一、Collaborative Filtering(协同过滤)
协同过滤能够自行学习所需要使用的特征。
来看下面的例子:
在之前讲的基于内容的推荐系统中,我们需要事先建立特征并知道特征值,这是比较困难的。
假设我们某一用户的喜好,即假如Alice、Bob喜欢romance的电影,carol、Dave喜欢action的电影,则:

就拿Alice来说,Alice只对romance感兴趣,因此只有x1=5,x0和x2都为0。
我们不需要在意电影的名字,只需要知道对于第一部电影,Alice和Bob都给了5分,而Alice和Bob都喜欢romance的电影,因此极有可能对于第一部电影来说,x1=1.0,x2=0
因此
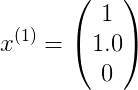
又因为对于第一部电影,4个人都给了评分,因此有下列公式:

即我们通过θ来预测x。
下面是优化目标:

我们该怎样将之前基于内容的推荐算法和本部分内容结合呢?
二、Collaborative Filtering Algorithm(协同过滤算法)
在上面提到我们可以通过不过x --> θ --> x --> θ --> x --> ....的过程来求出θ和x的最优值,这个过程比较复杂,下面有一种更简单的方法,我们可以同时求出x和θ的值:

整理一下协同过滤算法的流程:
