一、Spark中的一些专业术语
任务:
- Application:用户写的应用程序,包括Driver Program和Executor Program。
- Job:一个action类算子触发执行的操作。
- stage:一组任务(task)就是一个stage。
- task:(thread)在集群中运行时最小的执行单元。
资源、集群:
- Master:资源管理的主节点。
- Worker:资源管理的从节点。
- Executor:执行任务的进程。
- ThreadPool:线程池,存在于Executor进程中。
二、RDD的宽窄依赖关系
1、窄依赖
父RDD与子RDD,partition之间的关系是一对一,那么父子RDD的依赖关系就称之为窄依赖,这种依赖关系不存在shuffle过程。

2、宽依赖
父RDD与子RDD,partition之间的关系是一对多,那么父子RDD的依赖关系就称之为宽依赖,这种依赖关系存在shuffle过程。
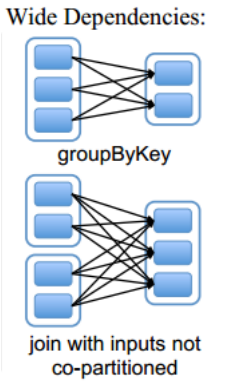
默认情况下,groupByKey返回的RDD分区数与父RDD是一致的,如果在使用groupByKey的时候,传入一个int类型的值,此时返回的RDD分区数就是这个int值。
总结:
- 父RDD不知道有几个子RDD,但子RDD知道他的父RDD有几个。基于此特点,形成一个DAG有向无环图需要从后往前回溯。
- 宽窄依赖的作用就是为了将一个个的job切割成一个个的stage
三、Stage切割规则
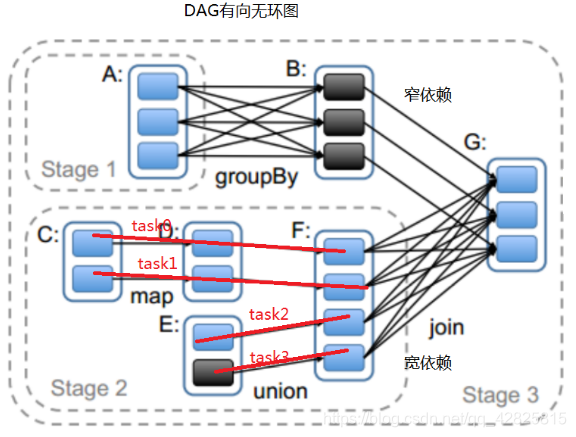
上图是将job切割成Stage的过程。
总结:
- 切割后的结果是stage与stage之间是宽依赖,stage之间是窄依赖。
- 将job切割成stage的目的?stage与stage之间有shuffle,stage内部无shuffle。
- RDD中实际上存储的是计算逻辑,而不是真实的数据。
Stage计算模式:
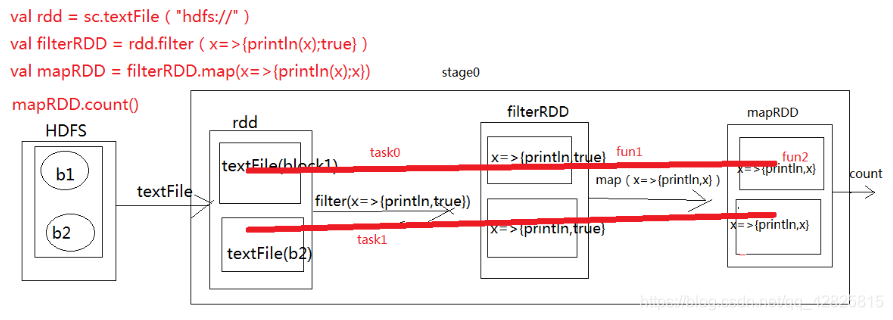
task0这条线所贯穿所有的的partition中的计算逻辑,并且以递归函数展开式的形式整合在一起,fun2(fun1(textFile(b1))),最好发送到b1以及他副本所在的节点。
task1:fun2(fun1(textFile(b1)))最好发送到b2以及他副本所在的节点。
task的计算模式是pipeline的计算模式,管道计算。
总结:
MapReduce的计算模式是1+1=2,2+1=3,会有数据落地,Spark的计算模式是1+1+1=3,不会有数据落地的情况。
四、任务调度
Spark是一个分布式并行计算框架。我们写的Application要在集群中分布式计算,由于大数据中的计算原则是计算找数据,为了将每一个task精准的分发到节点上,此时需要任务调度器,找到数据的位置,从而分发task到节点上。
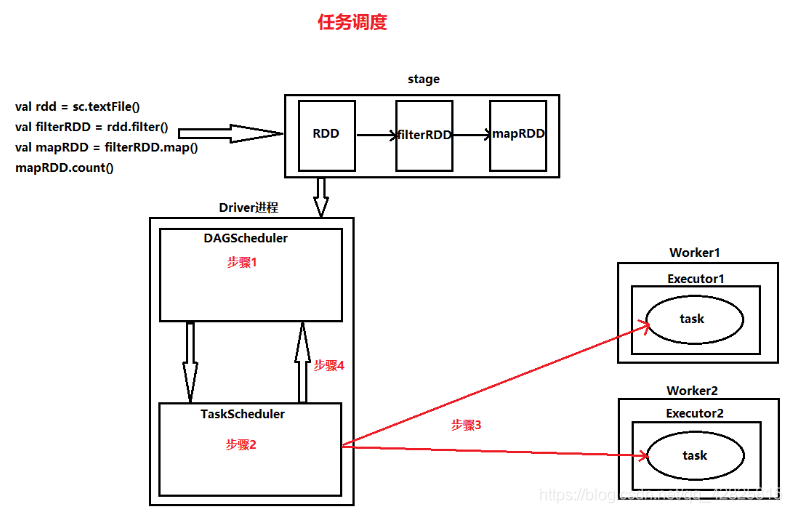
