目录:
3、RDD编程
Spark对数据的核心抽象—弹性分布式数据集(Resilient Distributed Dataset,简称 RDD)。RDD其实就是分布式的元素集合,是一个容错的、并行的数据结构,可以让用户显示的将数据存储到磁盘和内存中,并能控制数据的分区。
在Spark中,对数据的所有操作不外乎创建RDD、转化已有RDD以及调用RDD操作进行求值。同时,Spark会自动将RDD中的数据分发到集群上,并将操作并行化执行。
3.1、RDD基础
Spark中的RDD就是一个不可变的分布式对象集合。每个RDD都被分为多个分区,这些分区运行在集群中的不同节点上。RDD可以包含Python、Java、Scale中任意类型的对象,甚至可以包含用户自定义的对象。
Spark提供了两种方法创建RDD:读取一个外部数据集,或在驱动器程序里分发驱动器程序中的对象集合(比如list和set)。
RDD的特性:
- 它是不变的数据结构存储
- 它是支持跨集群的分布式数据结构
- 可以根据数据记录的key对结构进行分区
- 提供了粗粒度的操作,且这些操作都支持分区
- 它将数据存储在内存中,从而提供了低延迟性
Spark程序或shell会话步骤:
- 从外部数据创建出输入RDD。
- 使用诸如filter()这样的转化操作对RDD进行转化,以定义新的RDD。
- 告诉Spark对需要被重用的中间结果RDD执行persist()操作。
- 使用行动操作(例如count()和first()等)来触发一次并行计算,Spark会对计算进行优化后再执行。
3.2、创建RDD
创建RDD最简单的方式就是把程序中一个已有的集合传给SparkContext的parallelize()方法。适用于开发原型和测试时,这种方式需要把你的整个数据集先放在一台机器的内存中。
1、Java中的parallelize()方法:
JavaRDD<String> lines = sc.parallelize(Arrays.asList(“pandas, “I like pandas”));
更常用的方式是从外部存储中读取数据来创建 RDD。
2、Java中的textFile方法:
JavaRDD(String) lines = sc.textFile(“README.md”);
3.3、RDD操作
RDD支持两种操作:转化操作和行动操作。
RDD的转化操作是返回一个新的RDD的操作,比如map()和filter(),而行动操作则是向驱动器程序返回结果或把结果写入外部系统的操作,会触发实际的计算,比如count()和first()。
其实,转化操作返回的是RDD,而行动操作返回的是其他的数据类型。
3.3.1、转化操作
RDD的转化操作时返回新的RDD的操作。转化出来的RDD是惰性求值的,只有在行动操作中用到这些RDD时才会被计算。许多转化操作都是针对各个元素的,也就是说,这些转化操作每次只会操作RDD中的一个元素。不过并不是所有的转化操作都是这样的。
例如:假定我们有一个日志文件log.txt,内含有若干消息,希望选出其中的错误消息。
1、用Scale实现filter()转化操作:
val inputRDD = sc.textFile(“log.txt”)
val errorRDD = inputRDD.filter(line => line.contains(“error”))2、用Java实现filter()转化操作
JavaRDD<String> inputRDD = sc.textFile(“log.txt”);
JavaRDD<String> errorRDD = inputRDD.filter(new Function<String,Boolean>() {
@Override
public Boolean call(String x) {
return x.contains(“error”);
}
});
3、Java进行union()转化操作
JavaRDD<String> badLinesRDD = errorRDD.union(inputRDD); 通过转化操作,已经从RDD中派生出新的RDD,Spark会使用谱系图(lineage graph)来记录这些不同RDD之间的依赖关系。Spark需要用这些信息来按需要计算每个RDD,也可以依靠谱系图在持久化的RDD丢失部分数据时恢复所丢失的数据。
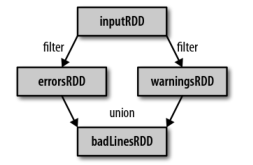
——日志分析过程中创建出的RDD谱系图
3.3.2、行动操作
有时我们还需要对数据集进行实际的计算。行动操作是第二种类型的RDD操作,他们会把最终求得的结果返回到驱动器程序,或者写入外部存储系统中。由于行动操作需要生成实际的输出,他们会强制执行那些求值必须用到的RDD的转换操作。
1、在Scale中使用行动操作对错误进行计数:
println("Input had "+ badLinesRDD.count() + " concerning lines")
