背景
从Spark 1.0开始,Spark SQL成为Spark生态系统一员,是专门处理结构化数据(比如DB, Json)的Spark组件。它提供了2种操作数据的方式:1)SQL Queries;2)DataFrames/Datasets API。Spark SQL = Schema + RDD,RDD可以表达所有的数据格式(包括结构化和非结构化),
Spark SQL只表达结构化的数据。
Spark SQL可以更快地编写和运行Spark程序,它可以编写更少的代码,读取更少的数据,让优化器自动优化程序,释放程序员的工作。
Spark SQL架构
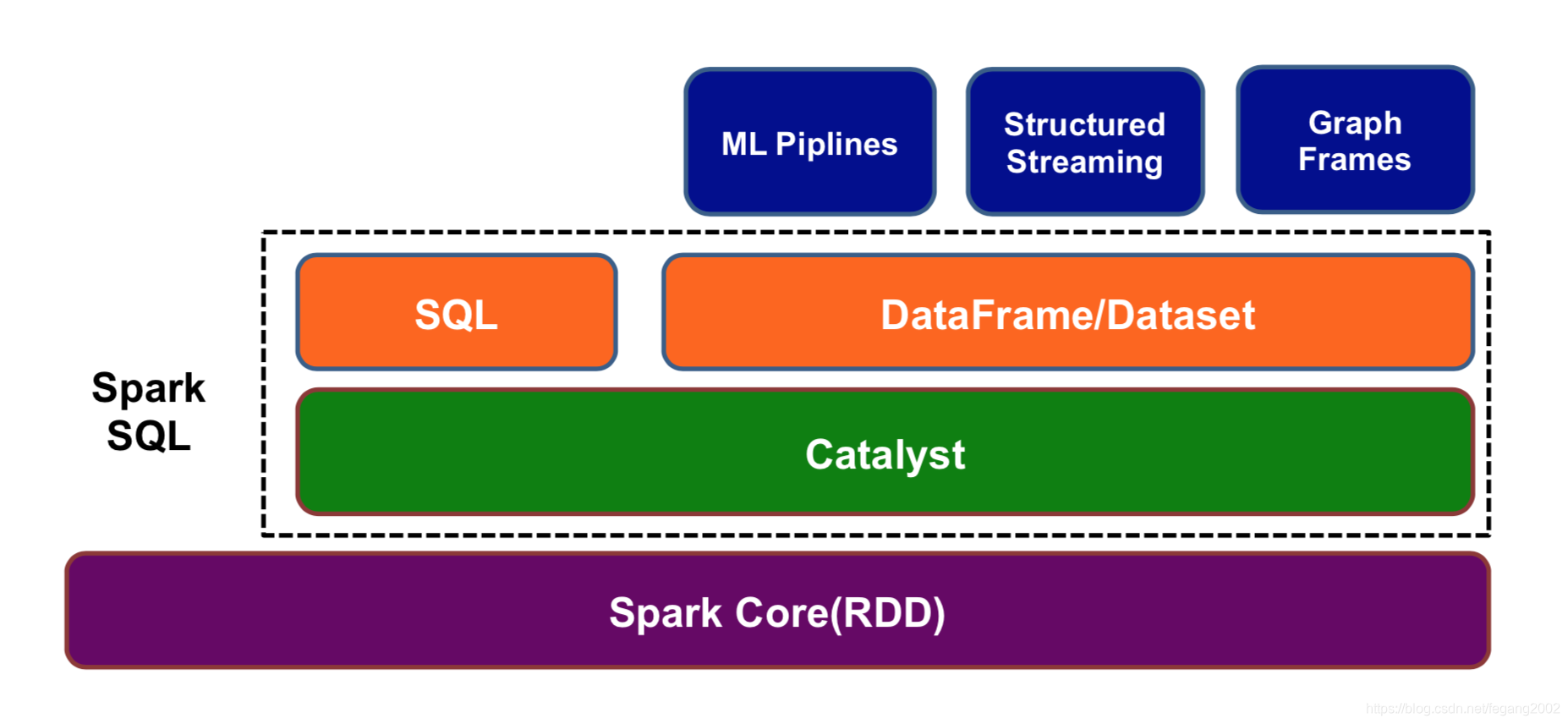 Catalyst是一个查询优化器,将SQL优化为分布式基于RDD应用程序提交到集群。
Catalyst是一个查询优化器,将SQL优化为分布式基于RDD应用程序提交到集群。
Spark SQL支持以下两种方式:
- 使用SQL
使用SQL语法; - 使用DataFrame/Dataset
采用更通用的语言(Scala,Python)表达查询需求,使用Dataset可以更快的捕获错误。
