Spark Streaming实时数据流处理
一、Spark Streaming基础
1、Spark Streaming简介
http://spark.apache.org/docs/latest/streaming-programming-guide.html
Spark Streaming是核心Spark API的扩展,可实现可扩展、高吞吐量、可容错的实时数据流处理。数据可以从诸如Kafka,Flume,Kinesis或TCP套接字等众多来源获取,并且可以使用由高级函数(如map,reduce,join和window)开发的复杂算法进行流数据处理。最后,处理后的数据可以被推送到文件系统,数据库和实时仪表板。而且,您还可以在数据流上应用Spark提供的机器学习和图处理算法。
2、Spark Streaming的特点
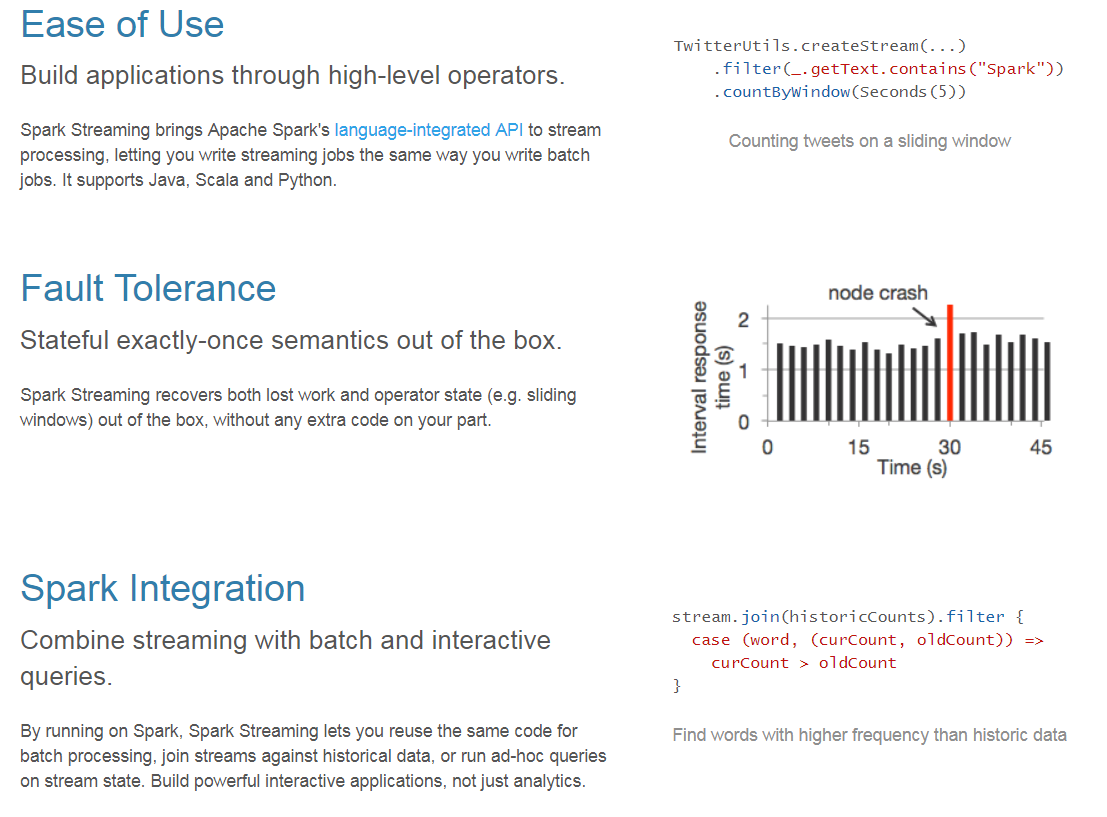
便于使用
通过高级操作员构建应用程序。
Spark Streaming将Apache Spark的 语言集成API 引入流处理,使您可以像编写批处理作业一样编写流式作业。它支持Java,Scala和Python。
容错
开箱即用的有状态的一次性语义。
Spark Streaming可以开箱即用,恢复丢失的工作和操作员状态(例如滑动窗口),而无需任何额外的代码。
Spark集成
将流式传输与批量和交互式查询相结合。
通过在Spark上运行,Spark Streaming允许您重复使用相同的代码进行批处理,将流加入历史数据,或者在流状态下运行即席查询。构建强大的交互式应用程序,而不只是分析。
3、Spark Streaming的内部结构
在内部,它的工作原理如下。Spark Streaming接收实时输入数据流,并将数据切分成批,然后由Spark引擎对其进行处理,最后生成“批”形式的结果流。
Spark Streaming将连续的数据流抽象为discretizedstream或DStream。在内部,DStream 由一个RDD序列表示。
4、第一个小案例:NetworkWordCount
(1)由于在本案例中需要使用netcat网络工具,所以需要先安装。
rpm -iUv ~/netcat-0.6.1-1.i386.rpm
(2)启动netcat数据流服务器,并监听端口:1234
命令:nc -l -p 9999
服务器端:

(3)启动客户端
bin/run-example streaming.NetworkWordCount localhost 1234
客户端: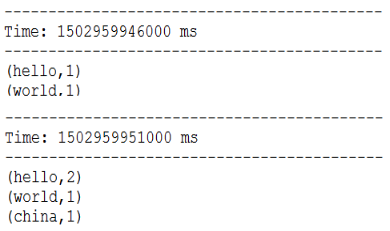
(一定注意):如果要执行本例,必须确保机器cpu核数大于 2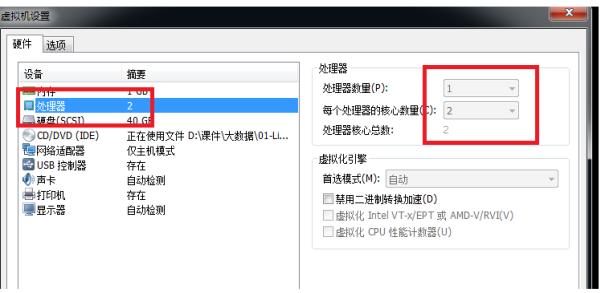
5、开发自己的NetworkWordCount
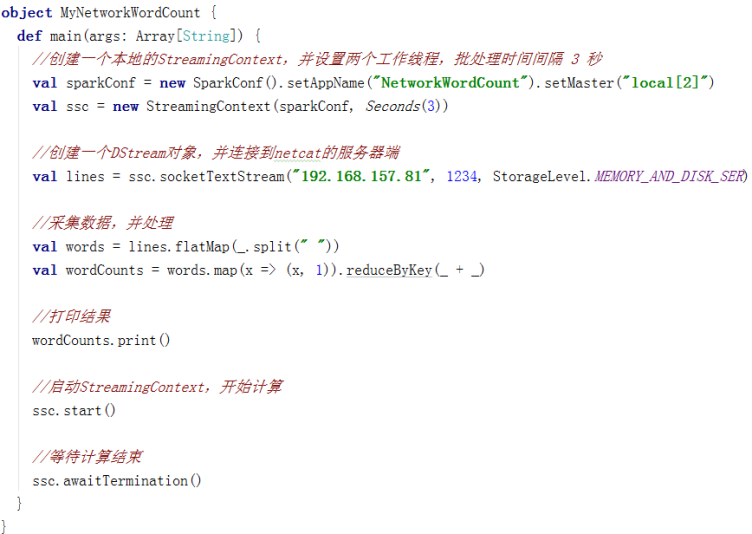
(一定注意):
val sparkConf = new SparkConf().setAppName("NetworkWordCount").setMaster("local[2]")
官方的解释: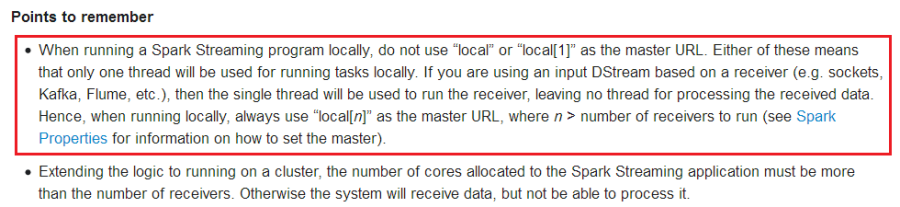
二、Spark Streaming进阶
1、StreamingContext对象详解
初始化StreamingContext
方式一:从SparkConf对象中创建
从一个现有的SparkContext实例中创建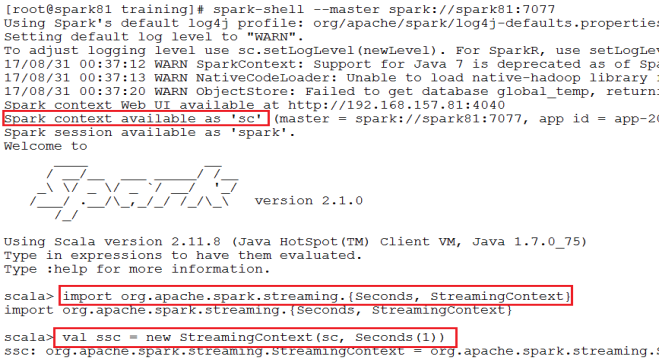
程序中的几点说明:
appName参数是应用程序在集群UI上显示的名称。
master是Spark,Mesos或YARN集群的URL,或者一个特殊的“local [*]”字符串来让程序以本地模式运行。
当在集群上运行程序时,不需要在程序中硬编码master参数,而是使用spark-submit提交应用程序并将master的URL以脚本参数的形式传入。但是,对于本地测试和单元测试,您可以通过“local[*]”来运行Spark Streaming程序(请确保本地系统中的cpu核心数够用)。
StreamingContext会内在的创建一个SparkContext的实例(所有Spark功能的起始点),你可以通过ssc.sparkContext访问到这个实例。
批处理的时间窗口长度必须根据应用程序的延迟要求和可用的集群资源进行设置。
请务必记住以下几点:
一旦一个StreamingContextt开始运作,就不能设置或添加新的流计算。
一旦一个上下文被停止,它将无法重新启动。
同一时刻,一个JVM中只能有一个StreamingContext处于活动状态。
StreamingContext上的stop()方法也会停止SparkContext。 要仅停止StreamingContext(保持SparkContext活跃),请将stop() 方法的可选参数stopSparkContext设置为false。
只要前一个StreamingContext在下一个StreamingContext被创建之前停止(不停止SparkContext),SparkContext就可以被重用来创建多个StreamingContext。
2、离散流(DStreams):Discretized Streams
l DiscretizedStream或DStream 是Spark Streaming对流式数据的基本抽象。它表示连续的数据流,这些连续的数据流可以是从数据源接收的输入数据流,也可以是通过对输入数据流执行转换操作而生成的经处理的数据流。在内部,DStream由一系列连续的RDD表示,如下图: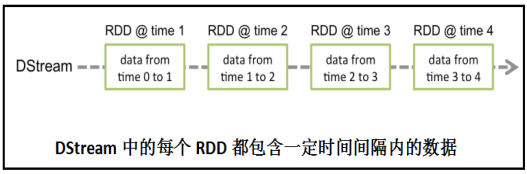
l 举例分析:在之前的NetworkWordCount的例子中,我们将一行行文本组成的流转换为单词流,具体做法为:将flatMap操作应用于名为lines的 DStream中的每个RDD上,以生成words DStream的RDD。如下图所示: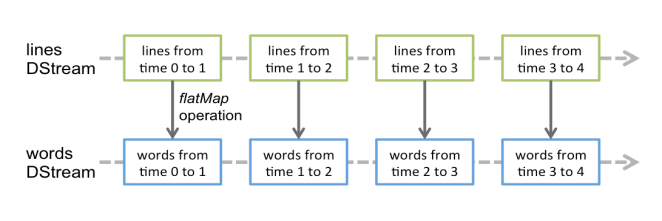
