LR简介
逻辑斯谛回归是一种经典的线性分类方法,又被称为对数几率回归,其属于对数线性模型。
线性回归完成了数据的拟合,我们通过引入一个
sigmoid函数,即可在线性回归模型的基础上实现分类。
sigmoid函数定义如下
y=1+e−z1
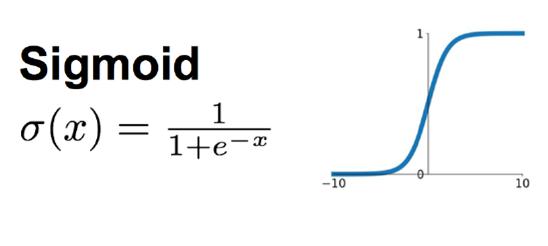
以二分类任务为例,取
y∈{0,1},我们定义二项逻辑斯谛回归模型为如下条件概率分布:
P(Y=1∣x)=1+exp(w⋅x+b)exp(w⋅x+b)P(Y=0∣x)=1+exp(w⋅x+b)1
一个事件的几率是指该事件发生的概率与不发生的概率的比值,如果事件发生的概率为
p,则该事件的几率为
1−pp,则该事件的对数几率即为:
log1−pp
考虑逻辑斯谛回归模型,
log1−P(Y=1∣x)P(Y=1∣x)=w⋅x+b
也就是说,输出
Y=1的对数几率是输入
x的线性函数。
损失函数
对于给定的训练数据集,我们采用极大似然估计法来估计模型的参数,似然函数为:
i=1∏N[P(yi=1∣xi)]yi[1−P(yi=1∣xi)]1−yi
对数似然函数为:
L(w,b)=i=1∑N[yilogP(yi=1∣xi)+(1−yi)log(1−P(yi=1∣xi))]=i=1∑N[yilog1−P(yi=1∣xi)P(yi=1∣xi)+log(1−P(yi=1∣xi))]=i=1∑N[yi(w⋅xi+b)−log(1+exp(w⋅x+b))]
然后对
L(w,b)取极大值,即可得到
w的估计值,通常情况下,我们将其转化为求解极小值问题.
L(w,b)=−i=1∑N[yi(w⋅xi+b)−log(1+exp(w⋅x+b))]
我们通常采用的方法是梯度下降法以及牛顿法.
我们用
θ来替代参数.
梯度下降法的参数更新为:
θ←θ−α∂θ∂L(θ)
牛顿法的迭代形式为:
θt+1=θt−(∂θ2∂2L(θ))−1∂θ∂L(θ)
采用向量形式表示则为:
θt+1=θt−(∂θ∂θT∂2L(θ))−1∂θ∂L(θ)
下面我们来推导关于
θ的一阶和二阶导数:
对于代价函数采取如下形式考虑,
L(θ)=−[ylogy^+(1−y)log(1−y^)]
其中,
y^=1+exp(−z)1,z=θTx.
根据链式求导法则
∂θ∂L=∂z∂L∂θ∂z
∂z∂L=∂y^∂L∂z∂y^
我们有
∂y^∂L=y^(1−y^)y^−y
∂z∂y^=(1+exp(−z)1)′=1+exp(−z)1−(1+exp(−z))21=y^(1−y^)
因此,我们得到了
∂z∂L=∂y^∂L∂z∂y^=y^−y
那么
∂θ∂L=∂z∂L∂θ∂z=(y^−y)∂θ∂z=(y^−y)x
这里均由增广表示,因此我们得到了迭代公式
θ^=θ−α∂θ∂L=θ−α(y^−y)x
二阶导数同理我们可以得到
∂θ∂θT∂2L(θ)=xxTy^(1−y^)
参考
知乎-对数几率回归
李航-统计机器学习
周志华-机器学习