任务调度过程:
首先根据代码生成DAG有向无环图,然后将有向无环图交给DAGScheduler:
- 步骤一:根据RDD的宽窄依赖关系,将DAG切割成一个个的stage,将切割出来的stage封装到TaskSet对象中,然后将一个个的TaskSet给TaskScheduler;
- 步骤二:TaskScheduler拿到TaskSet以后,会遍历这个结果,拿到每一个task,然后去调用HDFS上的某一个方法,获取数据的位置,根据数据的位置来分发task到Woker节点的Executor进程中的线程池中执行;
- 步骤三:TaskScheduler会实时跟踪每一个task的执行情况,若执行失败,TaskScheduler会重试提交task,不会无休止的重试,默认是重试3次,如果重试3次依旧失败,那么这个task所在stage就失败了,此时TS向DAGScheduler汇报;
- 步骤四:TaskScheduler向DAGScheduler汇报当前stage失败,此时DAGScheduler会重试提交stage。注意:每一次重试提交的stage,已经成功执行的不会被再次分发到Executor进程执行,只是提交重试失败的。
- 如果DAGScheduler重试了4次依然失败,那么stage所在的job就失败了,job失败是不会进行重试的。DAGScheduler重试次数spark.stage.maxConsecutiveAttempts可设置。
TaskScheduler:retry failed or straggling tasks。当有挣扎(掉队)任务时,也会重试。
挣扎(掉队)任务:
比如10000个task中,有9999个执行完成,只有一个task正在执行,那么这个任务就叫挣扎任务。
TaskScheduler遇到挣扎任务也会重试,此时TaskScheduler会重新提交一个和挣扎task一模一样的task到集群中运行,但是挣扎task不会被kill,会让他俩在集群中比赛执行,谁先执行完毕,就以谁的结果为准。
推测执行机制:用来判断哪些task是挣扎task。
推测执行机制的标准:当所有的task75%以上全部执行完毕,那么TasredkScheduler才会每隔100ms计算一下哪一些task需要推测执行。
例如:100个task中有76个task已执行完毕,24个task没有执行完毕,此时他会计算这24个task已经执行时间的中位数,然后将中位数*1.5得到最终时间,拿到这个最终计算出来的时间,去查看哪一些task超时,此时这些task就是挣扎task。
配置信息的使用:
- 在代码中SparkConf
- 在提交Application的时候通过–conf来设置(spark-submit
–master --conf k=v),如果要修改多个配置信息的值,那么需要加多个–conf比如说stage、task的重试次数都要修改,此时需要加上两个–conf,分别来设置。(常用) - 在spark的配置文件中配置,spark-default.conf