DataFrame 与 Dataset
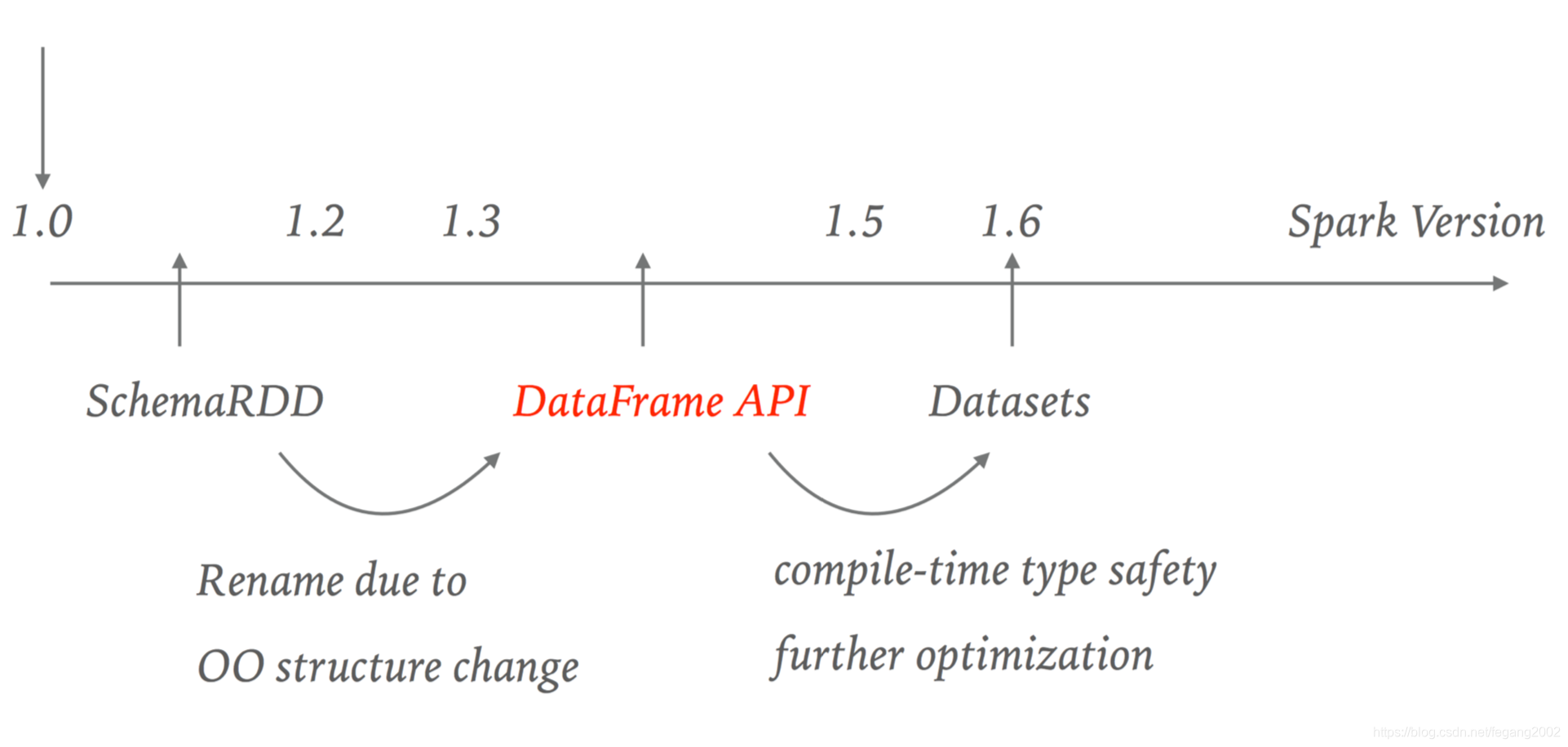
Spark SQL API的演化
-
RDD API
RDD API产生与2011年,是由JVM对象组成的分布式数据集合,它不可变且具有容错能力,可处理结构化与非结构化数据,属于函数式转换。
大数据分布式理念:
1)不可改变,有助于并行计算,不需要加锁,例如RDD如果要改变,必须通过Transformation变为新的RDD;
2)数据提前切分,例如HDFS划分为Blog,HBase划分为Region,Spark划分为RDD。但是RDD没有Schema,用户自己优化程序,不容易优化,同时从不同的数据源读取数据非常困难,合并多个数据源中的数据也非常困难。
-
DataFrame API
DataFrame API产生于2013年,是由Row对象组成的分布式数据集合,它不可变且具有容错能力,只能处理结构化数据,自带优化器Catalyst,可自动优化程序。使用Data source API可以方便的操作HBase,MySQL,HDFS等数据源。DataFrame API运行时类型检查,效率比较低,编译时类型检查效率会高些;它不能直接操作Domain对象;属于函数式编程风格。