println("Here are 10 examples: ")
badLines.take(10).foreach(println)
2、在Java中使用行动操作对错误进行计数:
System.out.println("Input had " + badLinesRDD.count() + "concerning lines");
System.out.println("Here are 10 examples: ")
for(String line : badLinesRDD.take(10)) {
System.out.println(line);
}
在这个例子中,我们在驱动器程序中使用take()获取RDD中的少量元素。然后再本地遍历这些元素,并把驱动器端打印出来。RDD还有一个collect()函数,可以用来获取整个RDD中的数据。只有你的整个数据集能在单台机器的内存中放得下时,才能使用collect(),因此,collect()不能应用在大规模的数据集上。
3.3.3、惰性求值
RDD的转化操作时惰性求值的。这意味着当我们对RDD调用转化操作时,操作是不会立即执行。相反,Spark 会在内部记录下所要求执行的操作的相关信息。我们不应该把 RDD 看作存放着特定数据的数据集,而最好把每个 RDD 当作我们通过转化操作构建出来的、记录如何计算数据的指令列表。
3.4、向Spark传递函数
Spark的大部分转化操作和一部分行动操作,都需要依赖用户传递的函数来计算。在 Java 中,函数需要作为实现了 Spark 的 org.apache.spark.api.java.function 包中的任一函数接口的对象来传递。根据不同的返回类型,我们定义了一些不同的接口。
| 函数名 |
实现的方法 |
用途 |
| Function<T, R> |
R call(T) |
接收一个输入值并返回一个输出值,用于类似map()和filter()等操作中 |
| Function2<T1, T2, R> |
R call(T1, T2) |
接收两个输入值并返回一个输出值,用于类似aggregate()和fold()等操作 |
| FlatMapFunction<T, R> |
Iterator<R> call(T) |
接收一个输入值并返回任意输出,用于类似flatMap()这样的操作 |
可以把我们的函数类内联定义为使用匿名内部类,也可以创建一个具名类。
1、使用匿名内部类进行函数传递
JavaRDD<String> errors = lines.filter(new Function<String, Boolean>() {
public Boolean call(String x) {
return x.contains("error");
}
});
2、使用具名类进行函数传递
class ContainsError implements Function<String, Boolean>() {
public Boolean call(String x) {
return x.contains("error");
}
}
JavaRDD<String> errors = lines.filter(new ContainsError());
3、带参数的Java函数类
class Contains implements Function<String, Boolean>() {
private String query;
public Contains(String query) {
this.query = query;
}
public Boolean call(String x) {
return x.contains(query);
}
}
RDD<String> errors = lines.filter(new Contains("error"));
在Java8中可以使用lambda表达式来简洁地实现函数接口。
4、使用Java8的lambda表达式进行函数传递
JavaRDD<String> errors = lines.filter(s -> s.contains("error"));3.5、常见的转化操作和行动操作
3.5.1、基本RDD
1、针对各个元素的转化操作:
最常用的转化操作时map()和filter()。 转化操作map()接收一个函数,把这个函数用于RDD中的每个元素,将函数的返回结果作为结果RDD中对应元素的值。而转化操作filter()接收一个函数,并将RDD中满足该函数的元素放入新的RDD中返回。

我们可以使用map()来做各种各样的事情:可以把我们的URL集合中的URL对应的主机名提取出来,也可以简单到只对各个数组求平方值。map()的返回值类型不需要和输入类型一样。这样如果有一个字符串RDD,并且我们的map()函数是用来把字符串解析并返回一个Double值的,那么此时我们的输入RDD类型就是RDD[String],而输出类型是RDD[Double]。
1)使用map()计算RDD中各值的平方:
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1,2,3,4));
JavaRDD<Integer> result = rdd.map(new Function<Integer, Integer>(){
@Override
public Integer call(Integer x) throws Exception {
return x*x;
}
});
System.out.println(StringUtils.join(result.collect(),","));
2)使用flatMap()将行数据切分为单词
JavaRDD<String> lines = sc.parallelize(Arrays.asList("hello word","hi"));
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String line) throws Exception {
return Arrays.asList(line.split(" "));
}
});
words.first(); //返回"hello"
3)RDD的flatMap()和map的区别

2、伪集合操作:
RDD中最常缺失的集合属性是元素的唯一性,因为常常有重复的元素。如果只要唯一的元素,我们可以使用RDD.distinc()转化操作来生成一个只包含不同元素的RDD。不过distinct()操作的开销很大,因为它需要将所有的数据经过网络混洗(shuffle),以确保每个元素都只有一份。
最简单的集合操作时union(other),它会返回一个包含两个RDD中的所有元素的RDD。比如在处理来自多个数据源的日志文件很有用。与数学中的union()不同的是,如果输入的RDD中有重复数据,Spark的uniion()操作也会包含这些重复数据。
Spark还提供了intersection(other)方法,只返回两个RDD中都有的元素。intersection()在运行时也会去掉重复的元素(单个RDD内的重复元素也会一起移除)。intersection()需要通过网络混洗数据来发现共有的数据,因此性能吧union()要差很多。
substract(other)函数接收另一个RDD作为参数,返回一个由只存在于第一个RDD中而不存在于第二个RDD中的所有 元素组成的RDD。也需要数据混洗。
cartesian(other)转化操作会返回所有可能的(a,b)对,其中a是源RDD中的元素,而b则来自于另一个RDD。用于计算两个RDD的笛卡尔积。
表3-5-1:对一个数据为{1, 2, 3, 3}的RDD进行基本的RDD转化操作
| 函数名 |
目的 |
示例 |
结果 |
| map() |
将函数应用于RDD中的每个元素,将返回值构成新的RDD |
rdd.map(x => x + 1) |
{2, 3, 4, 4} |
| flatMap() |
将函数应用于RDD中的每个元素,将返回的迭代器的所有内容构成新的RDD。通常用来切分单词 |
rdd.flatMap(x => x.to(3) |
{1, 2, 3, 2, 3, 3, 3} |
| filter() |
返回一个有通过传给filter()的函数的元素组成的RDD |
rdd.filter(x => x != 1) |
{2, 3, 3} |
| distinct() |
去重 |
rdd.distinct() |
{1, 2, 3} |
| sample(withReplacement, fraction, [seed]) |
对RDD采样,以及是否替换 |
rdd.sample(false, 0.5) |
非确定的 |
表3-5-2:对数据分别为{1, 2, 3}和{3, 4, 5}的RDD进行针对两个RDD的转化操作
| 函数名 |
目的 |
示例 |
结果 |
| union() |
生成一个包含两个RDD中的所有元素的RDD |
rdd.union(other) |
{1, 2, 3, 3, 4, 5} |
| intersection() |
求两个RDD共同的元素的RDD |
rdd.intersection(other) |
{3} |
| subtract() |
移除一个RDD中的内容(例如移除训练数据) |
rdd.subtract(other) |
{1, 2} |
| cartesian() |
与另一个RDD的笛卡尔积 |
rdd.cartesian(other) |
{(1, 3) ,(1, 4), …(3, 5)} |
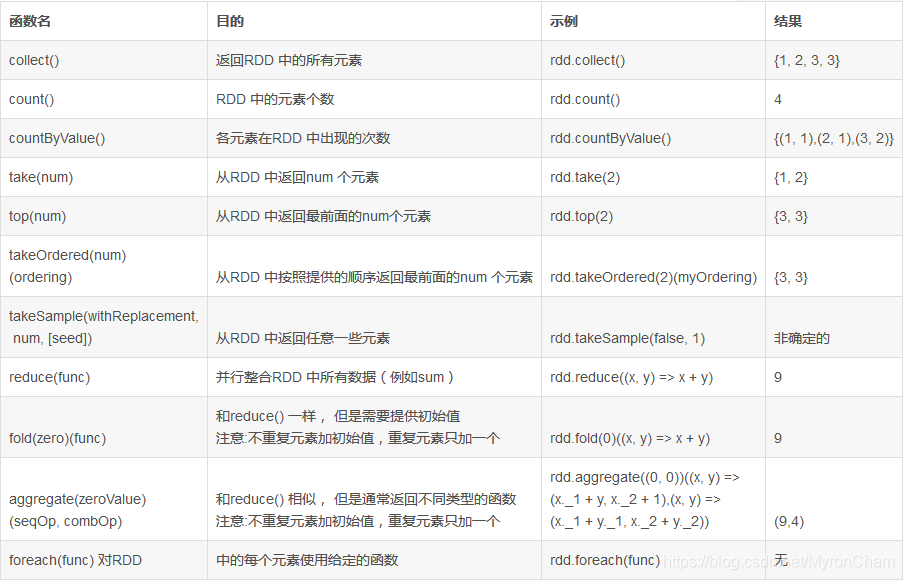
3、行动操作:
最常见的行动操作reduce()。它接收一个函数作为参数,这个函数要操作两个RDD的元素类型的数据并返回一个同样类型的新元素。