但是DStream和RDD也有区别,下面画图说明: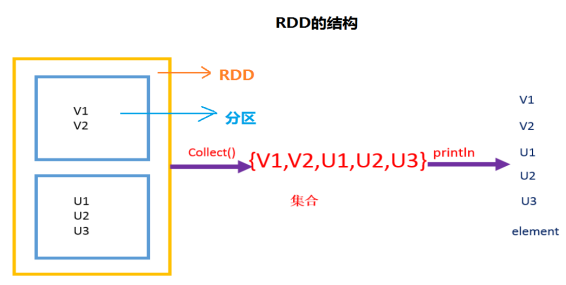

3、DStream中的转换操作(transformation)
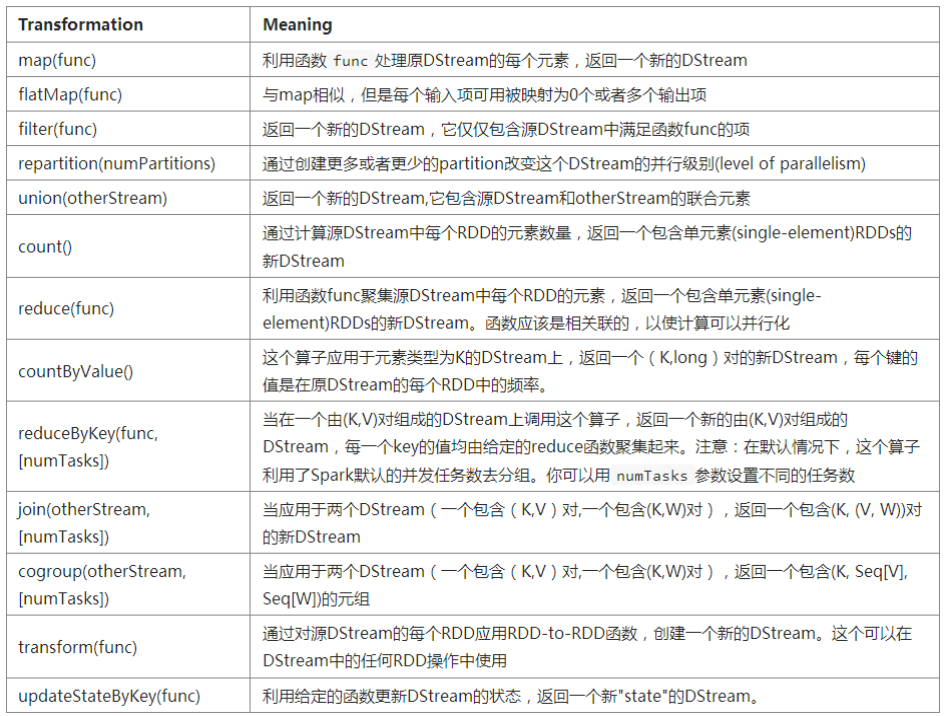
最后两个transformation算子需要重点介绍一下:
1.transform(func)
通过RDD-to-RDD函数作用于源DStream中的各个RDD,可以是任意的RDD操作,从而返回一个新的RDD
举例:在NetworkWordCount中,也可以使用transform来生成元组对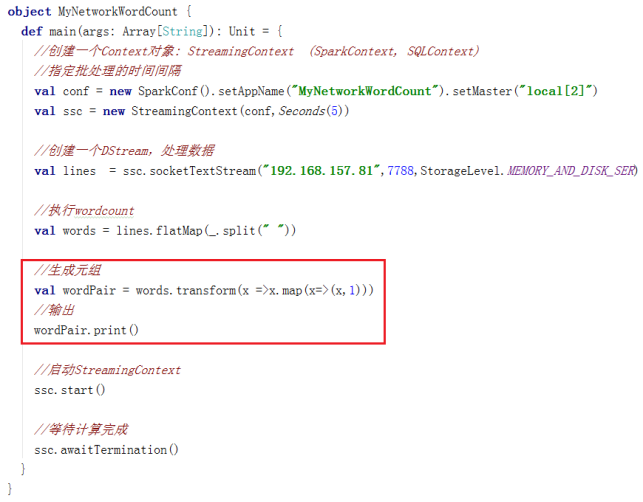
2.updateStateByKey(func)
操作允许不断用新信息更新它的同时保持任意状态。
定义状态-状态可以是任何的数据类型
定义状态更新函数-怎样利用更新前的状态和从输入流里面获取的新值更新状态
重写NetworkWordCount程序,累计每个单词出现的频率(注意:累计)


package demo import org.apache.spark.SparkConf import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.{Seconds, StreamingContext} object MyTotalNetworkWordCount { def main(args: Array[String]): Unit = { //创建一个Context对象: StreamingContext (SparkContext, SQLContext) //指定批处理的时间间隔 val conf = new SparkConf().setAppName("MyNetworkWordCount").setMaster("local[2]") val ssc = new StreamingContext(conf,Seconds(5)) //设置检查点 ssc.checkpoint("hdfs://192.168.157.11:9000/spark/checkpoint") //创建一个DStream,处理数据 val lines = ssc.socketTextStream("192.168.157.81",7788,StorageLevel.MEMORY_AND_DISK_SER) //执行wordcount val words = lines.flatMap(_.split(" ")) //定义函数用于累计每个单词的总频率 val addFunc = (currValues: Seq[Int], prevValueState: Option[Int]) => { //通过Spark内部的reduceByKey按key规约,然后这里传入某key当前批次的Seq/List,再计算当前批次的总和 val currentCount = currValues.sum // 已累加的值 val previousCount = prevValueState.getOrElse(0) // 返回累加后的结果,是一个Option[Int]类型 Some(currentCount + previousCount) } val pairs = words.map(word => (word, 1)) val totalWordCounts = pairs.updateStateByKey[Int](addFunc) totalWordCounts.print() ssc.start() ssc.awaitTermination() } }
输出结果:
n 注意:如果在IDEA中,不想输出log4j的日志信息,可以将log4j.properties文件(放在src的目录下)的第一行改为:
log4j.rootCategory=ERROR, console
4、窗口操作
Spark Streaming还提供了窗口计算功能,允许您在数据的滑动窗口上应用转换操作。下图说明了滑动窗口的工作方式: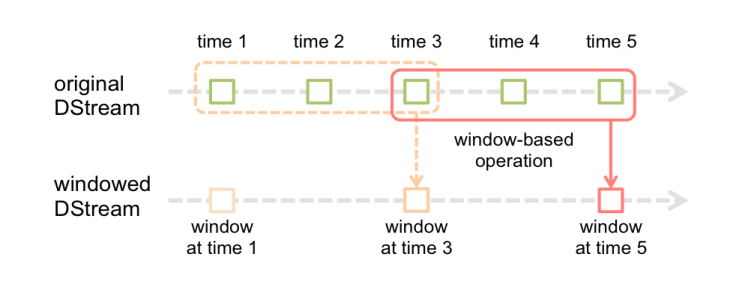
如图所示,每当窗口滑过originalDStream时,落在窗口内的源RDD被组合并被执行操作以产生windowed DStream的RDD。在上面的例子中,操作应用于最近3个时间单位的数据,并以2个时间单位滑动。这表明任何窗口操作都需要指定两个参数。
窗口长度(windowlength) - 窗口的时间长度(上图的示例中为:3)。
滑动间隔(slidinginterval) - 两次相邻的窗口操作的间隔(即每次滑动的时间长度)(上图示例中为:2)。
这两个参数必须是源DStream的批间隔的倍数(上图示例中为:1)。
我们以一个例子来说明窗口操作。 假设您希望对之前的单词计数的示例进行扩展,每10秒钟对过去30秒的数据进行wordcount。为此,我们必须在最近30秒的pairs DStream数据中对(word, 1)键值对应用reduceByKey操作。这是通过使用reduceByKeyAndWindow操作完成的。
一些常见的窗口操作如下表所示。所有这些操作都用到了上述两个参数 - windowLength和slideInterval。
window(windowLength, slideInterval)
基于源DStream产生的窗口化的批数据计算一个新的DStream
countByWindow(windowLength, slideInterval)
返回流中元素的一个滑动窗口数
reduceByWindow(func, windowLength, slideInterval)
返回一个单元素流。利用函数func聚集滑动时间间隔的流的元素创建这个单元素流。函数必须是相关联的以使计算能够正确的并行计算。
reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks])
应用到一个(K,V)对组成的DStream上,返回一个由(K,V)对组成的新的DStream。每一个key的值均由给定的reduce函数聚集起来。注意:在默认情况下,这个算子利用了Spark默认的并发任务数去分组。你可以用numTasks参数设置不同的任务数
reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks])
上述reduceByKeyAndWindow() 的更高效的版本,其中使用前一窗口的reduce计算结果递增地计算每个窗口的reduce值。这是通过对进入滑动窗口的新数据进行reduce操作,以及“逆减(inverse reducing)”离开窗口的旧数据来完成的。一个例子是当窗口滑动时对键对应的值进行“一加一减”操作。但是,它仅适用于“可逆减函数(invertible reduce functions)”,即具有相应“反减”功能的减函数(作为参数invFunc)。 像reduceByKeyAndWindow一样,通过可选参数可以配置reduce任务的数量。 请注意,使用此操作必须启用检查点。
countByValueAndWindow(windowLength, slideInterval, [numTasks])
应用到一个(K,V)对组成的DStream上,返回一个由(K,V)对组成的新的DStream。每个key的值都是它们在滑动窗口中出现的频率。
5、输入DStreams和接收器
输入DStreams表示从数据源获取输入数据流的DStreams。在NetworkWordCount例子中,lines表示输入DStream,它代表从netcat服务器获取的数据流。每一个输入流DStream和一个Receiver对象相关联,这个Receiver从源中获取数据,并将数据存入内存中用于处理。
输入DStreams表示从数据源获取的原始数据流。Spark Streaming拥有两类数据源:
基本源(Basic sources):这些源在StreamingContext API中直接可用。例如文件系统、套接字连接、Akka的actor等
高级源(Advanced sources):这些源包括Kafka,Flume,Kinesis,Twitter等等。
下面通过具体的案例,详细说明:
- 文件流:通过监控文件系统的变化,若有新文件添加,则将它读入并作为数据流
需要注意的是:
① 这些文件具有相同的格式
② 这些文件通过原子移动或重命名文件的方式在dataDirectory创建
③ 如果在文件中追加内容,这些追加的新数据也不会被读取。
注意:要演示成功,需要在原文件中编辑,然后拷贝一份。
RDD队列流
使用streamingContext.queueStream(queueOfRDD)创建基于RDD队列的DStream,用于调试Spark Streaming应用程序。
package demo import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import org.apache.spark.streaming.{Seconds, StreamingContext} import scala.collection.mutable object RDDQueueStream { def main(args: Array[String]) { val conf = new SparkConf().setMaster("local").setAppName("queueStream") //每1秒对数据进行处理 val ssc = new StreamingContext(conf,Seconds(1)) //创建一个能够push到QueueInputDStream的RDDs队列 val rddQueue = new mutable.Queue[RDD[Int]]() //基于一个RDD队列创建一个输入源 val inputStream = ssc.queueStream(rddQueue) //将接收到的数据乘以10 val mappedStream = inputStream.map(x => (x,x*10)) mappedStream.print() ssc.start() for(i <- 1 to 3){ rddQueue += ssc.sparkContext.makeRDD(1 to 10) //创建RDD,并分配两个核数 Thread.sleep(1000) } ssc.stop() } }
套接字流:通过监听Socket端口来接收数据
package demo import org.apache.spark.SparkConf import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.{Seconds, StreamingContext} object ScoketStreaming { def main(args: Array[String]) { //创建一个本地的StreamingContext,含2个工作线程 val conf = new SparkConf().setMaster("local[4]").setAppName("ScoketStreaming") val sc = new StreamingContext(conf,Seconds(5)) //每隔10秒统计一次字符总数 //创建珍一个DStream,连接127.0.0.1 :7788 val lines = sc.socketTextStream("127.0.0.1",7788) //打印数据 lines.print() sc.start() //开始计算 sc.awaitTermination() //通过手动终止计算,否则一直运行下去 } }
6、DStreams的输出操作
输出操作允许DStream的操作推到如数据库、文件系统等外部系统中。因为输出操作实际上是允许外部系统消费转换后的数据,它们触发的实际操作是DStream转换。目前,定义了下面几种输出操作:
foreachRDD的设计模式
DStream.foreachRDD是一个强大的原语,发送数据到外部系统中。
