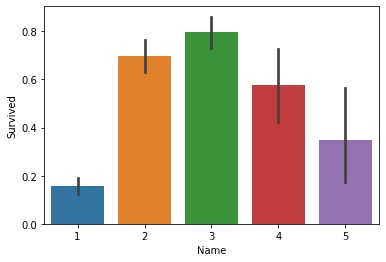
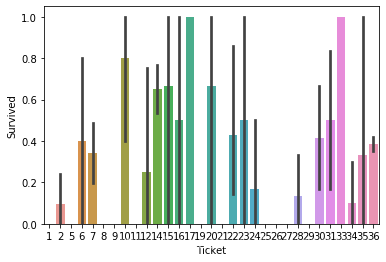
4.3.7 分析船票特征
data["Ticket"] = data["Ticket"].apply(lambda x: x.replace(".","").replace('/',"").strip().split(' ')[0] if not x.isdigit() else 'X')
data["Ticket"] = label.fit_transform(data["Ticket"])
sns.barplot(x="Ticket", y=target, data=data[0:891])
4.3.8 处理类别特征
使用get_dummies方法进行OneHot编码
data.drop(["SibSp", "Parch"], inplace=True, axis=1)
data = pd.get_dummies(data=data, columns=["Pclass", "Name", "Sex", "Age", "Cabin", "Embarked", "Family_Size", "Ticket", "Fare"], drop_first=True)
分成train和test两部分
#Splitting into train and test again
train = data[:891]
test = data[891:]
4.4 机器学习
4.4.1 代码
使用不同的模型进行测试
cv_split = model_selection.ShuffleSplit(n_splits=10, test_size=.3, train_size=.7, random_state=42)
使用这些分类器分别进行分类
classifiers = [
SVC(random_state=42),
DecisionTreeClassifier(random_state=42),
AdaBoostClassifier(DecisionTreeClassifier(random_state=42),random_state=42,learning_rate=0.1),
RandomForestClassifier(random_state=42),
ExtraTreesClassifier(random_state=42),
GradientBoostingClassifier(random_state=42),
MLPClassifier(random_state=42),
KNeighborsClassifier(),
LogisticRegression(random_state=42),
LinearDiscriminantAnalysis()
]
cv_train_mean = []
cv_test_mean = []
cv_score_time = []
cv_fit_time = []
cv_name = []
predictions = []
for classifier in classifiers :
cv_results = model_selection.cross_validate(classifier, train.drop(['PassengerId'], axis=1), target, cv=cv_split, return_train_score=True)
cv_train_mean.append(cv_results['train_score'].mean())
cv_test_mean.append(cv_results['test_score'].mean())
cv_score_time.append(cv_results['score_time'].mean())
cv_fit_time.append(cv_results['fit_time'].mean())
cv_name.append(str(classifier.__class__.__name__))
classifier.fit(train.drop(['PassengerId'], axis=1), target)
predictions.append(classifier.predict(test.drop(['PassengerId'], axis=1)))
print(str(classifier.__class__.__name__))
performance_df = pd.DataFrame({"Algorithm":cv_name, "Train Score":cv_train_mean, "Test Score":cv_test_mean, 'Score Time':cv_score_time, 'Fit Time':cv_fit_time})
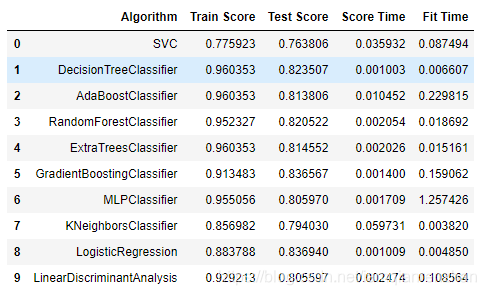
4.4.2 查看结果
performance_df
4.4.3 绘制结果
#Plotting the performance on test set
sns.barplot('Test Score', 'Algorithm', data=performance_df)
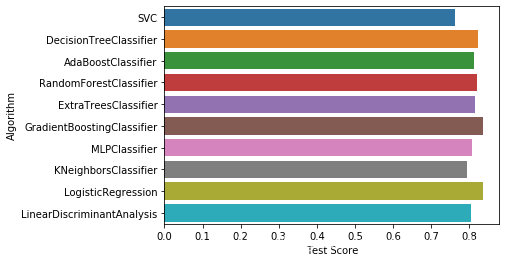
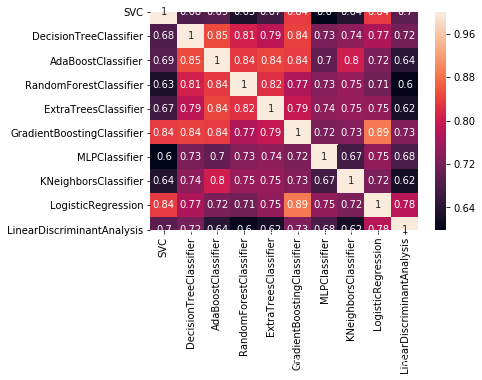
4.4.4 交叉分析
#Plotting prediction correlation of the algorithms
sns.heatmap(pd.DataFrame(predictions, index=cv_name).T.corr(), annot=True)
4.5 调参
4.5.1 模型定义及参数空间选择
tuned_clf = {
'DecisionTreeClassifier':DecisionTreeClassifier(random_state=42),
'AdaBoostClassifier':AdaBoostClassifier(DecisionTreeClassifier(random_state=42),random_state=42,learning_rate=0.1),
'RandomForestClassifier':RandomForestClassifier(random_state=42),
'ExtraTreesClassifier':ExtraTreesClassifier(random_state=42),
'GradientBoostingClassifier':GradientBoostingClassifier(random_state=42),
'MLPClassifier':MLPClassifier(random_state=42),
'LogisticRegression':LogisticRegression(random_state=42),
'LinearDiscriminantAnalysis':LinearDiscriminantAnalysis()
}
#DecisionTreeClassifier
grid = {'criterion': ['gini', 'entropy'], 'splitter': ['best', 'random'], 'max_depth': [2,4,6,8,10,None],
'min_samples_split': [2,5,10,.03,.05], 'min_samples_leaf': [1,5,10,.03,.05], 'max_features': [None, 'auto']}
tune_model = model_selection.GridSearchCV(tuned_clf['DecisionTreeClassifier'], param_grid=grid, scoring = 'roc_auc', cv = cv_split, return_train_score=True)
tune_model.fit(train.drop(['PassengerId'], axis=1), target)
print("Best Parameters:")
print(tune_model.best_params_)
tuned_clf['DecisionTreeClassifier'].set_params(**tune_model.best_params_)
#AdaBoostClassifier
grid = {'n_estimators': [10, 50, 100, 300], 'learning_rate': [.01, .03, .05, .1, .25], 'algorithm': ['SAMME', 'SAMME.R'] }
tune_model = model_selection.GridSearchCV(tuned_clf['AdaBoostClassifier'], param_grid=grid, scoring = 'roc_auc', cv = cv_split, return_train_score=True)
tune_model.fit(train.drop(['PassengerId'], axis=1), target)
print("Best Parameters:")
print(tune_model.best_params_)
tuned_clf['AdaBoostClassifier'].set_params(**tune_model.best_params_)
#RandomForestClassifier
grid = {'n_estimators': [10, 50, 100, 300], 'criterion': ['gini', 'entropy'], 'max_depth': [2, 4, 6, 8, 10, None],
'oob_score': [True] }
tune_model = model_selection.GridSearchCV(tuned_clf['RandomForestClassifier'], param_grid=grid, scoring = 'roc_auc', cv = cv_split, return_train_score=True)
tune_model.fit(train.drop(['PassengerId'], axis=1), target)
print("Best Parameters:")
print(tune_model.best_params_)
tuned_clf['RandomForestClassifier'].set_params(**tune_model.best_params_)
#ExtraTreesClassifier
grid = {'n_estimators': [10, 50, 100, 300], 'criterion': ['gini', 'entropy'], 'max_depth': [2, 4, 6, 8, 10, None]}
tune_model = model_selection.GridSearchCV(tuned_clf['ExtraTreesClassifier'], param_grid=grid, scoring = 'roc_auc', cv = cv_split, return_train_score=True)
tune_model.fit(train.drop(['PassengerId'], axis=1), target)
print("Best Parameters:")
print(tune_model.best_params_)
tuned_clf['ExtraTreesClassifier'].set_params(**tune_model.best_params_)
#GradientBoostingClassifier
grid = {#'loss': ['deviance', 'exponential'], 'learning_rate': [.01, .03, .05, .1, .25],
'n_estimators': [300],
#'criterion': ['friedman_mse', 'mse', 'mae'],
'max_depth': [4] }
tune_model = model_selection.GridSearchCV(tuned_clf['GradientBoostingClassifier'], param_grid=grid, scoring = 'roc_auc', cv = cv_split, return_train_score=True)
tune_model.fit(train.drop(['PassengerId'], axis=1), target)
print("Best Parameters:")
print(tune_model.best_params_)
tuned_clf['GradientBoostingClassifier'].set_params(**tune_model.best_params_)
#MLPClassifier
grid = {'learning_rate': ["constant", "invscaling", "adaptive"], 'alpha': 10.0 ** -np.arange(1, 7), 'activation': ["logistic", "relu", "tanh"]}
