一、什么是Spark Shuffle?
1、Shuffle中文意思就是“洗牌”,在Spark中Shuffle的目的是为了保证每一个key所对应的value都会汇聚到同一个节点上去处理和聚合。
2、在Spark中,什么情况下会发生shuffle?
reduceByKey、groupByKey、sortByKey、countByKey、join等操作。
3、Spark中的Shuffle包括两种:
- HashShuffle
- SortShuffle
二、HashShuffle运行原理
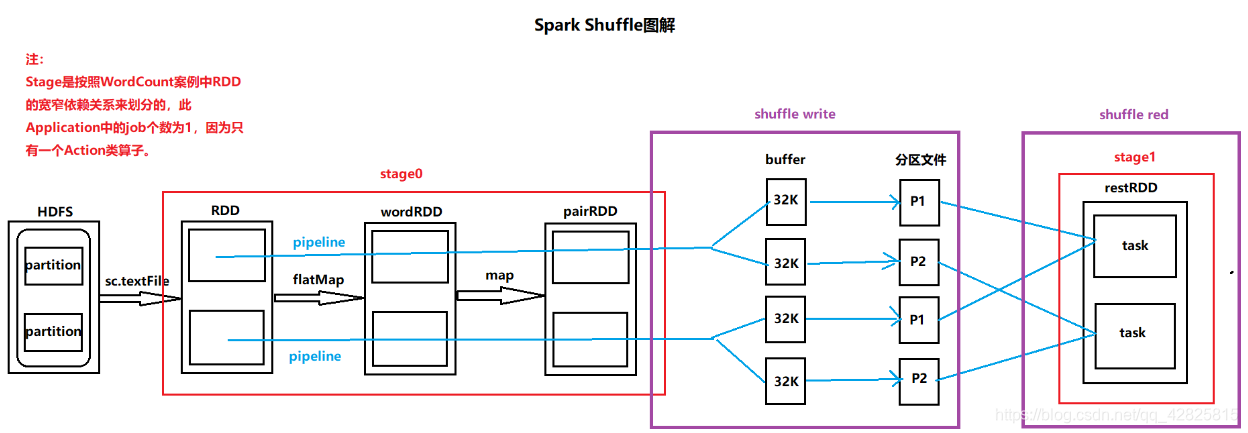
Shuffle Write阶段:
由于Stage后面紧跟了另一个Stage,所以数据落地会发生在Shuffle Write阶段。为了将分区中数据相同的key写入一个分区文件中,需要将task计算结果的key的hashcode值与Reduce task个数取模,从而确定将结果写入哪个分区文件中,这样即可保证相同的key在一个分区文件中。为了加快向磁盘写文件的速度,需要事先设置一个buffer作为缓存,每个buffer的大小是32K。
Shuffle Red阶段:
Reduce task从上个Stage的task节点中拉取属于自己的分区文件,这样即可保证每一个Key所对应的Value都会在同一个节点上。拉取的过程属于现拉现用。
三、Shuffle可能面临的问题?
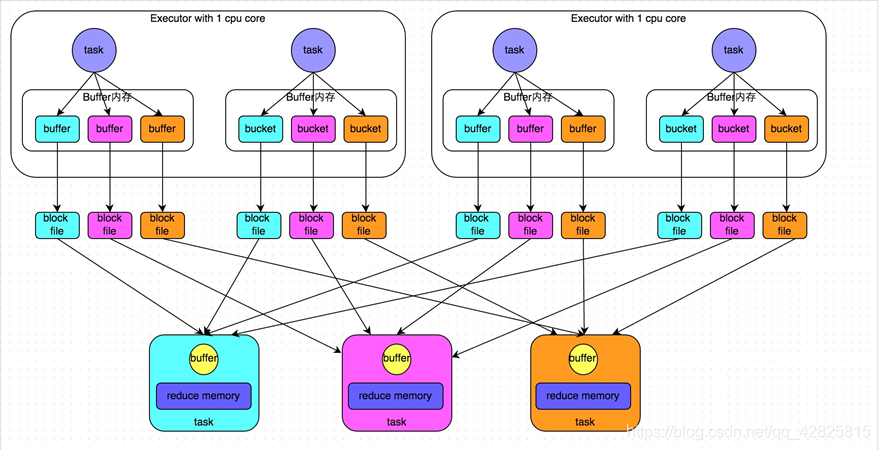
由上图可知:磁盘小文件(分区文件)的个数=m(map task num)*r(reduce task num)
当磁盘小文件过多时,带来的问题有:
- write阶段会创建大量写文件的对象
- read阶段拉取数据需要进行多次网络传输
- read阶段会创建大量读文件的对象
- 读写对象过多造成JVM内存不足,从而导致内存溢出
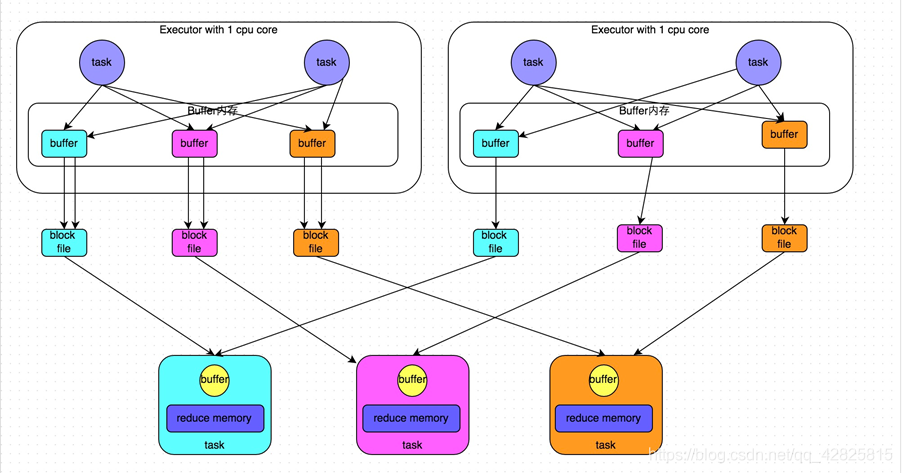
为了解决磁盘小文件过多,Spark中推出了合并机制来减少磁盘小文件。
合并机制:
倘若Executor只有一个core,所以每次只能有一个task执行,当第一个task执行完成后,第二个task会复用第一个task所创建的buffer和磁盘文件,从而减少磁盘文件的个数。
合并前:
合并后:
四、如何优化解决问题?
五、SortShuffle运行原理
未完待续。。。