第一步:创建连接,将数据写入外部数据库(使用之前的NetworkWordCount,改写之前输出结果的部分,如下)
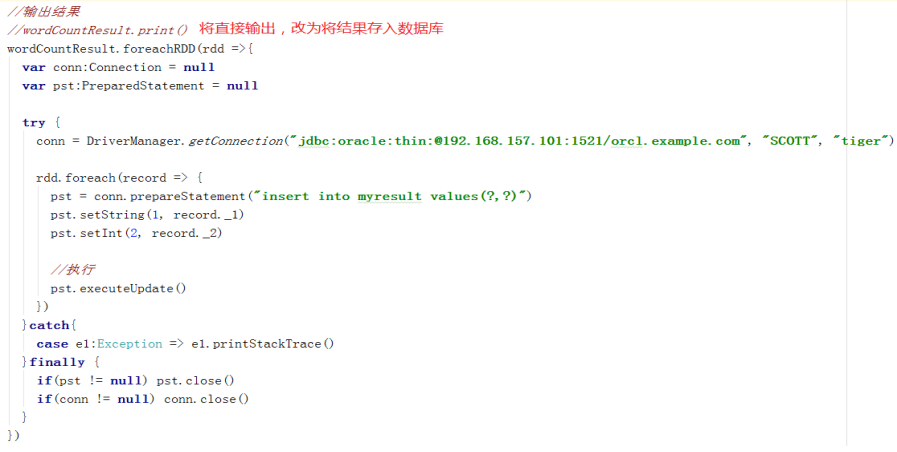
出现以下Exception:
原因是:Connection对象不是一个可被序列化的对象,不能RDD的每个Worker上运行;即:Connection不能在RDD分布式环境中的每个分区上运行,因为不同的分区可能运行在不同的Worker上。所以需要在每个RDD分区上单独创建Connection对象。
第二步:在每个RDD分区上单独创建Connection对象,如下:
View Code
7、DataFrame和SQL操作
我们可以很方便地使用DataFrames和SQL操作来处理流数据。您必须使用当前的StreamingContext对应的SparkContext创建一个SparkSession。此外,必须这样做的另一个原因是使得应用可以在driver程序故障时得以重新启动,这是通过创建一个可以延迟实例化的单例SparkSession来实现的。
在下面的示例中,我们使用DataFrames和SQL来修改之前的wordcount示例并对单词进行计数。我们将每个RDD转换为DataFrame,并注册为临时表,然后在这张表上执行SQL查询。
package demo import org.apache.spark.SparkConf import org.apache.spark.sql.SparkSession import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.{Seconds, StreamingContext} object MyNetworkWordCountDataFrame { def main(args: Array[String]): Unit = { //创建一个Context对象: StreamingContext (SparkContext, SQLContext) //指定批处理的时间间隔 val conf = new SparkConf().setAppName("MyNetworkWordCount").setMaster("local[2]") val ssc = new StreamingContext(conf, Seconds(5)) //创建一个DStream,处理数据 val lines = ssc.socketTextStream("192.168.157.81", 7788, StorageLevel.MEMORY_AND_DISK_SER) //执行wordcount val words = lines.flatMap(_.split(" ")) //使用Spark SQL来查询Spark Streaming处理的数据 words.foreachRDD { rdd => //使用单列模式,创建SparkSession对象 val spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate() import spark.implicits._ // 将RDD[String]转换为DataFrame val wordsDataFrame = rdd.toDF("word") // 创建临时视图 wordsDataFrame.createOrReplaceTempView("words") // 执行SQL val wordCountsDataFrame = spark.sql("select word, count(*) as total from words group by word") wordCountsDataFrame.show() } //启动StreamingContext ssc.start() //等待计算完成 ssc.awaitTermination() } }
8、缓存/持久化
与RDD类似,DStreams还允许开发人员将流数据保留在内存中。也就是说,在DStream上调用persist() 方法会自动将该DStream的每个RDD保留在内存中。如果DStream中的数据将被多次计算(例如,相同数据上执行多个操作),这个操作就会很有用。对于基于窗口的操作,如reduceByWindow和reduceByKeyAndWindow以及基于状态的操作,如updateStateByKey,数据会默认进行持久化。 因此,基于窗口的操作生成的DStream会自动保存在内存中,而不需要开发人员调用persist()。
对于通过网络接收数据(例如Kafka,Flume,sockets等)的输入流,默认持久化级别被设置为将数据复制到两个节点进行容错。
请注意,与RDD不同,DStreams的默认持久化级别将数据序列化保存在内存中。
9、检查点支持
流数据处理程序通常都是全天候运行,因此必须对应用中逻辑无关的故障(例如,系统故障,JVM崩溃等)具有弹性。为了实现这一特性,Spark Streaming需要checkpoint足够的信息到容错存储系统,以便可以从故障中恢复。
① 一般会对两种类型的数据使用检查点:
1) 元数据检查点(Metadatacheckpointing) - 将定义流计算的信息保存到容错存储中(如HDFS)。这用于从运行streaming程序的driver程序的节点的故障中恢复。元数据包括以下几种:
l 配置(Configuration) - 用于创建streaming应用程序的配置信息。
l DStream操作(DStream operations) - 定义streaming应用程序的DStream操作集合。
l 不完整的batch(Incomplete batches) - jobs还在队列中但尚未完成的batch。
2) 数据检查点(Datacheckpointing) - 将生成的RDD保存到可靠的存储层。对于一些需要将多个批次之间的数据进行组合的stateful变换操作,设置数据检查点是必需的。在这些转换操作中,当前生成的RDD依赖于先前批次的RDD,这导致依赖链的长度随时间而不断增加,由此也会导致基于血统机制的恢复时间无限增加。为了避免这种情况,stateful转换的中间RDD将定期设置检查点并保存到到可靠的存储层(例如HDFS)以切断依赖关系链。