-
Dataset API
Dataset扩展自DataFrame API,提供了编译时类型检查,是属于面
向对象编程风格的API。Dataset API可直接作用在Domain对象上,保证了类型安全;代码生成编解码器,序列化更高效;Dataset与Dataframe可相互转换。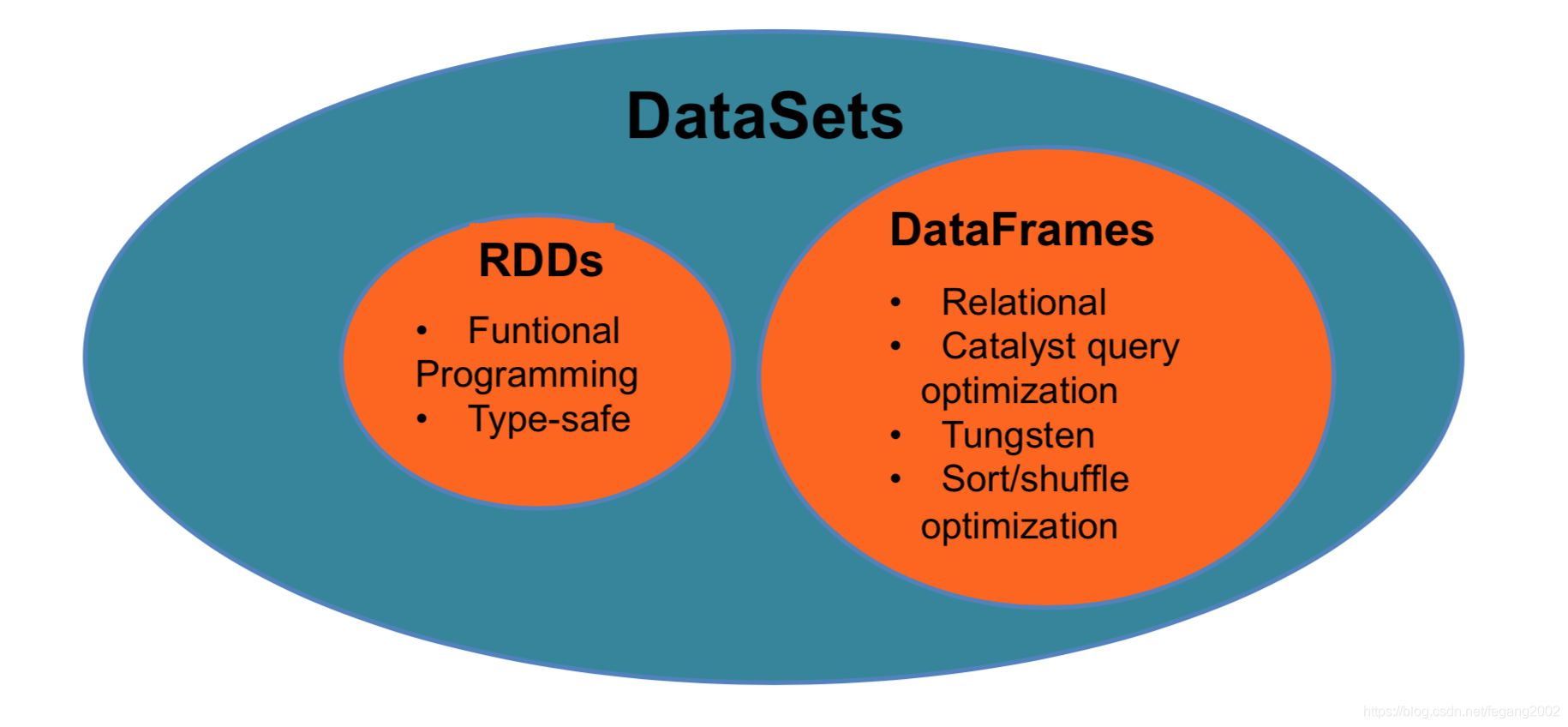 DataFrame = Dataset[Row],Row表示一行数据,比如Row=[“a”,12,123]。DataFrame内部数据无类型,统一为Row,DataFrame是一种特殊类型的Dataset。Dataset内部数据有类型,需要由用户定义。RDD、DataFrame与Dataset之间可以相互转化。扫描二维码关注公众号,回复: 5095300 查看本文章
DataFrame = Dataset[Row],Row表示一行数据,比如Row=[“a”,12,123]。DataFrame内部数据无类型,统一为Row,DataFrame是一种特殊类型的Dataset。Dataset内部数据有类型,需要由用户定义。RDD、DataFrame与Dataset之间可以相互转化。扫描二维码关注公众号,回复: 5095300 查看本文章
