起因:
我们实验室是搞分布式计算的,所以我的目光就着落在了几个大数据框架上:Spark, Storm, Flink等等。从中挑了了一个比较好做的就是spark了,目前还是基础知识掌握阶段,下周可能会定题目,看老师想法。这几篇博客完全由主观撰写,根据自己的想法觉得怎么思考顺利怎么写,如果对您有一点点帮助那太好了,没有的话就权当自己练手。
首先说Google的三大马车:Mapreduce,GFS,Bigtable,为分布式科技的发展迈上了新的台阶。其中mapreduce就是一个为分布式服务的很好的处理思想,并应用到Hadoop中成为重要的分布式计算一环。由此加州大学伯克利分校的AMP研究室以mapreduce为出发点改进并创建了新一代大数据框架Spark,并于2013年成为Apache的顶级项目,一步一步走向成熟成为现在应用很广的处理框架。
与Hadoop相比,Spark的最大特点是基于内存运算并引入DAG(有向无环图)执行引擎。其中第一个是对Map reduce的重大改进,中间数据压缩保存到内存,运算时间会比磁盘低两个数量级。第二个是对RDD的建模,描述了RDD之间的依赖关系。
Spark生态系统是以Spark core为核心提供计算框架,Spark streaming实时处理数据流,进行高吞吐高容错的流式处理,可同时进行批处理和流处理,Spark SQL即席查询,MLlib的机器学习和GraphX的图像处理,而且Spark的适应性很强,能读取很多框架的原生数据(归功于RDD)。
所以正式因为Spark的速度快(虽然没有Storm他们快),容错性高,可拓展性强,迅速取代了上一代大数据框架Hadoop而成为新的大数据处理框架。
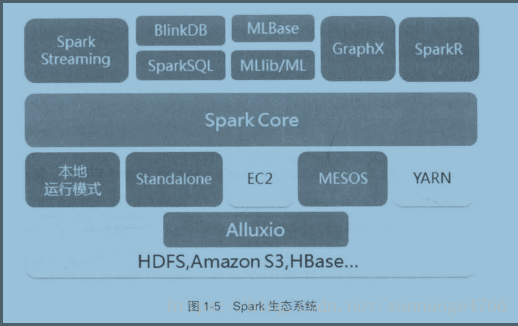
Spark应用Scala语言编程,其余的各个组成部分与实际应用以后再慢慢学习。