总而言之,元数据检查点主要用于从driver程序故障中恢复,而数据或RDD检查点在任何使用stateful转换时是必须要有的。
② 何时启用检查点:
对于具有以下任一要求的应用程序,必须启用检查点:
1) 使用状态转:如果在应用程序中使用updateStateByKey或reduceByKeyAndWindow(具有逆函数),则必须提供检查点目录以允许定期保存RDD检查点。
2) 从运行应用程序的driver程序的故障中恢复:元数据检查点用于使用进度信息进行恢复。
③ 如何配置检查点:
可以通过在一些可容错、高可靠的文件系统(例如,HDFS,S3等)中设置保存检查点信息的目录来启用检查点。这是通过使用streamingContext.checkpoint(checkpointDirectory)完成的。设置检查点后,您就可以使用上述的有状态转换操作。此外,如果要使应用程序从驱动程序故障中恢复,您应该重写streaming应用程序以使程序具有以下行为:
1) 当程序第一次启动时,它将创建一个新的StreamingContext,设置好所有流数据源,然后调用start()方法。
2) 当程序在失败后重新启动时,它将从checkpoint目录中的检查点数据重新创建一个StreamingContext。
使用StreamingContext.getOrCreate可以简化此行为
④ 改写之前的WordCount程序,使得每次计算的结果和状态都保存到检查点目录下
package demo import org.apache.spark.SparkConf import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.{Seconds, StreamingContext} object MyCheckpointNetworkWordCount { def main(args: Array[String]): Unit = { //在主程序中,创建一个Streaming Context对象 //1、读取一个检查点的目录 //2、如果该目录下已经存有之前的检查点信息,从已有的信息上创建这个Streaming Context对象 //3、如果该目录下没有信息,创建一个新的Streaming Context val context = StreamingContext.getOrCreate("hdfs://192.168.157.111:9000/spark_checkpoint",createStreamingContext) //启动任务 context.start() context.awaitTermination() } //创建一个StreamingContext对象,并且设置检查点目录,执行WordCount程序(记录之前的状态信息) def createStreamingContext():StreamingContext = { val conf = new SparkConf().setAppName("MyCheckpointNetworkWordCount").setMaster("local[2]") //创建这个StreamingContext对象 val ssc = new StreamingContext(conf,Seconds(3)) //设置检查点目录 ssc.checkpoint("hdfs://192.168.157.111:9000/spark_checkpoint") //创建一个DStream,执行WordCount val lines = ssc.socketTextStream("192.168.157.81",7788,StorageLevel.MEMORY_AND_DISK_SER) //分词操作 val words = lines.flatMap(_.split(" ")) //每个单词记一次数 val wordPair = words.map(x=> (x,1)) //执行单词计数 //定义一个新的函数:把当前的值跟之前的结果进行一个累加 val addFunc = (currValues:Seq[Int],preValueState:Option[Int]) => { //当前当前批次的值 val currentCount = currValues.sum //得到已经累加的值。如果是第一次求和,之前没有数值,从0开始计数 val preValueCount = preValueState.getOrElse(0) //进行累加,然后累加后结果,是Option[Int] Some(currentCount + preValueCount) } //要把新的单词个数跟之前的结果进行叠加(累计) val totalCount = wordPair.updateStateByKey[Int](addFunc) //输出结果 totalCount.print() //返回这个对象 ssc } }
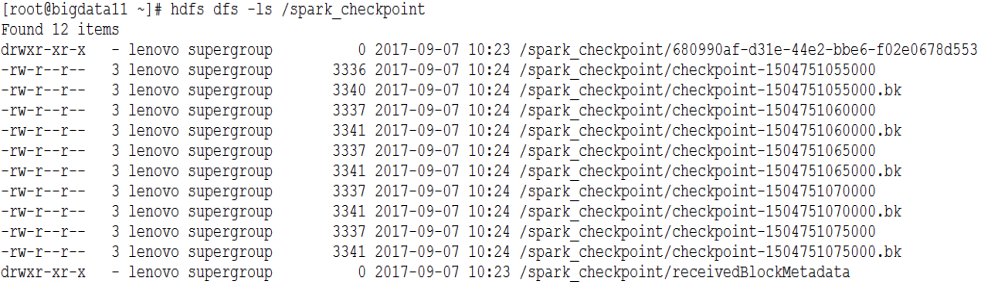
通过查看HDFS中的信息,可以看到相关的检查点信息,如下:
三、高级数据源
1、Spark Streaming接收Flume数据
基于Flume的Push模式
Flume被用于在Flume agents之间推送数据.在这种方式下,Spark Streaming可以很方便的建立一个receiver,起到一个Avro agent的作用.Flume可以将数据推送到改receiver.
- 第一步:Flume的配置文件