RDD、DataFrame与Dataset的关系
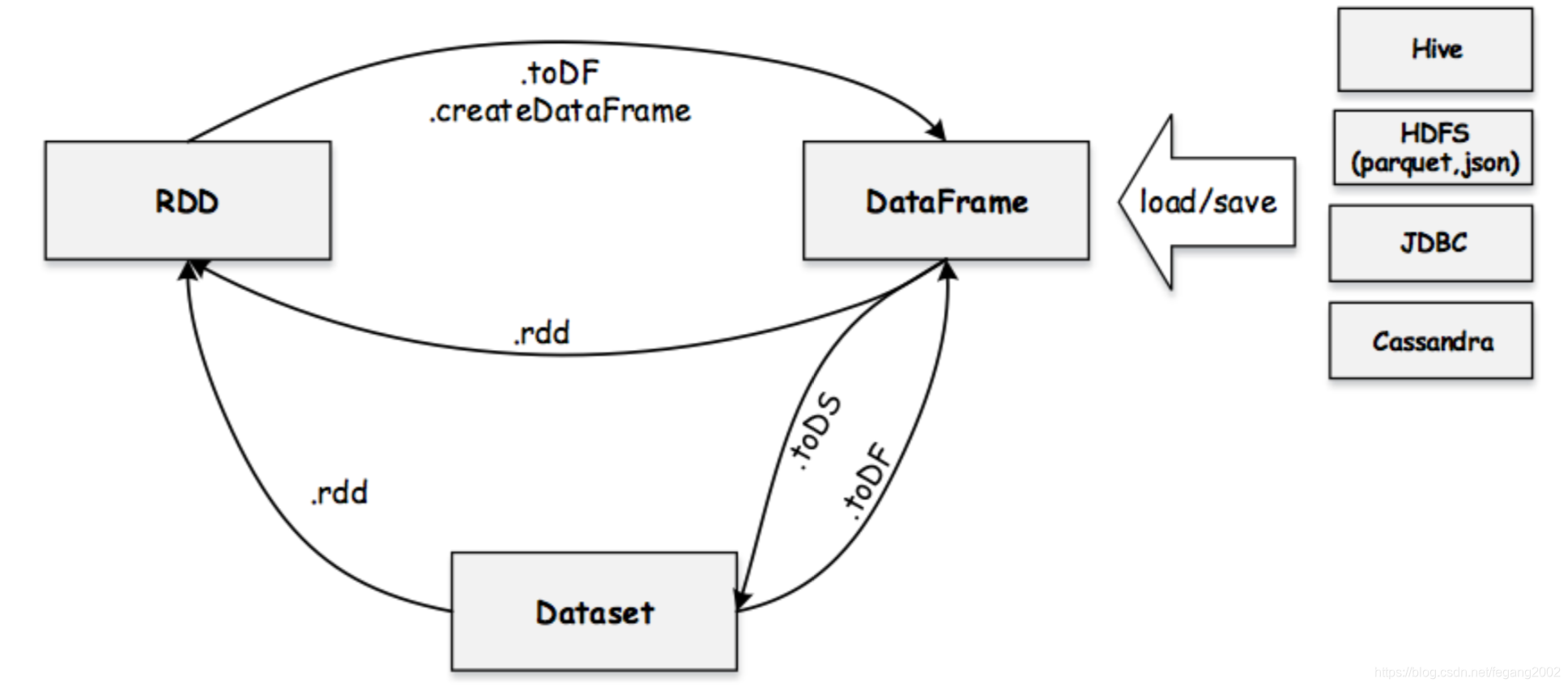
val df = spark.read.parquet(“...”) // DataFrame
val ds = df.as[Person] // DataFrame -> Dataset
val df2 = ds.toDF() / Dataset -> DataFrame
val rdd1 = ds.rdd // Dataset -> RDD
val rdd2 = df.rdd // DataFrame -> RDD
val newDs = Seq(Person(“Andy”, 32)).toDS() // Seq -> DS
Spark SQL程序设计
编写流程
1)创建SparkSession对象:
封装了Spark SQL执行环境信息,是所有Spark SQL程序的唯一入口;
val spark = SparkSession.builder.
