Spark 是什么
Spark 是一个平台。这个平台用来实现快速而通用的集群计算。
在速度方面,Spark 扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模
式,包括交互式查询和流处理。在处理大规模数据集时,速度是非常重要的。速度快就意
味着我们可以进行交互式的数据操作,否则我们每次操作就需要等待数分钟甚至数小时。
Spark 的一个主要特点就是能够在内存中进行计算,因而更快。不过即使是必须在磁盘上
进行的复杂计算,Spark 依然比 MapReduce 更加高效
Spark 的核心是一个计算引擎。这个引擎对应用进行调度、分发以及监控。这些应用由很多计算任务组成、运行在多个工作机器或者是一个计算集群上。
Spark 的各个组件:

Spark Core 实现了 Spark 的基本功能。包含任务调度、内存管理、错误恢复、与存储系统交互等模块。Spark Core 中还包含了对弹性分布式数据集(resilient distributed dataset,简称 RDD)的 API 定义。
RDD 表示分布在多个计算节点上,可以并行操作,的元素集合,是Spark 主要的编程抽象。Spark Core 提供了创建和操作这些集合的多个 API。
通过 Spark SQL,我们可以使用 SQL或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。
生产环境中的网页服务器日志,或是网络服务中用户提交的状态更新组成的消息队列,都是数据流。Spark Streaming 提供了用来操作数据流的 API,并且与 Spark Core 中的 RDD API 高度对应。
MLlib 提供了很多种机器学习算法,包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
***GraphX***实现针对图的各种操作。
Spark 不仅可以将任何 Hadoop 分布式文件系统(HDFS)上的文件读取为分布式数据集,也可以支持其他支持 Hadoop 接口的系统,比如本地文件、亚马逊 S3、Cassandra、Hive、HBase 等。我们需要弄清楚是,Hadoop 并非 Spark 的必要条件,Spark 支持任何实现了 Hadoop 接口的存储系统。
Spark 支持的 Hadoop 输入格式包括文本文件、SequenceFile、Avro、Parquet 等。
Spark 可以运行在许多种模式下,除了本地模式,还支持运行在Mesos 或 YARN 上,也可以运行在 Spark 发行版自带的独立调度器上。
Spark shell
Spark 带有交互式的 shell,可以作即时数据分析。和其他 shell 工具不一样的是,在其他 shell 工具中你只能使用单机的硬盘和内存来操作数据,而 Spark shell 可用来与分布式存储在许多机器的内存或者硬盘上的数据进行交互,并且处理过程的分发由 Spark 自动控制完成。
打开shell:
bin/pyspark : python版本的shell
bin/spark-shell : Scala版本的shell
shell 交互界面消息很多。通过管理日志来设置warning 消息的显示。
在 conf 目录下创建一个名为 log4j.properties 的文件来管理日志设置。
将log4j.properties.template文件复制一份到 conf/log4j.properties 来作为日志设置文件,
修改文件中:
log4j.rootCategory=INFO, console
为
log4j.rootCategory=WARN, console
这时再打开 shell,你就会看到输出大大减少。
---------------------若需要使用ipython来交互--------------------------
安装IPYTHON
IPYTHON=1 ./bin/pyspark
要使用 IPython Notebook,也就是 Web 版的 IPython,可以运行:
IPYTHON_OPTS=“notebook” ./bin/pyspark
要退出任一 shell,按 Ctrl-D
Spark 运行方式
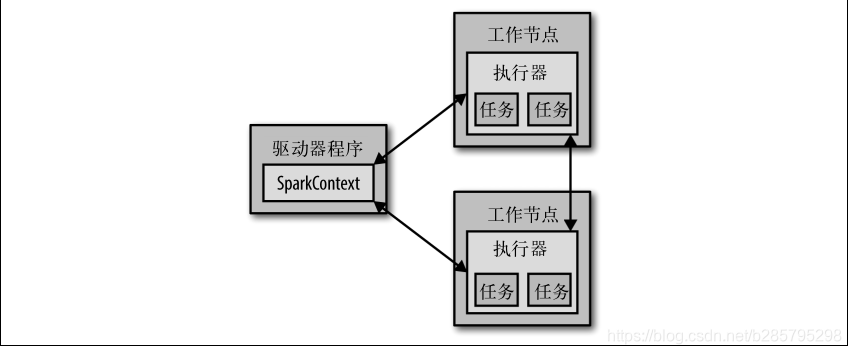
每个 Spark 应用都由一个驱动器程序(driver program)来发起集群上的各种并行操作。
比如打开一个shell,此时shell就相当于一个driver program。驱动器程序一般要管理多个执行器(executor)节点,这些节点执行运算。
驱动器程序通过一个 SparkContext 对象来访问 Spark。
 一旦有了 SparkContext,你就可以用它来创建 一系列RDD。
一旦有了 SparkContext,你就可以用它来创建 一系列RDD。
会有很多用来传递函数的 API,可以将对应操作运行在集群上。
除了交互式运行之外,Spark 也可以在 Java、Scala 或 Python 的独立程序中被连接使用。这与在 shell 中使用
的主要区别在于你需要自行初始化 SparkContext。接下来,使用的 API 就一样了。
应用与spark连接
连接 Spark 的过程在各语言中并不一样。在 Java 和 Scala 中,只需要给你的应用添加一个对于 spark-core 工件的 Maven 依赖。
在 Python 中, 你 可 以 把 应 用 写 成 Python 脚 本, 但 是 需 要 使 用 Spark 自 带 的 bin/spark-submit 脚本来运行。 spark-submit 脚本会帮我们引入 Python 程序的 Spark 依赖。这个脚本为 Spark 的 PythonAPI 配置好了运行环境。
bin/spark-submit my_script.py
初始化 SparkContext
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)
至少传递两个参数:
• 集群 URL:告诉 Spark 如何连接到集群上。 local 这个特殊值可以让 Spark 运行在单机单线程上而无需连接到集群。
• 应用名:如My App 。当连接到一个集群时,这个值可以帮助你在集群管理器的用户界面中找到你的应用。