View Code#bin/flume-ng agent -n a4 -f myagent/a4.conf -c conf -Dflume.root.logger=INFO,console #定义agent名, source、channel、sink的名称 a4.sources = r1 a4.channels = c1 a4.sinks = k1 #具体定义source a4.sources.r1.type = spooldir a4.sources.r1.spoolDir = /root/training/logs #具体定义channel a4.channels.c1.type = memory a4.channels.c1.capacity = 10000 a4.channels.c1.transactionCapacity = 100 #具体定义sink a4.sinks = k1 a4.sinks.k1.type = avro a4.sinks.k1.channel = c1 a4.sinks.k1.hostname = 192.168.157.1 a4.sinks.k1.port = 1234 #组装source、channel、sink a4.sources.r1.channels = c1 a4.sinks.k1.channel = c1
- 第二步:Spark Streaming程序
View Codepackage demo import org.apache.spark.SparkConf import org.apache.spark.streaming.flume.FlumeUtils import org.apache.spark.streaming.{Seconds, StreamingContext} object MyFlumeStream { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("SparkFlumeNGWordCount").setMaster("local[2]") val ssc = new StreamingContext(conf, Seconds(5)) //创建FlumeEvent的DStream val flumeEvent = FlumeUtils.createStream(ssc,"192.168.157.1",1234) //将FlumeEvent中的事件转成字符串 val lineDStream = flumeEvent.map( e => { new String(e.event.getBody.array) }) //输出结果 lineDStream.print() ssc.start() ssc.awaitTermination(); } }
- 第三步:注意除了需要使用Flume的lib的jar包以外,还需要以下jar包:
spark-streaming-flume_2.10-2.1.0.jar
- 第四步:测试
启动Spark Streaming程序
启动Flume
拷贝日志文件到/root/training/logs目录
观察输出,采集到数据
基于Custom Sink的Pull模式
不同于Flume直接将数据推送到Spark Streaming中,第二种模式通过以下条件运行一个正常的Flume sink。Flume将数据推送到sink中,并且数据保持buffered状态。Spark Streaming使用一个可靠的Flume接收器和转换器从sink拉取数据。只要当数据被接收并且被Spark Streaming备份后,转换器才运行成功。
这样,与第一种模式相比,保证了很好的健壮性和容错能力。然而,这种模式需要为Flume配置一个正常的sink。
以下为配置步骤:
- 第一步:Flume的配置文件
View Code#bin/flume-ng agent -n a1 -f myagent/a1.conf -c conf -Dflume.root.logger=INFO,console a1.channels = c1 a1.sinks = k1 a1.sources = r1 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /root/training/logs a1.channels.c1.type = memory a1.channels.c1.capacity = 100000 a1.channels.c1.transactionCapacity = 100000 a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink a1.sinks.k1.channel = c1 a1.sinks.k1.hostname = 192.168.157.81 a1.sinks.k1.port = 1234 #组装source、channel、sink a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
- 第二步:Spark Streaming程序
View Codepackage demo import org.apache.spark.SparkConf import org.apache.spark.storage.StorageLevel import org.apache.spark.streaming.flume.FlumeUtils import org.apache.spark.streaming.{Seconds, StreamingContext} object FlumeLogPull { def main(args: Array[String]) { val conf = new SparkConf().setAppName("SparkFlumeNGWordCount").setMaster("local[2]") val ssc = new StreamingContext(conf, Seconds(10)) //创建FlumeEvent的DStream val flumeEvent = FlumeUtils.createPollingStream(ssc,"192.168.157.81",1234,StorageLevel.MEMORY_ONLY_SER_2) //将FlumeEvent中的事件转成字符串 val lineDStream = flumeEvent.map( e => { new String(e.event.getBody.array) }) //输出结果 lineDStream.print() ssc.start() ssc.awaitTermination(); } }