master("local")
.appName("Spark Session Example")
.getOrCreate() //如果有就取,如果没有就创建,保证只有一个session,这段代码在任何地方都可以使用
// 后面所有程序片段总的Spark变量均是SparkSession
// 将RDD隐式转换为DataFrame
import spark.implicits._
SparkSession里默认包含一个Spark Context,可以使用SparkSession.sparkContext直接使用,再创建Spark Context会报错。
Spark SQL也是跑在Yarn上,运行在Driver和Executor上,只是换了一种API。运行在Yarn上要用Spark.submit,Spark SQL程序和普通的Spark程序是一样的,都是用Spark.submit提交Yarn运行,运行在Yarn上必须打成JAR包来提交运行。
2)创建DataFrame或Dataset:
Spark SQL支持各种数据源;

-
RDD
通过反射方式:
定义case class,作为RDD的schema,直接通过RDD.toDF将RDD转换为DataFrame。case class是Scala中的一个类,相当于C语言中的一个Structure。import org.apache.spark.sql.SparkSession import org.apache.spark.sql.Row case class User(userID: Long, gender: String, age: Int, occupation: String, zipcode: String) val usersRdd = sc.textFile("/tmp/ml-1m/users.dat") val userRDD = usersRdd.map(_.split("::")).map(p => User(p(0).toLong, p(1).trim, p(2).toInt, p(3), p(4))) val userDataFrame = userRDD.toDF() userDataFrame.take(10) userDataFrame.count()通过自定义schema方式 :
定义RDD schema(由StructField/StructType构成) ,使用SQLContext.createDataFrame生成DF。import org.apache.spark.sql.{SaveMode, SparkSession, Row} import org.apache.spark.sql.types.{StringType, StructField, StructType} val schemaString = "userID gender age occupation zipcode" val schema = StructType(schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, true))) //true说明可以为Null val userRDD2 = usersRdd.map(_.split("::")).map(p => Row(p(0), p(1).trim, p(2).trim, p(3).trim, p(4).trim)) val userDataFrame2 = sqlContext.createDataFrame(userRDD2, schema) userDataFrame2.take(10) userDataFrame2.count() userDataFrame2.write.mode(SaveMode.Overwrite).json("/tmp/user.json") userDataFrame2.write.mode(SaveMode.Overwrite).parquet("/tmp/user.parquet") -
Json
spark.read.format(“json”).load(…)val userJsonDF = spark.read.format("json").load("/tmp/user.json") userJsonDF.take(10)sqlContext.read.json(…)2. sqlContext.read.json(…)
val userJsonDF2 = spark.read.json("/tmp/user.json") userJsonDF2.take(10)SQL