tune_model = model_selection.GridSearchCV(tuned_clf['MLPClassifier'], param_grid=grid, scoring = 'roc_auc', cv = cv_split, return_train_score=True)
tune_model.fit(train.drop(['PassengerId'], axis=1), target)
print("Best Parameters:")
print(tune_model.best_params_)
tuned_clf['MLPClassifier'].set_params(**tune_model.best_params_)
#LogisticRegression
grid = {'fit_intercept': [True, False], 'penalty': ['l2'], 'solver': ['newton-cg', 'lbfgs', 'liblinear', 'sag', 'saga']}
tune_model = model_selection.GridSearchCV(tuned_clf['LogisticRegression'], param_grid=grid, scoring = 'roc_auc', cv = cv_split, return_train_score=True)
tune_model.fit(train.drop(['PassengerId'], axis=1), target)
print("Best Parameters:")
print(tune_model.best_params_)
tuned_clf['LogisticRegression'].set_params(**tune_model.best_params_)
#LinearDiscriminantAnalysis
grid = {"solver" : ["svd"], "tol" : [0.0001,0.0002,0.0003]}
tune_model = model_selection.GridSearchCV(tuned_clf['LinearDiscriminantAnalysis'], param_grid=grid, scoring = 'roc_auc', cv = cv_split, return_train_score=True)
tune_model.fit(train.drop(['PassengerId'], axis=1), target)
print("Best Parameters:")
print(tune_model.best_params_)
tuned_clf['LinearDiscriminantAnalysis'].set_params(**tune_model.best_params_)
4.5.2 评估每个模型
#Evaluating the performance of our tuned models
cv_train_mean = []
cv_test_mean = []
cv_score_time = []
cv_fit_time = []
cv_name = []
predictions = []
for _, classifier in tuned_clf.items():
cv_results = model_selection.cross_validate(classifier, train.drop(['PassengerId'], axis=1), target, cv=cv_split, return_train_score=True)
cv_train_mean.append(cv_results['train_score'].mean())
cv_test_mean.append(cv_results['test_score'].mean())
cv_score_time.append(cv_results['score_time'].mean())
cv_fit_time.append(cv_results['fit_time'].mean())
cv_name.append(str(classifier.__class__.__name__))
classifier.fit(train.drop(['PassengerId'], axis=1), target)
predictions.append(classifier.predict(test.drop(['PassengerId'], axis=1)))
performance_df = pd.DataFrame({"Algorithm":cv_name, "Train Score":cv_train_mean, "Test Score":cv_test_mean, 'Score Time':cv_score_time, 'Fit Time':cv_fit_time})
performance_df
4.5.3 投票分类器进行最终预测
# 投票分类器
voting_3 = VotingClassifier(estimators=[
('DecisionTreeClassifier', tuned_clf['DecisionTreeClassifier']),
('AdaBoostClassifier', tuned_clf['AdaBoostClassifier']),
('RandomForestClassifier', tuned_clf['RandomForestClassifier']),
('ExtraTreesClassifier',tuned_clf['ExtraTreesClassifier']),
('GradientBoostingClassifier',tuned_clf['GradientBoostingClassifier']),
('MLPClassifier',tuned_clf['MLPClassifier']),
('LogisticRegression', tuned_clf['LogisticRegression']),
('LinearDiscriminantAnalysis', tuned_clf['LinearDiscriminantAnalysis'])], voting='soft', n_jobs=4)
voting_3 = voting_3.fit(train.drop(['PassengerId'], axis=1), target)
pred_3 = voting_3.predict(test.drop(['PassengerId'], axis=1))
sol3 = pd.DataFrame(data=pred_3, columns=['Survived'], index=test['PassengerId'])
sol3.to_csv("data/titan/sol3.csv")