- 第三步:需要的jar包
spark-streaming-flume-sink_2.10-2.1.0.jar
将Spark的jar包拷贝到Flume的lib目录下
下面的这个jar包也需要拷贝到Flume的lib目录下,同时加入IDEA工程的classpath
- 第四步:测试
启动Flume
在IDEA中启动FlumeLogPull
将测试数据拷贝到/root/training/logs
观察IDEA中的输出

2、Spark Streaming接收Kafka数据
Apache Kafka是一种高吞吐量的分布式发布订阅消息系统。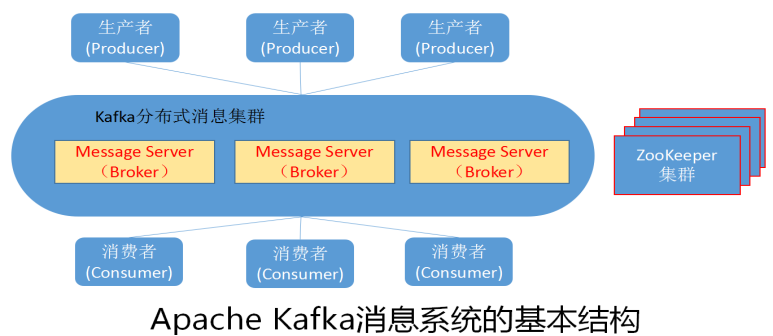
搭建ZooKeeper(Standalone):
(*)配置/root/training/zookeeper-3.4.10/conf/zoo.cfg文件
dataDir=/root/training/zookeeper-3.4.10/tmp
server.1=spark81:2888:3888
(*)在/root/training/zookeeper-3.4.10/tmp目录下创建一个myid的空文件
echo 1 > /root/training/zookeeper-3.4.6/tmp/myid
搭建Kafka环境(单机单broker):
(*)修改server.properties文件
(*)启动Kafka
bin/kafka-server-start.sh config/server.properties &
出现以下错误:
需要修改bin/kafka-run-class.sh文件,将这个选项注释掉。
(*)测试Kafka
创建Topic
bin/kafka-topics.sh --create --zookeeper spark81:2181 -replication-factor 1 --partitions 3 --topic mydemo1
发送消息
bin/kafka-console-producer.sh --broker-list spark81:9092 --topic mydemo1
接收消息
bin/kafka-console-consumer.sh --zookeeper spark81:2181 --topic mydemo1
搭建Spark Streaming和Kafka的集成开发环境
由于Spark Streaming和Kafka集成的时候,依赖的jar包比较多,而且还会产生冲突。强烈建议使用Maven的方式来搭建项目工程。
下面是依赖的pom.xml文件:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>ZDemo5</groupId> <artifactId>ZDemo5</artifactId> <version>1.0-SNAPSHOT</version> <properties> <spark.version>2.1.0</spark.version> <scala.version>2.11</scala.version> </properties> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming-kafka-0-8_2.11</artifactId> <version>2.1.1</version> </dependency> </dependencies> </project>
基于Receiver的方式
这个方法使用了Receivers来接收数据。Receivers的实现使用到Kafka高层次的消费者API。对于所有的Receivers,接收到的数据将会保存在Spark executors中,然后由Spark Streaming启动的Job来处理这些数据。
- 开发Spark Streaming的Kafka Receivers
View Codepackage demo import org.apache.spark.SparkConf import org.apache.spark.streaming.kafka.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext} object KafkaWordCount { def main(args: Array[String]) { val conf = new SparkConf().setAppName("SparkFlumeNGWordCount").setMaster("local[2]") val ssc = new StreamingContext(conf, Seconds(10)) //创建topic名称,1表示一次从这个topic中获取一条记录 val topics = Map("mydemo1" ->1) //创建Kafka的输入流,指定ZooKeeper的地址 val kafkaStream = KafkaUtils.createStream(ssc,"192.168.157.81:2181","mygroup",topics) //处理每次接收到的数据 val lineDStream = kafkaStream.map(e => { new String(e.toString()) }) //输出结果 lineDStream.print() ssc.start() ssc.awaitTermination(); } }
- 测试
启动Kafka消息的生产者
bin/kafka-console-producer.sh --broker-list spark81:9092 --topic mydemo1
在IDEA中启动任务,接收Kafka消息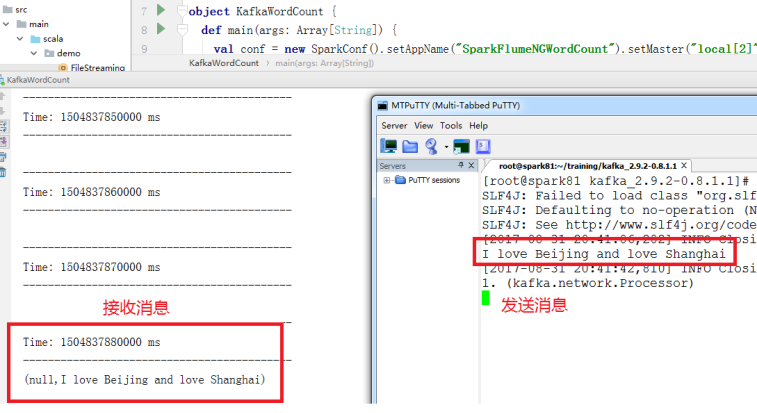
l 直接读取方式
和基于Receiver接收数据不一样,这种方式定期地从Kafka的topic+partition中查询最新的偏移量,再根据定义的偏移量范围在每个batch里面处理数据。当作业需要处理的数据来临时,spark通过调用Kafka的简单消费者API读取一定范围的数据。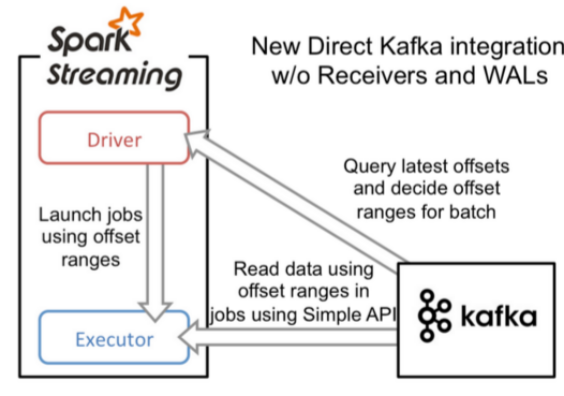