CREATE TABLE user USING json OPTIONS (path “/tmp/user.json”) -
ORC
ratingsRdd=sc.textFile("/tmp/ratings.dat") ratingsRdd.take(2) case class Rating(userId: String, movieId: String, rating: String, timestamp: String) val ratingRDD = ratingsRdd.map(_.split("::")).map(p => Rating(p(0),p(1),p(2),p(3))) ratingRDD.take(2) val ratingDataFrame = ratingRDD.toDF() ratingDataFrame.show //打印前20行数据 ratingDataFrame.printSchema //打印schema ratingDataFrame.write.orc("/tmp/ratings.orc") //创建ORC文件 val newORC = spark.read.orc("/tmp/ratings.orc") //读取ORC文件 newORC.show //打印前20行数据创建ORC文件有些慢,运行成功后,目录下会自动建立四个文件,两个.开头的文件是隐藏文件,里面是校验码,一个_SUCCESS的空文件,所有通过程序产生的目录,都会产生这个文件,标识创建成功,可以通过程序监听目录下是否有_SUCCESS的文件来判断程序是否运行成功。RDD很难读ORC,需要用Spark SQL读ORC。
-
Parquet
Parquet和ORC数据类似,这里的spark是spark session。
spark.read.format(”parquet").load(…)val userParquetDF = spark.read.format("parquet").load("/tmp/user.parquet") userParquetDF.take(10)spark.read.parquet(…)
val userParquetDF2 = spark.read.parquet("/tmp/user.parquet") userParquetDF2.take(10)SQL
CREATE TABLE user USING parquet OPTIONS (path=“/tmp/user.parquet”) -
Jdbc
spark.read.format(“jdbc”).options(…)export SPARK_CLASSPATH=<mysql-connector-java-5.1.26.jar> val jdbcDF = spark.read.format("jdbc").options( Map( “url” -> “jdbc:mysql://mysql_hostname:mysql_port/testDB?user=<name>&password=<password>" , "dbtable" -> “testTable")).load()SQL
CREATE TABLE user USING jdbc OPTIONS (url=“jdbc:mysql://mysql_hostname:mysql_port/testDB?user=<name>&password=<passw ord>",dbtable=“testTable”)
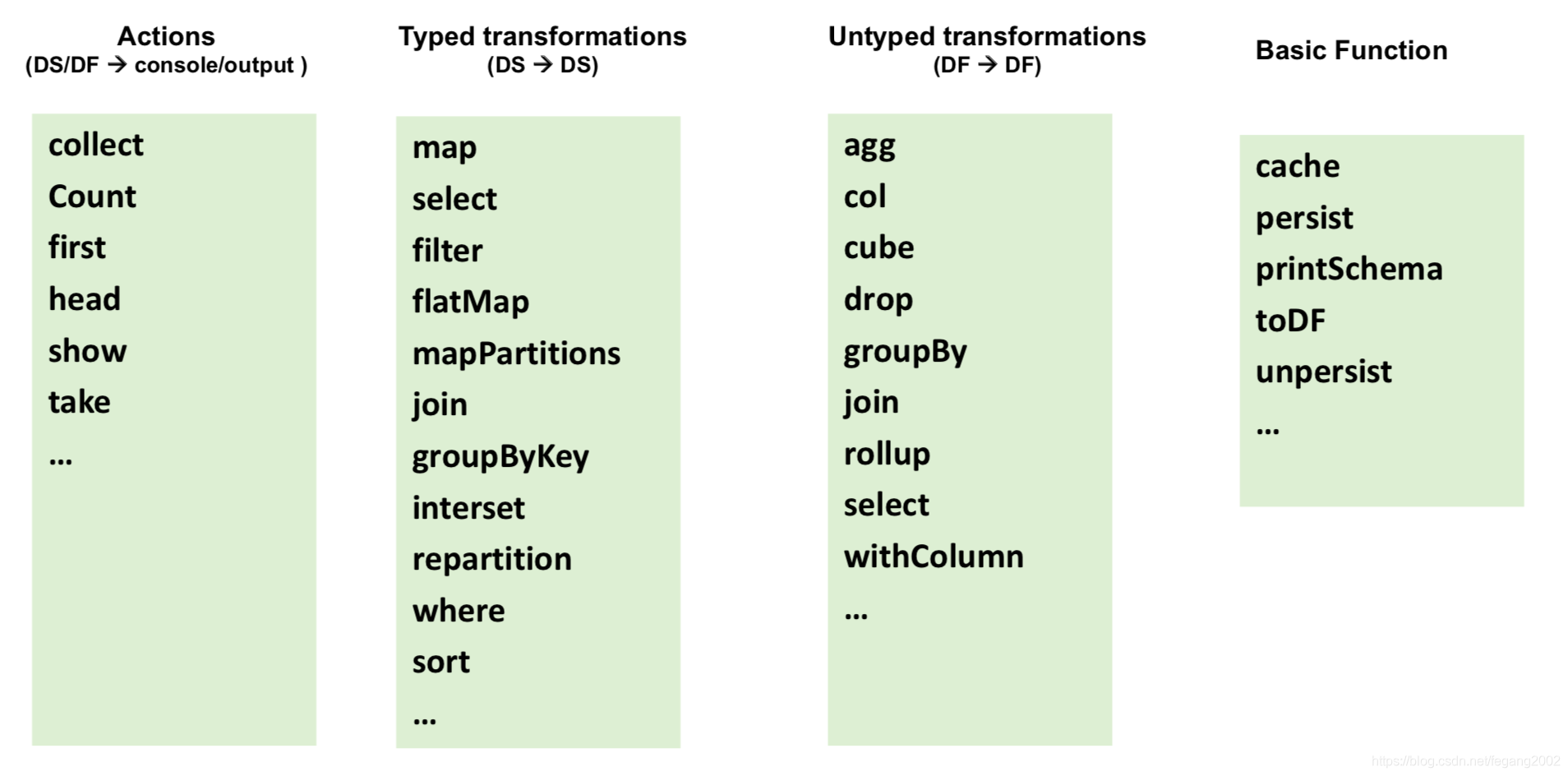
3)在DataFrame或Dataset之上进行转换和Action:
Spark SQL提供了多种转换和Action函数;有类型的转换针对Dataset
没有类型的转换针对DataFrame。
 数据处理
数据处理
Json数据
{"age":"45","gender":"M","occupation":"7","userID":"4","zipcode":"02460"}{"age":"1","gender":"F","occupation":"10","userID":"1","zipcode":"48067"}
读取Json数据
scala> val userDF = spark.read.json("/tmp/user.json")
userDF: org.apache.spark.sql.DataFrame = [age: string, gender: string, occupation: string, userID: string, zipcode: string]
生成Json数据
scala> userDF.limit(5).write.mode("overwrite").json("/tmp/user2.json")
collect用数组的方式返回所有的值;
spark.read.textfile可以返回Dataset;
spark.read.text可以返回DataFrame。
DataFrame处理
scala> userDF.show(4)

scala> userDF.limit(2).toJSON.foreach(println)
{"age":"1","gender":"F","occupation":"10","userID":"1","zipcode":"48067"}
{"age":"56","gender":"M","occupation":"16","userID":"2","zipcode":"70072"}`
scala> userDF.printSchema
root
|-- age: string (nullable = true)
|-- gender: string (nullable = true)
|-- occupation: string (nullable = true) |-- userID: string (nullable = true)
|-- zipcode: string (nullable = true)
Transformation
scala> userDF.select("userID", "age").show

scala> userDF.selectExpr("userID", "ceil(age/10) as newAge").show(2)

scala> userDF.select(max('age), min('age), avg('age)).show

scala> userDF.selectExpr(”userID as id", "case gender when 'F' then 'female' else 'male' end as gender").show

scala> userDF.filter(userDF("age") > 30).show(2)

scala> userDF.filter("age > 30 and occupation = 10").show

scala> userDF.select("userID", "age").filter("age > 30").show(2)

scala> userDF.filter("age > 30").select("userID", "age").show(2)
 以上两个结果和效率都一样。
以上两个结果和效率都一样。
scala> userDF.groupBy("age").count().show()

scala>userDF.groupBy("age").agg(count('gender),countDistinct('occupation)).show()

scala>userDF.groupBy("age").agg("gender"->"count","occupation"->"count").show()
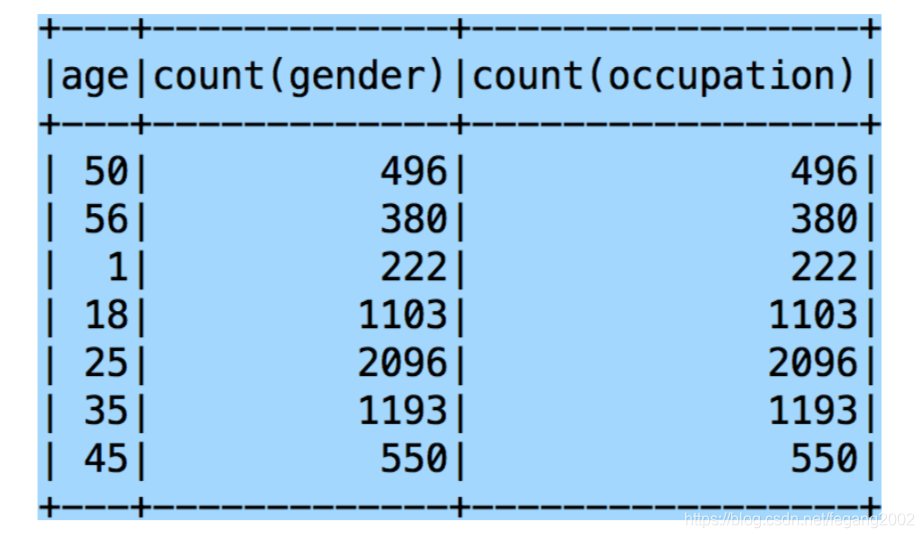 可用的聚集函数: avg, max, min, sum, count
可用的聚集函数: avg, max, min, sum, count
scala> userDataFrame.printSchema
root
|-- userID: string (nullable = true)
|-- gender: string (nullable = true)
|-- age: string (nullable = true)
|-- occupation: string (nullable = true)
|-- zipcode: string (nullable = true)
scala> ratingDataFrame.printSchema
root
|-- userID: string (nullable = true)
|-- movieID: string (nullable = true)
|-- Rating: string (nullable = true)
|-- Timestamp: string (nullable = true)
scala> val mergedDataFrame = ratingDataFrame.filter("movieID = 2116").
| join(userDataFrame, "userID").
| select("gender", "age").
| groupBy("gender", "age").
| count
mergedDataFrame: org.apache.spark.sql.DataFrame = [gender: string, age: string, count: bigint]
scala> val mergedDataFrame2 = ratingDataFrame.filter("movieID = 2116"). join(userDataFrame, userDataFrame("userID") === ratingDataFrame("userID"),
"inner").select("gender", "age"). groupBy("gender", "age").count
scala> mergedDataFrame2.show
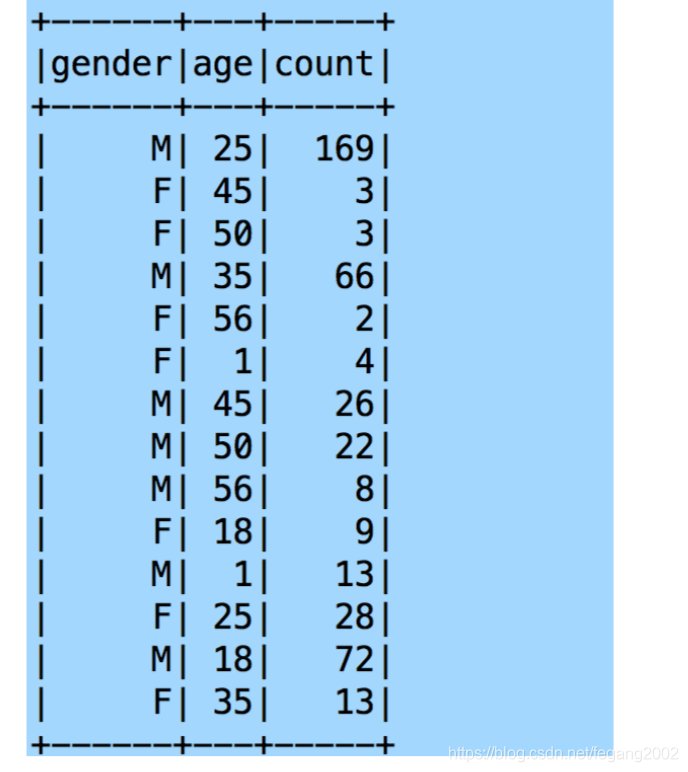 Spark SQL支持的Join类型: inner, outer, full, fullouter, leftouter, rightouter, cross
Spark SQL支持的Join类型: inner, outer, full, fullouter, leftouter, rightouter, cross
scala> userDataFrame.createOrReplaceTempView("users")
val groupedUsers = spark.sql("select gender, age, count(*) as n from users group by gender, age")
groupedUsers.show()
 SQL返回的是Dataframe。
SQL返回的是Dataframe。
Dataframe.show()返回的是unit,是空,相当于void。
Dataframe.take()返回的是一个数组,所以要把一个Dataframe的某几条记录存储下来应该用take,不能用show。
Action
scala> userDF.collect
res35: Array[org.apache.spark.sql.Row] = Array([1,F,10,1,48067], [56,M,16,2,70072], [25,M,15,3,55117], [45,M,7,4,02460], [25,M,20,5,55455])
scala> userDF.first
res36: org.apache.spark.sql.Row = [1,F,10,1,48067]
scala> userDF.take(2)
res37: Array[org.apache.spark.sql.Row] = Array([1,F,10,1,48067], [56,M,16,2,70072])
scala> userDF.head(2)
res38: Array[org.apache.spark.sql.Row] = Array([1,F,10,1,48067], [56,M,16,2,70072])
4)返回结果:
保存到HDFS中,或直接打印出来。
参考链接
https://spark-packages.org/
http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.Dataset
http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.sql.Column