1) Java中的reduce()函数
Integer sum = rdd.reduce(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer x, Integer y) throws Exception {
return x + y;
}
});
2) Java中的aggregate()函数

表3-5-3:对数据为{1, 2, 3, 3}的RDD进行基本的RDD操作
3.5.2、在不同RDD类型间转换
在Java中,各种RDD的特殊类型间的转换更为明确。Java中有两个专门的类JavaDoubleRDD和JavaPairRDD ,来处理特殊类型的RDD。要构建出这些特殊类型的RDD,需要使用特殊版本的类来替代一般使用的Function类。如果要从T类型的RDD创建出一个DoubleRDD,我们就应当在映射操作中使用DoubleFunction<T>来替代Function<T, Double>。
此外,我们也需要调用RDD上的一些别的函数(因此不能只是创建出一个DoubleFunction然后把它传给map())。当需要一个DoubleRDD时,我们应当调用mapToDouble()来替代map()。
表3-5-4:Java中针对专门类型的函数接口
| 函数名 |
等价函数 |
用途 |
| DoubleFlatMapFunction<T> |
Function<T, Iterable<Double> |
用于flatMapToDouble,以生成DoubleRDD |
| DoubleFunction<T> |
Function<T, Double> |
用于mapToDouble,以生成DoubleRDD |
| PairFlatMapFunction<T, K, V> |
Function<T, Iterable<Tuple2<K, V>>> |
用于flatMapToPair,以生成PairRDD<K , V> |
| PairFunction<T, K, V> |
function<T, Tuple2<K, V>> |
用于mapPair,以生成PairRDD<K ,V> |
我们可以把<3.5.1中1) 使用map()计算RDD中各值的平方》修改为生成一个JavaDoubleRDD,计算RDD中每个元素的平方的示例。
用Java创建DoubleRDD:
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1,2,3,4));
JavaDoubleRDD result = rdd.mapToDouble(new DoubleFunction<Integer>(){
@Override
public double call(Integer x) throws Exception {
return (double) x * x;
}
});
System.out.println("每个元素平方后的值:" + StringUtils.join(result.collect(),",")); //1.0,4.0,9.0,16.0
System.out.println("每个元素平方后的平均值:" + result.mean()); // 7.5
3.6、持久化(缓存)
3.6.1、SparkRDD持久化特点
Spark最重要的一个功能,就是在不同操作间,持久化(或缓存)一个数据集在内存中。当你持久化一个RDD,每一个结点都将把它的计算分块结果保存在内存中,并在对此数据集(或者衍生出的数据集)进行的其它动作中重用。这将使得后续的动作(action)变得更加迅速(通常快10倍)。缓存是用Spark构建迭代算法的关键。RDD的缓存能够在第一次计算完成后,将计算结果保存到内存、本地文件系统或者Tachyon(分布式内存文件系统)中。通过缓存,Spark避免了RDD上的重复计算,能够极大地提升计算速度。
SparkRDD是惰性求值的,而有时需要多次使用同一个RDD。为了避免多次计算同一个RDD,可以让Spark对数据进行持久化。当我们让Spark持久化存储一个RDD时,计算出RDD的节点会分别保存他们所求出的分区数据。如果有一个持久化数据的节点故障,Spark会在需要用到缓存的数据时重新计算丢失的数据分区。
3.6.2、如何持久化
Spark通过persist()或cache()方法可以标记一个要被持久化的RDD,一旦首次被触发,该RDD将会被保留在计算节点的内存中并重用。实际上cache()是使用persist()的快捷方法。
首先,在action中计算得到rdd;然后,将其保存在每个节点的内存中。Spark的缓存是一个容错的技术,如果RDD的任何一个分区丢失,它可以通过原有的转换(transformations)操作自动的重复计算并且创建出这个分区。