- 开发Spark Streaming的程序
View Codepackage demo import kafka.serializer.StringDecoder import org.apache.spark.SparkConf import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.streaming.kafka.KafkaUtils object DirectKafkaWordCount { def main(args: Array[String]) { val conf = new SparkConf().setAppName("SparkFlumeNGWordCount").setMaster("local[2]") val ssc = new StreamingContext(conf, Seconds(10)) //创建topic名称,1表示一次从这个topic中获取一条记录 val topics = Set("mydemo1") //指定Kafka的broker地址 val kafkaParams = Map[String, String]("metadata.broker.list" -> "192.168.157.81:9092") //创建DStream,接收Kafka的数据 val kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics) //处理每次接收到的数据 val lineDStream = kafkaStream.map(e => { new String(e.toString()) }) //输出结果 lineDStream.print() ssc.start() ssc.awaitTermination(); } }
- 测试
启动Kafka消息的生产者
bin/kafka-console-producer.sh --broker-list spark81:9092 --topic mydemo1
在IDEA中启动任务,接收Kafka消息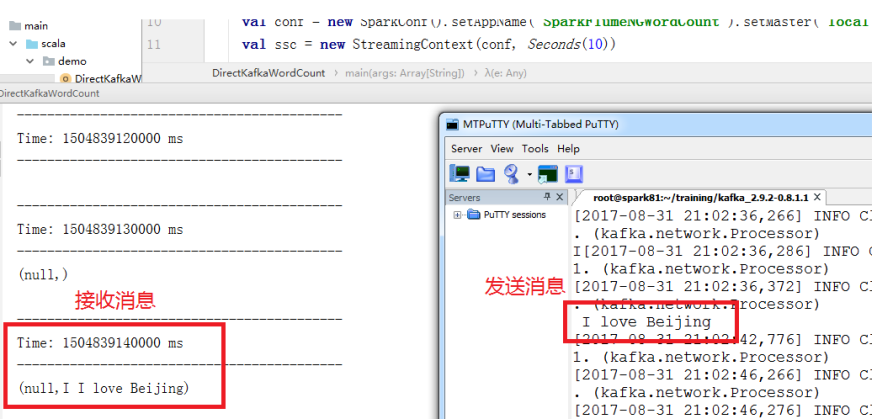
四、性能优化
1、减少批数据的执行时间
在Spark中有几个优化可以减少批处理的时间:
① 数据接收的并行水平
通过网络(如kafka,flume,socket等)接收数据需要这些数据反序列化并被保存到Spark中。如果数据接收成为系统的瓶颈,就要考虑并行地接收数据。注意,每个输入DStream创建一个receiver(运行在worker机器上)接收单个数据流。创建多个输入DStream并配置它们可以从源中接收不同分区的数据流,从而实现多数据流接收。例如,接收两个topic数据的单个输入DStream可以被切分为两个kafka输入流,每个接收一个topic。这将在两个worker上运行两个receiver,因此允许数据并行接收,提高整体的吞吐量。多个DStream可以被合并生成单个DStream,这样运用在单个输入DStream的transformation操作可以运用在合并的DStream上。
② 数据处理的并行水平
如果运行在计算stage上的并发任务数不足够大,就不会充分利用集群的资源。默认的并发任务数通过配置属性来确定spark.default.parallelism。
③ 数据序列化
可以通过改变序列化格式来减少数据序列化的开销。在流式传输的情况下,有两种类型的数据会被序列化:
输入数据
由流操作生成的持久RDD
在上述两种情况下,使用Kryo序列化格式可以减少CPU和内存开销。
2、设置正确的批容量
为了Spark Streaming应用程序能够在集群中稳定运行,系统应该能够以足够的速度处理接收的数据(即处理速度应该大于或等于接收数据的速度)。这可以通过流的网络UI观察得到。批处理时间应该小于批间隔时间。
根据流计算的性质,批间隔时间可能显著的影响数据处理速率,这个速率可以通过应用程序维持。可以考虑WordCountNetwork这个例子,对于一个特定的数据处理速率,系统可能可以每2秒打印一次单词计数(批间隔时间为2秒),但无法每500毫秒打印一次单词计数。所以,为了在生产环境中维持期望的数据处理速率,就应该设置合适的批间隔时间(即批数据的容量)。
找出正确的批容量的一个好的办法是用一个保守的批间隔时间(5-10,秒)和低数据速率来测试你的应用程序。
3、内存调优
在这一节,我们重点介绍几个强烈推荐的自定义选项,它们可以减少Spark Streaming应用程序垃圾回收的相关暂停,获得更稳定的批处理时间。
Default persistence level of DStreams:和RDDs不同的是,默认的持久化级别是序列化数据到内存中(DStream是StorageLevel.MEMORY_ONLY_SER,RDD是StorageLevel.MEMORY_ONLY)。即使保存数据为序列化形态会增加序列化/反序列化的开销,但是可以明显的减少垃圾回收的暂停。
Clearing persistent RDDs:默认情况下,通过Spark内置策略(LUR),Spark Streaming生成的持久化RDD将会从内存中清理掉。如果spark.cleaner.ttl已经设置了,比这个时间存在更老的持久化RDD将会被定时的清理掉。正如前面提到的那样,这个值需要根据Spark Streaming应用程序的操作小心设置。然而,可以设置配置选项spark.streaming.unpersist为true来更智能的去持久化(unpersist)RDD。这个配置使系统找出那些不需要经常保有的RDD,然后去持久化它们。这可以减少Spark RDD的内存使用,也可能改善垃圾回收的行为。
Concurrent garbage collector:使用并发的标记-清除垃圾回收可以进一步减少垃圾回收的暂停时间。尽管并发的垃圾回收会减少系统的整体吞吐量,但是仍然推荐使用它以获得更稳定的批处理时间。