SVM常用核函数总结

对于其中的参数,主要靠试。
国际象棋的兵王问题
数据集
UCI Machine Learning Repository
http://archive.ics.uci.edu/ml/datasets.php
训练过程
1、总样本数28056, 其中正样本2796, 负样本25260。
2、随机取5000个样本训练,其余测试。
3、样本归一化,在训练样本上,求出每个维度的均值和方差,在训练和测试样本上同时归一化。
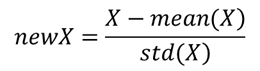
4、 高斯核 5-fold cross validation,在 CScale = [2(-5), 215]; gamma = [2(-15),23]; 上遍历求识别率的最大值。
交叉验证

上面,我们将样本分为了5分,称为5-fond,也就是训练了5个模型,每个模型的参数不一样。
那么,我们可以想象,折数越多,则训练时间越长。
对于这个问题,折数最多为5000折,称为5000-fond,也叫作留一法(leave-one-out),也就是,训练5000个模型,每个模型只留一个测试数据。
我们从识别率中,挑出最高的模型,也就得到了参数的值(c,gamma)。
训练结果
训练后获得的参数
(1)C = 16, gamma = 0.0825
(2)支持向量(即alpha不为0的向量):358个 (162个正样本,196个负样本)
根据经验,支持向量一般是总样本的20%-30%,否则要么参数设置不合适,或本问题没有明确的分类,或SVM方法不使用于此问题。
(3)b = 6.2863
对结果的分析
混淆矩阵
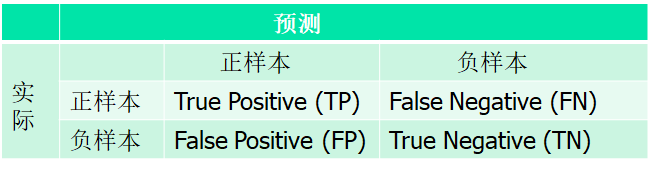
TP: 将正样本识别为正样本的数量(或概率)
FN: 将正样本识别为负样本的数量(或概率)
FP: 将负样本识别为正样本的数量(或概率)
TN: 将负样本识别为负样本的数量(或概率)
对本题中,
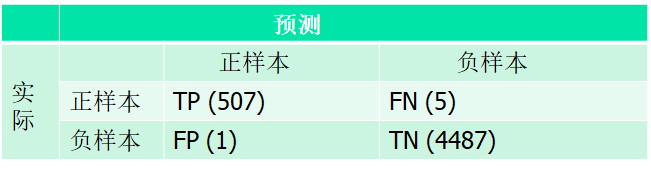

四个概率TP, FN, FP, TN的关系
(1)TP+FN=1
(2)FP+TN=1
(3)对同一个系统来说,若TP增加,则FP也增加。(好人多了,在系统识别率不变的前提下,坏人也会多)

对于一般的测试,有下式:
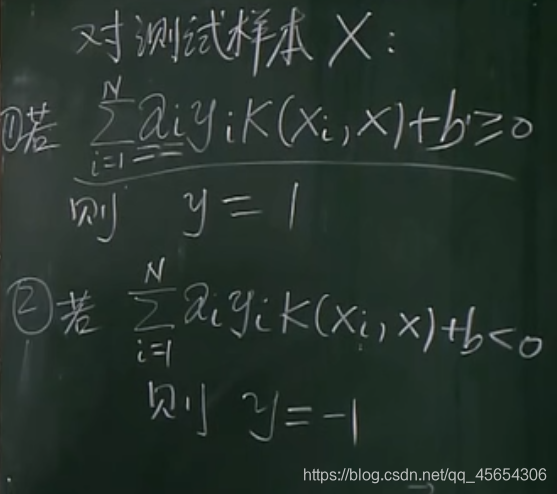
如果我们想增加TP,可以修改等号右边的阈值,而不修改模型的参数:(但与此同时,放进来的FP也会多)
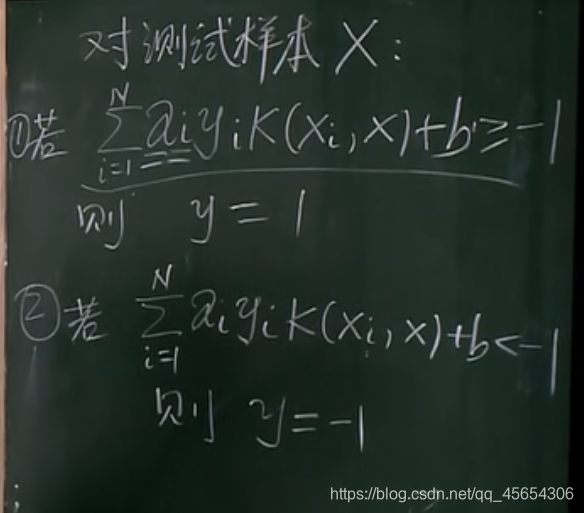
ROC曲线
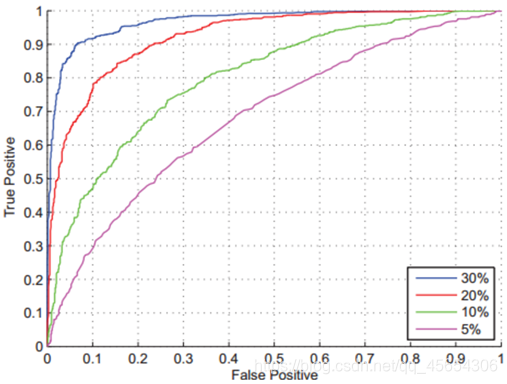
ROC (Receiver Operating Character)曲线, 是一条横坐标FP,纵坐标TP的曲线
在上图中,蓝线最好,因为当FP相同时,TP更高
对于安防领域的人脸识别系统,衡量评价一个机器学习系统的一个重要指标是FP为0时TP的最高值。
EER

等错误率 (Equal Error Rate, EER)是两类错误FP和FN相等时候的错误率,可以直观的表示系统性能。
AUC
AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。
SVM处理多类问题
SVM有三种方式处理多类问题,即类别大于2的问题:
(1)改造优化的目标函数和限制条件,使之能处理多类
(2)一类 VS 其他类
(3)一类 VS 另一类