
香港理工&阿里达摩院新作,操作优雅,一行代码嵌入优化器提升性能!
ArXiv 链接:https://arxiv.org/abs/2004.01461
Github 链接:https://github.com/Yonghongwei/Gradient-Centralization
一、摘要
优化技术对有效地训练深度神经网络 (DNN) 而言具有重要意义。结果表明,利用一阶和二阶统计量 (如均值和方差) 对网络激活或权重向量 (如批标准化 (BN) 和权重标准化 (WS) ) 进行 Z-score 标准化可以提高训练性能。不同于现有的方法,本文提出了一种新的优化技术,即梯度中心化 (GC) ,它通过将梯度向量中心化为零均值,实现对梯度的直接优化。GC 可视为一种有约束损失函数的投影梯度下降法。研究结果表明,GC 能同时调整 (regularize) 权值空间和输出特征空间,提高 DNNs 的泛化性能。此外,GC 改善了损失函数的 Lipschitzness 性 (连续性?) 及其梯度,使训练过程变得更有效和稳定。GC 的实现非常简单,只需一行代码即可轻松地嵌入到现有的基于梯度的 DNN 优化器中 (如 Adam-GC、SGD-GC 等)。它也可以直接用于微调预训练 DNN。在通用图像分类、细粒度图像分类、检测和分割等应用中的实验表明,GC 能持续提升 DNN 学习性能。
二、实现
结构:
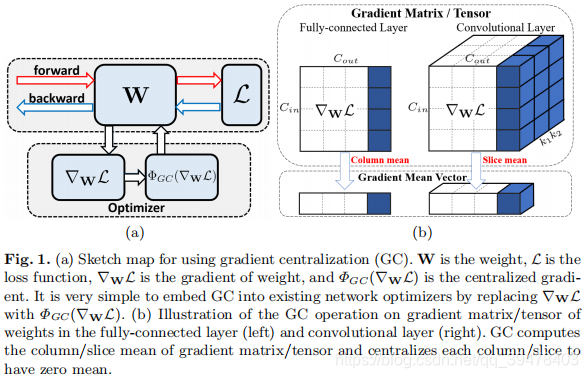
算法:

