Pair RDD 的转化操作
对已有的pair RDD,可进行一系列转化操作。
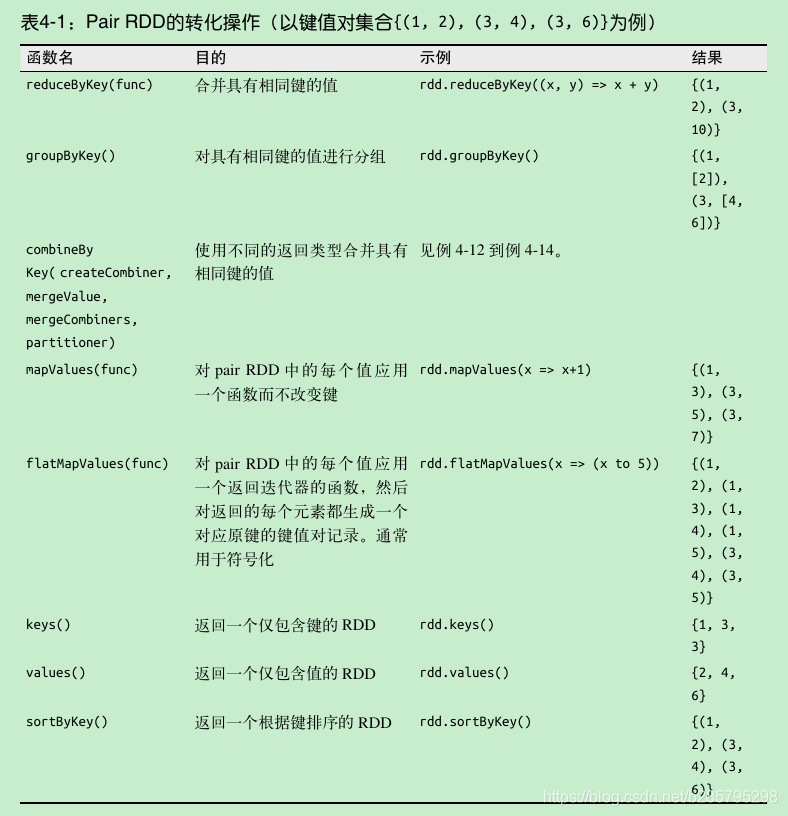



combineByKey() 是最为常用的基于键进行聚合的函数。如果这是一个新的元素,combineByKey() 会使用一个叫作 createCombiner() 的函数来创建那个键对应的累加器的初始值。如果这是一个在处理当前分区之前已经遇到的键,它会使用 mergeValue() 方法将该键的累加器对应的当前值与这个新的值进行合并。
由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器,就需要使用用户提供的 mergeCombiners() 方法将各个分区的结果进行合并。


数据分区
Spark 程序可以通过控制RDD 分区方式来减少通信开销。分区并不是对所有应用都有好处的——比如,如果给定RDD 只需要被扫描一次,我们完全没有必要对其预先进行分区处理。只有当数据集多次在诸如连接这种基于键的操作中使用时,分区才会有帮助。
Spark 中所有的键值对 RDD 都可以进行分区。
系统会根据一个针对键的函数对元素进行分组。尽管 Spark 没有给出显示控制每个键具体落在哪一个工作节点上的方法(部分原因是Spark 即使在某些节点失败时依然可以工作),但 Spark 可以确保同一组的键出现在同一个节点上。比如,你可能使用哈希分区将一个 RDD 分成了 100 个分区,此时键的哈希值对100 取模的结果相同的记录会被放在一个节点上。你也可以使用范围分区法,将键在同一个范围区间内的记录都放在同一个节点上。
默认情况下,连接操作会将两个数据集中的所有键的哈希值都求出来,将该哈希值相同的记录通过网络传到同一台机器上,然后在那台机器上对所有键相同的记录进行连接操作。
对表使用 partitionBy() 转化操作,将表转为哈希分区。可以通过向 partitionBy 传递一个 spark.HashPartitioner 对象来实现。

注意, partitionBy() 是一个转化操作,因此它的返回值总是一个新的 RDD,但它不会改变原来的 RDD。RDD 一旦创建就无法修改。因此应该对 partitionBy() 的结果进行持久化,并保存为 userData,而不是原来的 sequenceFile() 的输出。此外,传给 partitionBy() 的100 表示分区数目,它会控制之后对这个 RDD 进行进一步操作(比如连接操作)时有多少任务会并行执行。总的来说,这个值至少应该和集群中的总核心数一样。
Spark 的许多操作都引入了将数据根据键跨节点进行混洗的过程。所有这些操作都会从 数 据 分 区 中 获 益。 就 Spark 1.0 而 言, 能 够 从 数 据 分 区 中 获 益 的 操 作 有 cogroup()、groupWith()、join()、leftOuterJoin()、rightOuterJoin()、groupByKey()、 reduceByKey()、combineByKey() 以及 lookup()。