一、Kernels I(核函数I)
在非线性函数中,假设函数为:

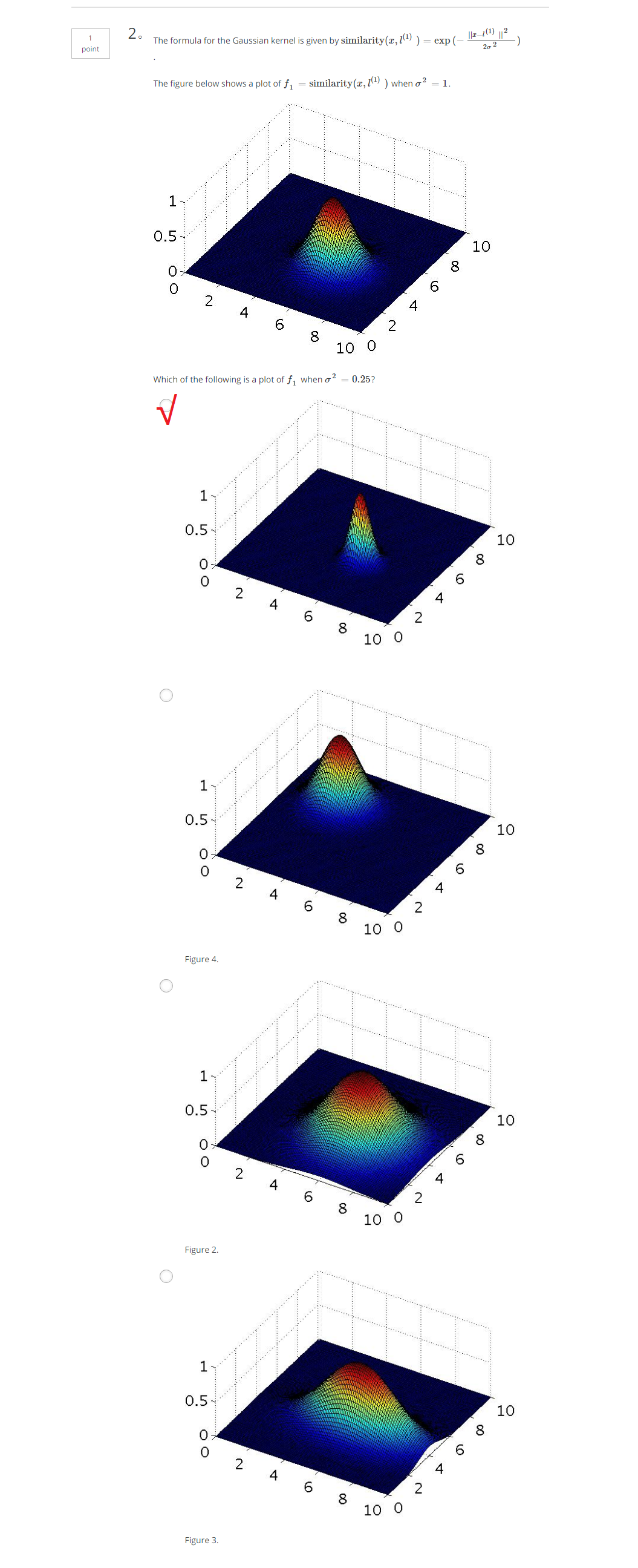
将表达式改变一下,将其写为:
联想到上次讲到的计算机视觉的例子,因为需要很多像素点,因此若f用这些高阶函数表示,则计算量将会很大,那么对于
由此引入核函数的概念。
对于给定的x,
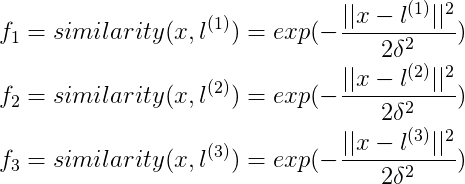
其中,similarity()函数叫做核函数(kernel function)又叫做高斯核函数,其实就是相似度函数,但是
我们平时写成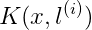
这里将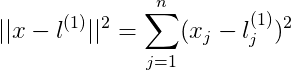
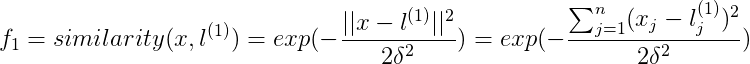
若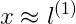
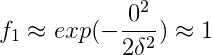
若x is far from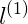
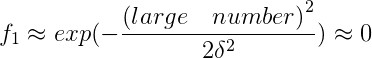
下面的图形会给出比较直观的感受:

在此基础上,看下面的例子:

对于紫色的点x,因为其距离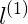
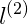
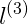
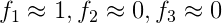
对于蓝色的点,因为其距离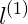
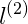
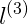

通过选取很多这样的x值,得到他们的预测值,得到边界,如图红色不规则封闭图形所示,在图形内部预测值为y=1,在图形外部的预测值y=0。
二、Kernels II(核函数II)
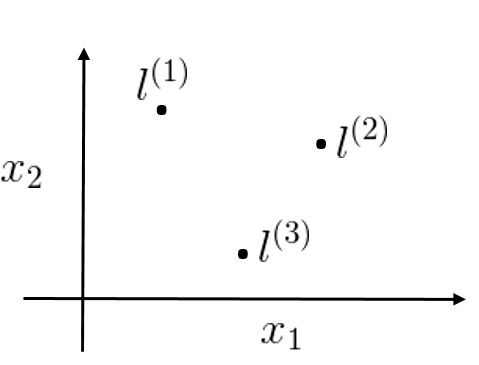
上面Kernels I内容中讲到了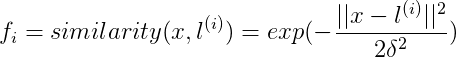


我们采取的方法是将每一个样本都作为一个标记点。
SVM with Kernels
给出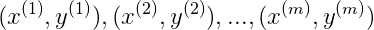
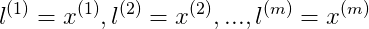
对于x,则有

有向量

其中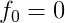
对于训练样本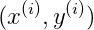
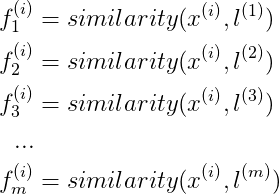
其中,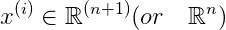
且
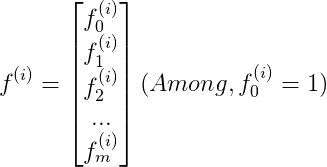
于是,假设函数变成

其中,m为训练集的大小
带核函数的代价函数为:

注意:这里我们仍然不把θ0计算在内。
最小化这个函数,即可得到支持向量机的参数。
若涉及到一些优化问题,可以选择n=m。
另外,说明:

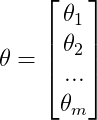
另外,在实际应用中有人将其实现为下述公式,这是另一种略有区别的距离度量方法,这种方法可以适应超大的训练集:
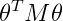
因为若使用第一种方法,当m非常大时,求解很多参数将会成本非常高。

附上一题关于f_i参数的题目: