参考文献:Lin K, Lu J, Chen C S, et al. Learning compact binary descriptors with unsupervised deep neural networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 1183-1192.
参考博客:https://blog.csdn.net/qq_32417287/article/details/80216891
这篇文章主要提出了一种新的损失函数,用无监督的方法学习网络权重,最终得到每幅图像的二进制描述子。这种方法不仅仅是在图像检索上,在其他任务,例如图像匹配、图像分类上也同样有效。损失函数包括三个约束:
- 二进制描述符应该与最后一个激活层的输出尽可能近,Quantization Loss Minimization
- 二进制描述符应均匀分布,Evenly Distribution
- 对旋转和噪声具有鲁棒性,Rotation Invariant
1、Introduction
一个好的特征描述子应该具备的特性:高质量特征表示、低计算开销,要能够找到图像中的可以用于区分的信息,并且对于图像的旋转变换要有鲁棒性。如果用于移动设备,还需要考虑计算的实时性。
CNN、SIFT等描述子能够学习得到更为深层的信息,更具有区分性,缩小了像素层次和语义层次的差距,但是特征描述子常常维度很高,需要的计算开销较大。
几个为了减小计算开销的二值描述子:BRIEF , ORB , BRISK , and FREAK,通过这些描述子可以使用汉明距离计算不同图像之间的相似度,但是对于尺度、旋转、噪声敏感。也有一些方法对其进行了改进,但是都是基于成对的相似标签(pair-wised similarity labels),也就是说训练数据必须要有标签。
所以,本文提出了无监督的方法,DeepBit。
2、Related Work
二进制描述符:
早期:BRIEF , ORB , BRISK , and FREAK,对尺度和几何变换敏感。
改进:D-BRIEF等。

缺点:都是基于成对的标签,并且不支持将这些二值描述子迁移到另外的任务上。
无监督的方法:
LSH、SH、SpeH、ITQ
缺点:这些无监督的方法的得到的二值码的准确度与实值得到准确度有一定差距。
深度学习:
获得很大的成功,很多方法通过利用中间层的图像表示( mid-level image representation )获得较好的效果。有人通过预训练的CNN以及深度迁移学习提升了比如图像检测、图像分割、图像检索的效果。
3、Approach
本文提出的方法DeepBit利用了从ImageNet上预训练的中间层的图像表示( mid-level image representation )并且无监督学习到了二值描述子。
之前的一些方式使用手工(hand-crafted)特征以及成对的相似信息来优化损失函数,DeepBit使用一系列的非线性损失函数计算二值描述子,以三个损失的结合为目标函数,使用随机梯度下降优化目标函数,本文提出的方法不需要有标签的训练数据。(无监督)
3.1 整体架构
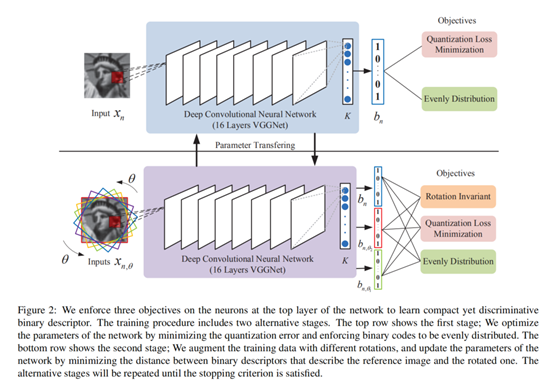
- 二进制描述符应该与最后一个激活层的输出尽可能近,Quantization Loss Minimization
- 二进制描述符应均匀分布,Evenly Distribution
- 对旋转和噪声具有鲁棒性,Rotation Invariant
$b$代表输出的二进制编码,$x$代表输入图像。
$b=0.5\times (sign(F(x;W))+1)$
$sign(k)=\left\{\begin{matrix}
1, & k>0\\
-1, & otherwise
\end{matrix}\right.$
$F(x;W)$是图像经过一系列卷积池化层的输出:$F(x;W)=f_{k}(...f_{2}(f_{1}(x;w_{1});w_{2})...;w_{k})$。
deepbit的目的是通过设计一个新的损失函数,无监督学习权重矩阵,得到图像的二进制描述子。
损失函数:

3.2 Learning Discriminative Binary Descriptors
二进制描述符应该与最后一个激活层的输出尽可能近。

3.3 Learning Efficient Binary Descriptors
通过使每个比特具有1或0的的概率都是50%来增强二进制描述符的表达能力。
$\underset{w}{min}L(w)=\sum_{m=1}^{M}\left | u_{m}-0.5 \right |^{2}$
$\forall m\in 1,...,M\quad u_{m}=\frac{1}{N}\sum_{n=1}^{N}b_{n}(m)$
$N$代表输入的数量,$m$代表比特数,所以这个约束是去所有输入的平均比特,使每一个比特位平均值靠近0.5,比特之要么是1要么是0,0.5说明0和1的概率相等,熵越大,能够表达的信息越多。
3.4 Learning Rotation Invariant Binary Descriptors
通过最小化原图像与旋转图像的距离来实现旋转不变性。estimation error 可能会随着角度增大而变得很大,所以增加了一个惩罚项$C(theta)$。$C(theta)$满足高斯分布,$u=0$,也就是说以没有旋转的时候作为原点,旋转角度越小,权重越大。We rotate the image by 10, 5, 0, -5, -10 degrees, respectively.
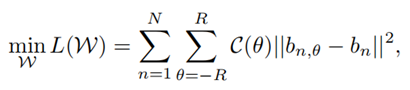
![]()
3.5 整体算法
主要步骤分为两步:
- network initialization,网络初始化
- optimization,优化
VGGNet的初始权重是在ImageNet数据集上训练的,然后我们将VGGNet的分类层替换为一个新的全连接层,并通过公式转换为二进制描述符。

4、实验结果
使用的数据集:
- Brown gray-scale patches
- CIFAR-10 color images
- Oxford 17 category flowers
我们提出的方法在各种任务上都能取得良好的成果,例如图像匹配、图像检索、图像分类等。
本文主要进行了三项实验,分别在这三个领域与相应领域最好的算法的作比较,取得了较好的成果:
- Results on Image Matching
- Results on Image Retrieval
- Results on Object Recognition