逻辑回归模型
逻辑回归模型是一种分类模型,由条件概率分布P(Y|X) 表示,形式为参数化的逻辑分布,这里,随机变量X取值为实数,随机变量Y取值为1或0。
在学习逻辑回归时大家总是将线性回归作比较,线性回归模型的输出一般是连续的,
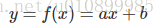
在线性回归模型中每一个输入x,都有一个对应的y输出。模型的定义域和值域都可以是[-∞, +∞]。但是逻辑回归输入可以是连续的[-∞, +∞],输出却一般是离散的,即只有有限个多个输出值。例如值域可以只有两个值{0,1},这两个值可以表示对样本的某种分类(高/低,好/坏等),这就是常见的二分类逻辑回归。因此,从整体上来说,通过LR我们可以将整个实数范围上的x映射到了有限个点上,这样就实现了对X的分类。
LR与SVM的相同点
- LR和SVM都是分类算法;
- 如果不考虑核函数,LR和SVM都是线性分类算法,也就是它们的分类决策面都是线性的;
- SVM只考虑局部的边界线附近的点,而LR考虑全局(远离的点对边界线的确定也起作用)。
影响SVM决策面的样本点只有少数的结构支持向量,当在支持向量外添加或减少任何样本点对分类决策面没有任何影响;而在LR中,每个样本点都会影响决策面的结果。
a.SVM改变非支持向量样本并不会引起决策面的变化
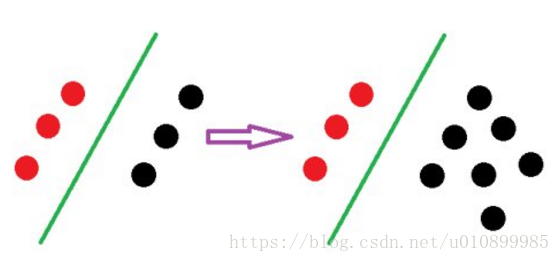
b.LR中改变任何样本都会引起决策面的变化

- LR和SVM都是监督学习。
- LR和SVM都是判别模型
判别模型会生成一个表示P(Y|X)的判别函数(或预测模型),而生成模型先计算联合概率p(Y,X)然后通过贝叶斯公式转化为条件概率。简单来说,在计算判别模型时,不会计算联合概率,而在计算生成模型时,必须先计算联合概率。
常见的判别模型有:SVM、LR,条件随机场(CRF),CART,最大熵,决策树
常见的生成模型有:朴素贝叶斯,隐马尔可夫模型,贝叶斯网络,KNN,马尔科夫随机场(MRF)
LR与SVM的不同
- 本质上是两者的损失函数的不同

SVM损失函数:
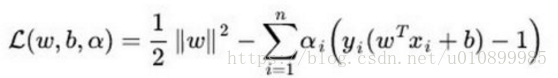
其中, m:训练样本的个数;hθ(x):用参数θ和x预测出来的y值;y:原训练样本中的y值,也就是标准答案; 上角标(i):第i个样本
- 线性SVM依赖数据表达的距离测度,所以需要对数据先做Normalization, LR不受其影响;
- 在解决非线性问题时,SVM采用核函数的机制,而LR通常不采用核函数
这个问题理解起来非常简单。分类模型的结果就是计算决策面,模型训练的过程就是决策面的计算过程。通过上面的第二点不同点可以了解,在计算决策面时,SVM算法里只有少数几个代表支持向量的样本参与了计算,也就是只有少数几个样本需要参与核计算(即kernal machine解的系数是稀疏的)。然而,LR算法里,每个样本点都必须参与决策面的计算过程,也就是说,假设我们在LR里也运用核函数的原理,那么每个样本点都必须参与核计算,这带来的计算复杂度是相当高的。所以,在具体应用时,LR很少运用核函数机制。
- SVM与LR学习算法
LR学习算法有: 改进的迭代尺度算法,梯度下降,拟牛顿法
SVM学习算法: 序列最小优化算法(SMO)
- SVM的损失函数就自带正则(损失函数中的1/2||w||^2项),这就是为什么SVM就是结构风险最小化算法的原因,而LR必须另外在损失函数上添加正则项,关于正则化可参考我的另一篇博客:https://blog.csdn.net/u010899985/article/details/79471909