此外,我们可以利用不同的存储级别存储每一个被持久化的RDD。例如,它允许我们持久化集合到磁盘上、将集合作为序列化的Java对象持久化到内存中、在节点间复制集合或者存储集合到Tachyon中。我们可以通过传递一个StorageLevel对象给persist()方法设置这些存储级别。cache()方法使用了默认的存储级别—StorageLevel.MEMORY_ONLY。完整的存储级别介绍如下图。

——持久化数据级别
StorageLevel 源码:
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
说明:上面"_2"代表的是份数,就是把持久化的数据存为2份。
StorageLevel有五个属性分别是:
private var _useDisk: Boolean, //useDisk_是否使用磁盘
private var _useMemory: Boolean, //useMemory_是否使用内存
private var _useOffHeap: Boolean, //useOffHeap_是否使用堆外内存如:Tachyon,
private var _deserialized: Boolean,//deserialized_是否进行反序列化
private var _replication: Int = 1) //replication_备份数目。
Spark也会自动持久化(用户没有主动调用persist)一些Shuffle过程中的中间数据,这样做是为了避免在Shuffle期间节点失败后重新计算整个输入。所以建议调用persist,如果需要重用RDD的结果。
3.6.3、存储级别的选择
Spark的存储级别旨在提供内存使用和CPU效率之间的不同权衡,因此建议通过以下过程来选择一个:
- 如果你的RDDs适合默认的存储级别,则不用管。这是CPU效率最高的选项,允许RDD上的操作尽可能快地运行;
- 如果不适合默认的存储级别,那么尝试使用MEMORY_ONLY_SER并选择一个快速的序列化库来使对象更加节省空间,但仍然能够快速访问。
- 尽量不要溢出数据到磁盘,除非对数据集计算的消耗非常大,或者对数据集进行了大规模的过滤。否则,重新计算分区就可能与从磁盘读取分区一样快了。
- 如果想要快速故障恢复,则使用副本存储级别。所有的存储级别都通过重新计算丢失的数据来提供完整的容错能力,但是副本存储级别让你可以继续在RDD上运行任务,而不用等待重新计算丢失的分区。
如下图:

注意只能设置一种:不然会抛异常: Cannot change storage level of an RDD after it was already assigned a level
3.6.4、存储级别的选择
1、调用rdd.persist();变量可以这样设置 如:rdd.persist(StorageLevel.MEMORY_ONLY); 这里使用了MEMORY_ONLY级别存储。当然也可以选择其他的如: rdd.persist(StorageLevel.DISK_ONLY());
2、调用rdd.cache()方法,cache()是rdd.persist(StorageLevel.MEMORY_ONLY)的简写,效果和他一模一样的。
3、调用rdd.unpersist()清除缓存
Demo:
public class SparkCacheDemo {
private static JavaSparkContext sc;
public static void main(String[] args) {
List list = Arrays.asList(5, 4, 3, 2, 1, 6, 9);
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("SparkCacheDemo");
sc = new JavaSparkContext(conf);
JavaRDD rdd = sc.parallelize(list);
// rdd.persist(StorageLevel.DISK_ONLY()); //磁盘存储
rdd.persist(StorageLevel.MEMORY_ONLY());//内存
// rdd.persist(StorageLevel.MEMORY_ONLY_2()); //内存存储两份
rdd.collect();
rdd.collect(); //这里可以设置debug断点便于查看
rdd.unpersist(); //清除缓存
rdd.collect(); //这里也可以设置debug断点便于查看
}
}
启动后设置上面连个debug点 然后查看页面 http://127.0.0.1:4040/storage/ 可以看到相关信息 如下图:
磁盘:

内存:

3.6.5、移除数据
Spark会自动监控每个节点的缓存使用,并使用LRU(least-recently-used)策略删除旧的分区数据。也可以使用rdd.unpersist()来手动移除数据。